On the Strength of Sequence Labeling and Generative Modelsfor Aspect Sentiment Triplet Extraction
On the Strength of Sequence Labeling and Generative Modelsfor Aspect Sentiment Triplet Extraction (2023 ACL )
依赖序列标注和生成方面模型情感三元组提取研究
论文地址: https://aclanthology.org/2023.findings-acl.762.pdf
代码地址: https://github.com/NLPWM-WHU/SLGM
1. 介绍(摘要)
生成模型在方面情感三元组抽取任务中取得了很大的成功。
然而,现有的方法忽略了方面词和意见词之间的相互信息线索,可能会产生错误的三元组对。此外,生成模型固有的局限性,即逐个标记的解码和简单的结构化提示,使得模型无法处理复杂的结构,特别是多个单词跨度的术语和多个三元组的句子。
为了解决这些问题,我们提出了一个序列标记增强生成模型。
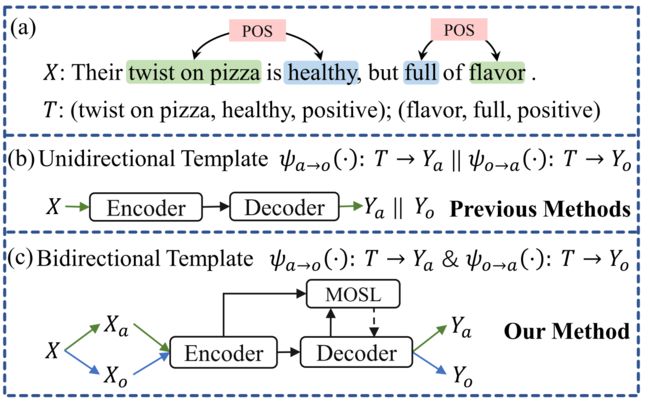
首先,我们将aspect和opinion之间的依赖关系编码到两个双向模板中,以避免错误配对的三元组。
其次,我们引入了一个面向标记的序列标记模块,以提高生成模型处理复杂结构的能力。
具体来说,这个模块使生成模型能够捕获方面/观点范围的边界信息,并提供使用共享标记解码多个三元组的提示。
在四个数据集上的实验结果证明,我们的模型产生了一个新的先进的性能。我们的代码和数据可以在https://github.com/NLPWM-WHU/SLGM上找到。
1.1 科学问题
现有的方法忽略了方面词和意见词之间的相互信息线索,可能会产生错误的三元组对。
此外,生成模型固有的局限性,即逐个标记的解码和简单的结构化提示,使得模型无法处理复杂的结构,特别是多个单词跨度的术语和多个三元组的句子。
1.2 方法
首先,我们将aspect和opinion之间的依赖关系编码到两个双向模板中,以避免错误配对的三元组。
其次,我们引入了一个面向标记的序列标记模块,以提高生成模型处理复杂结构的能力。
具体来说,这个模块使生成模型能够捕获方面/观点范围的边界信息,并提供使用共享标记解码多个三元组的提示。
1.3 创新点/贡献
- 我们设计了两个具有不同解码顺序的双向模板,以同时捕获方面和意见术语之间的相互依赖性。特别地,我们在输入句子之前添加两种类型的提示前缀以指示解码顺序,并且我们还提出了两个输出模板 ψ a → o ψa→o ψa→o和 ψ o → a ψo→a ψo→a,它们都由标记 { a s p e c t , o p i n i o n , s e n t i m e n t } \{aspect,opinion,sentiment\} {aspect,opinion,sentiment}和相应的标签 { a , o , s } \{a,o,s\} {a,o,s}组成。
- 我们提出了一个面向标记的序列标记 M O S L MOSL MOSL 模块,它可以提高生成模型的能力,以处理复杂的结构。
- 我们在四个数据集上进行了广泛的实验,包括全监督和低资源设置。结果表明,我们的模型显着优于国家的最先进的ASTE任务的基线。
2. 任务案例
ASTE任务案例
3. 模型架构

SLGM 任务架构
4. 方法
4.1 方法定义
给定具有L个词的评论句子X,ASTE的目标是提取X中的所有三元组 T = { ( a , o , s ) } i = 1 N T = \{(a,o,s)\}^N_{i =1} T={(a,o,s)}i=1N,其中N是三元组的数量,并且 a a a、 o o o和 s s s分别表示方面术语、观点术语和情感极性。
(1) 为了捕获方面和意见术语之间的互信息,我们在输入和输出端构建了两个双向模板,如图中的 X a X_a Xa/ X o X_o Xo和 ψ a → o ψa→o ψa→o| ψ o → a ψo→a ψo→a所示。
(2) 为了处理复杂的结构,我们提出了一个面向标记的序列标记(MOSL)模块来捕获多字方面/意见术语的边界信息和多个三联体的共享标记信息。
4.2 双向模板
对于输入评论 X X X,我们通过添加两种类型的提示前缀,即" a p s e c t f i r s t : apsect \; first: apsectfirst:"和" o p i n i o n f i r s t opinion \; first opinionfirst:"来构造两个句子 X a X_a Xa和 X o X_o Xo。当我们用这些模板对模型进行微调时,这样的前缀可以提示模型生成具有特定解码顺序的目标序列。
为了以生成方式获得输出三元组 T T T,必要的步骤是在训练期间将三元组 T T T线性化为目标序列 Y Y Y,并且在推断期间从预测序列中解线性化三元组。特别是,一个好的输出模板应该:
1)确保线性化的靶序列可以容易地去线性化为三元组的集合,
2)包含特定标记以促进标记的解码过程,
3)自由改变标记的顺序。基于上述考虑,我们提出了两个基于标记的模板 ψ a − o ψa-o ψa−o和ψ o − a o-a o−a,它们在方面和观点术语之间具有不同的解码顺序,如下所示:
ψ a → o → a s p e c t : a , o p i n i o n : o , s e n t i m e n t : s ψ_{a→o} → aspect : a, \; opinion : o, \; sentiment : s ψa→o→aspect:a,opinion:o,sentiment:s
ψ o → a → o p i n i o n : o , a s p e c t : a , s e n t i m e n t : s ψ_{o→a} → opinion : o, \; aspect : a, \; sentiment : s ψo→a→opinion:o,aspect:a,sentiment:s
我们的输出模板由两部分组成:标记 { a s p e c t , o p i n i o n , s e n t i m e n t } \{aspect,opinion,sentiment\} {aspect,opinion,sentiment}和对应的标签 { a , o , s } \{a,o,s\} {a,o,s}。标记可以引导模型在下一步骤生成特定类型的标记。当输入审查包含几个三元组时,我们需要对三元组的顺序进行排序,以确保目标序列的唯一性。对于模板 ψ a → o ψa→o ψa→o,我们按照方面术语的结束索引按升序对三元组进行排序。如果一些三元组共享相同的方面术语,我们进一步按照意见术语的结束索引对它们进行排序。在获得三元组的文本片段后,我们使用特殊符号[SSEP]连接这些片段以形成最终的目标序列。
4.3 模板引导的文本生成
为了简单起见,我们以句子 X a X_a Xa和基于模板 ψ a − o ψa-o ψa−o的对应目标序列 Y a Ya Ya作为示例进行说明。我们首先将 X a X_a Xa输入到 T r a n s f o r m e r Transformer Transformer编码器中,以获得上下文特征 H e n c H^{enc} Henc:( T 5 b a s e T5_{base} T5base模型)
H e n c = E n c o d e r ( X a ) H^{enc} = Encoder(X_a) Henc=Encoder(Xa)
然后,我们使用Transformer解码器来生成目标序列 Y a Ya Ya。在第 t t t个时间步,解码器将基于上下文特征 H e n c H^{enc} Henc和先前解码的令牌 y [ 1 : t − 1 ] y_{[1:t-1]} y[1:t−1]来计算解码器隐藏状态 h t h_t ht。
h t = D e c o d e r ( y [ 1 : t − 1 ] , H e n c ) h^t = Decoder(y_{[1:t−1]},H^{enc}) ht=Decoder(y[1:t−1],Henc)
接下来,用 h t h_t ht计算令牌 y t y_t yt的条件概率:
p ( y t ∣ H e n c ; y [ 1 : t − 1 ] ) = s o f t m a x ( W T h t ) p(y_t|H^{enc}; y_{[1:t−1]}) = softmax(W^Th_t) p(yt∣Henc;y[1:t−1])=softmax(WTht)
其中W是变换矩阵。最后,我们计算解码器输出与目标序列Ya之间的交叉熵损失La→o g:
L g a → o = ∑ i = 1 L l o g p ( y t ∣ H e n c ; Y [ 1 : t − 1 ] ) L^{a\rightarrow o}_g= \sum_{i=1}^{L} log \; p(y_t|H^{enc};Y_{[1:t−1]}) Lga→o=i=1∑Llogp(yt∣Henc;Y[1:t−1])
4.4 面向标记的序列标记(MOSL)

在 M O S L MOSL MOSL中,我们将通过序列标记来标记方面和意见术语。我们首先用两个线性变换从上下文特征 H e n c H^{enc} Henc中提取方面特征 H a = { h 1 a , h 2 a , ⋅ ⋅ ⋅ , h L a } ∈ R L × d H^a = \{h^a_1, h^a_2,···,h^a_L\} ∈ R^{L×d} Ha={h1a,h2a,⋅⋅⋅,hLa}∈RL×d(L为句子长度)和意见特征 H a = { h 1 o , h 2 o , ⋅ ⋅ ⋅ , h L o } ∈ R L × d H^a = \{h^o_1, h^o_2,···,h^o_L\} ∈ R^{L×d} Ha={h1o,h2o,⋅⋅⋅,hLo}∈RL×d :
H a = M L P a ( H e n c ) , H o = M L P o ( H e n c ) H^a = MLP_a(H^{enc}), H^o = MLP_o(H^{enc}) Ha=MLPa(Henc),Ho=MLPo(Henc)
将标记对应的解码器的最后一个隐藏状态作为标记特征,包括方面标记特征 M a = { M 1 a , M 2 a , ⋅ ⋅ ⋅ , M N a } M^a = \{M^a_1, M^a_2,···,M^a_N\} Ma={M1a,M2a,⋅⋅⋅,MNa} (N为三元组个数)和意见标记特征 M a = { M 1 o , M 2 o , ⋅ ⋅ ⋅ , M N o } M^a = \{M^o_1, M^o_2,···,M^o_N\} Ma={M1o,M2o,⋅⋅⋅,MNo}。然后我们计算用于序列标记的 m i a ∈ M a m^a_i∈M^a mia∈Ma或 m i o ∈ M o m^o_ i∈M^o mio∈Mo的面向标记的特征:
q i j a = σ ( W 1 ( h j a ⊕ m i a ) + b 1 ) q^a_{ij} = σ(W_1(h^a_j ⊕m^a_i ) + b_1) qija=σ(W1(hja⊕mia)+b1)
q i j o = σ ( W 1 ( h j o ⊕ m i o ) + b 1 ) q^o_{ij} = σ(W_1(h^o_j ⊕m^o_i ) + b_1) qijo=σ(W1(hjo⊕mio)+b1)
其中σ(·)是selu激活函数, h j a ∈ H a h^a_j ∈H^a hja∈Ha, h j o ∈ H o h^o_j∈H^o hjo∈Ho是 a s p e c t / o p i n i o n aspect/opinion aspect/opinion特征。 W W W和 b b b是变换矩阵和偏差。当输入的句子包含多个三元组时,不同位置的方面/意见标记特征对应不同的标记, Y i m a = { y i 1 m a , y i 2 m a , ⋅ ⋅ ⋅ , y i L m a } Y^{ma}_{i} = \{y^{ma}_{i1}, y^{ma}_{i2},···,y^{ma}_{iL}\} Yima={yi1ma,yi2ma,⋅⋅⋅,yiLma}表示 Y m a Y^{ma} Yma, Y i m o = { Y i 1 m o , Y i 2 m o , ⋅ ⋅ ⋅ , Y i L m o } Y^{mo}_i = \{Y^{mo}_{i1}, Y^{mo}_{i2},···,Y^{mo}_{iL}\} Yimo={Yi1mo,Yi2mo,⋅⋅⋅,YiLmo}表示 Y m o Y^{mo} Ymo,其中 Y m a Y^{ma} Yma和 Y m o Y^{mo} Ymo为序列标记中的BIO标签。我们将面向标记的特征输入到一个全连接层中,以预测方面/意见术语的标签,并得到标签集上的预测概率:
p i j m a = s o f t m a x ( W 2 q i j a + b 2 ) p^{ma}_{ij} = softmax(W_2q^a_{ij} + b_2) pijma=softmax(W2qija+b2)
p i j m o = s o f t m a x ( W 2 q i j o + b 2 ) p^{mo}_{ij} = softmax(W_2q^o_{ij} + b_2) pijmo=softmax(W2qijo+b2)
MOSL的训练损失定义为交叉熵损失:
式中,I(·)为指示函数, y i j m a y^{ma}_{ij} yijma和 y i j m o y^{mo}_{ij} yijmo为ground真值标签,C为 { B , I , O } \{B, I, O\} {B,I,O}标签集。
4.5 推理过程
在推理过程中,我们采用了一种约束解码(CD)策略来保证内容和格式的合法性,这是受到Bao等人(2022)的启发; Lu等人(2021)。内容合法性是指方面/意见词在输入句中必须是一个单字或多个连续字,表达的情绪必须是积极的、中性的或消极的。格式合法性意味着生成的序列应该满足模板中定义的格式要求。
利用约束译码策略在 X a X_a Xa和 X o X_o Xo两个输入句子的基础上生成了 Y a Y_a Ya和 Y o Y_o Yo两个序列。然后根据定义的模板 ψ a → o ψ_{a→o} ψa→o和 ψ o → a ψ_{o→a} ψo→a将它们解线性为两个三元组 T a T_a Ta和 T o T_o To。我们以 T a T_a Ta与 T o T_o To的交集作为最终的预测结果。
5 训练目标(损失函数)
为了更好的理解双向依赖关系,也为了更少的空间开销,我们共同优化了句子和标签对 ( X , T ) (X, T) (X,T)的两个双向模板:
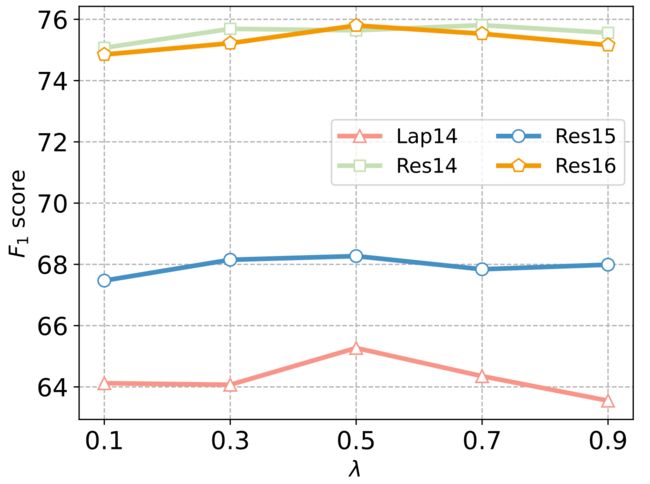
L = λ ( L g a → o + L m a → o ) + ( 1 − λ ) ( L g o → a + L m o → a ) L = λ(L^{a→o}_g + L^{a→o}_m) +(1−λ)(L^{o→a}_g + L^{o→a}_m) L=λ(Lga→o+Lma→o)+(1−λ)(Lgo→a+Lmo→a)
6. 实验结果
6.1 对比实验
监督设置的结果。‡的基线结果来自Yan等人(2021);Xu等人(2021);陈等(2022)。我们用“†”通过使用它们发布的代码来重现生成方法。最好的和第二好的F1成绩分别用粗体和下划线表示。∗标记表示与SSI+SEL的第二佳结果相比,p < 0.01有统计学意义的改善。

6.2 消融实验
- 双向模板的影响。表示不同解码顺序的预测结果。

- 在监督下的消融研究结果。

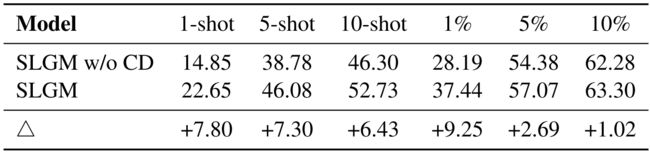
- 在Res16数据集上,低资源设置的受限解码(CD)消融研究的结果。
- 在不同的λ设置下F1分数变化。