方面级分类paper1 Effective LSTMs for Target-Dependent Sentiment Classification(2016COLING)
Paper link: https://arxiv.org/pdf/1512.01100v2.pdf
Code link: http://ir.hit.edu.cn/~dytang/ the homepage of author
Source: 2016COLING
Author: jasminexjf
Time: 2019-06-25
文章的任务是Target-Dependent Sentiment Classification。
一、Target-Dependent Sentiment Classification
“I bought a new camera. The picture quality is amazing but the battery life is too short”
对于不同的target: picture quality : positive battery life : negative
传统方法使用feature-based SVM,但是feature engineering is labor intensive,且难以解决稀疏、离散特征的问题
二、本文主要工作、模型
1.LSTM
不单独考虑target信息的提取,将其当成普通的情感分类,直接利用LSTM进行进行句子的向量化表示。

不加入target信息,直接使用LSTM进行句子建模的效果不佳。
2.TD-LSTM
TD-LSTM将文本以target words为中心拆分为左右两部分,左句(从左往右读入)与右句(从右往左读入)分别输入两个LSTM网络中,中心词(target string)都作为句末。最后将两者最后的time step的hidden输入concat之后进入softmax进行分类。损失函数为cross entropy loss function。

3.TC-LSTM
1))作者认为TD-LSTM还不够好,没有获取到target word和上下文之间的相互作用
2)为了模拟人类在被问及target-dependent sentiment classification问题时会在context中寻找相关词的过程
{Wl+1, Wl+2...Wr−1} 为target words,和TD-LSTM一样分别按照正向反向分别接在左句和右句的句尾。
不同的是:对当前target words的vectors(与文本的word embedding属于同一空间域)取均值得到![]() 用来表示这个target实体,将
用来表示这个target实体,将![]() 与句中所有word embedding(包括target words)concat,作者认为此法可以在target和每个文本内的词之间建立更好的联系.
与句中所有word embedding(包括target words)concat,作者认为此法可以在target和每个文本内的词之间建立更好的联系.

交叉熵损失函数定义:
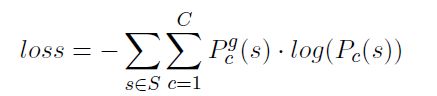
![]() is the probability of predicting s as class c given by the sof tmax layer,
is the probability of predicting s as class c given by the sof tmax layer,![]() indicates whether class c is the correct sentiment category, whose value is 1 or 0, is ont-hot vector.
indicates whether class c is the correct sentiment category, whose value is 1 or 0, is ont-hot vector.
三、实验
3.1 Dataset:
benchmark dataset (Dong et al., 2014)
positive, negative and neutral in training and test sets are both 25%, 25%, 50%
3.2 results

3.3 不同的预训练word embedding对于训练结果的影响
sentiment-specific word embedding(![]() ,
, ![]() and
and ![]() are different embedding learning algorithms)
are different embedding learning algorithms)
![]() and
and ![]() learn word embeddings by only using sentiment of sentences
learn word embeddings by only using sentiment of sentences
![]() takes into account of sentiment of sentences and contexts of words simultaneously
takes into account of sentiment of sentences and contexts of words simultaneously
此外,维度越高的Glove词向量效果越佳,50-100维提升最明显

3.4 训练时间花费(每轮迭代耗时):TC-LSTM耗时更久,而效果提升小

根据以上利用不同维度的词向量进行嵌入的时间消耗对比,100dim的TD-LSTM的效果提升更大,时间消耗也不是很大,很适合用于实际落地应用中。
3.5 实验分析

文中谈到:TD-LSTM与TC-LSTM的85.4%的错误分类都是与neutral类别有关,正负类别则很少出错。
四、conclusions
We develop target-specific long short term memory models for target-dependent sentiment classification. The approach captures the connection between target word and its contexts when generating the representation of a sentence. We train the model in an end-to-end way on a benchmark dataset, and show that incorporating target information could boost the performance of a long short-term memory model. The target-dependent LSTM model obtains state-of-the-art classification accuracy.
我们开发了特定于目标的长期短期记忆模型,用于目标相关的情绪分类。该方法在生成句子的表示形式时捕获目标单词及其上下文之间的连接。我们在基准数据集上以端到端方式对模型进行了培训,并证明了合并目标信息可以提高长短期内存模型的性能。目标相关的LSTM模型获得了最先进的分类精度。