聪哥哥教你学Python之函数式编程
今天主要围绕这么几个方面谈谈函数式编程?
1.高阶函数
2.返回函数
3.匿名函数
4.装饰器
5.偏函数
有人会有疑问,聪哥哥请问什么是函数式编程?
引用百度百科的话说:
函数式编程是一种编程方式,它将电脑运算视为函数的计算。函数编程语言最重要的基础是λ(中文发音,兰亩达)演算(lambda calculus),而且λ演算的函数可以接受函数当作输入(参数)和输出(返回值)。
和指令式编程相比,函数式编程强调函数的计算比指令的执行重要。
和过程化编程相比,函数式编程里函数的计算可随时调用。
引用廖雪峰先生的话说:
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
而函数式编程(请注意多了一个“式”字)——Functional Programming,虽然也可以归结到面向过程的程序设计,但其思想更接近数学计算。
我们首先要搞明白计算机(Computer)和计算(Compute)的概念。
在计算机的层次上,CPU执行的是加减乘除的指令代码,以及各种条件判断和跳转指令,所以,汇编语言是最贴近计算机的语言。
而计算则指数学意义上的计算,越是抽象的计算,离计算机硬件越远。
对应到编程语言,就是越低级的语言,越贴近计算机,抽象程度低,执行效率高,比如C语言;越高级的语言,越贴近计算,抽象程度高,执行效率低,比如Lisp语言。
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
百度百科的话有点笼统,廖雪峰先生说的挺不错的。聪哥哥就不班门弄斧了。
下面进入正题:
一、高阶函数
高阶函数包含map/reduce、filter、sorted等。
1.map/reduce
map/reduce
阅读: 434814
Python内建了map()和reduce()函数。
如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Processing on Large Clusters”,你就能大概明白map/reduce的概念。
我们先看map。map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
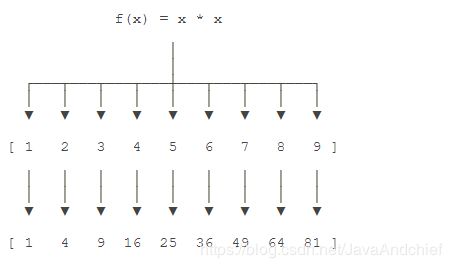
示例一:
# -*- coding: utf-8 -*-
def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
print(list(r))2.filter
Python内建的filter()函数用于过滤序列。
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
示例二:
# -*- coding: utf-8 -*-
def is_odd(n):
return n % 2 == 1
print(list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15])))
把一个序列中的空字符串删掉,可以这么写:
示例三:
# -*- coding: utf-8 -*-
def not_empty(s):
return s and s.strip()
print(list(filter(not_empty, ['A', '', 'B', None, 'C', ' '])))
聪哥哥有话说:filter()的作用是从一个序列中筛出符合条件的元素。由于filter()使用了惰性计算,所以只有在取filter()结果的时候,才会真正筛选并每次返回下一个筛出的元素。
接下来或许有朋友会提出问题,什么是惰性计算?
引用百度百科:
惰性计算(Lazy Evaluation),又称懒惰计算、懒汉计算,是一个计算机编程中的一个概念,它的目的是要最小化计算机要做的工作。
它有两个相关而又有区别的含意,可以表示为“延迟计算”和“短路求值”。除可以得到性能的提升外,惰性计算的最重要的好处是它可以构造一个无限的数据类型。
惰性计算的相反是热情计算,也叫做严格计算。这是一个大多数编程语言所拥有的普通计算方式。
3.sorted
排序也是在程序中经常用到的算法。无论使用冒泡排序还是快速排序,排序的核心是比较两个元素的大小。如果是数字,我们可以直接比较,但如果是字符串或者两个dict呢?直接比较数学上的大小是没有意义的,因此,比较的过程必须通过函数抽象出来。
Python内置的sorted()函数就可以对list进行排序:
示例四:
# -*- coding: utf-8 -*-
print(sorted([36, 5, -12, 9, -21]))
二、返回函数
返回函数又分两个,一个函数作为返回值,一个是闭包(闭包在前端领域比较流行)
1.函数作为返回值
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
我们来实现一个可变参数的求和。通常情况下,求和的函数是这样定义的:
示例五:
def calc_sum(*args):
ax = 0
for n in args:
ax = ax + n
return ax但是,如果不需要立刻求和,而是在后面的代码中,根据需要再计算怎么办?可以不返回求和的结果,而是返回求和的函数:
示例六:
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum当我们调用lazy_sum()时,返回的并不是求和结果,而是求和函数:
![]()
这个例子中,我们在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
2.闭包
注意到返回的函数在其定义内部引用了局部变量args,所以,当一个函数返回了一个函数后,其内部的局部变量还被新函数引用,所以,闭包用起来简单,实现起来可不容易。
另一个需要注意的问题是,返回的函数并没有立刻执行,而是直到调用了f()才执行。我们来看一个例子:
示例七:
# -*- coding: utf-8 -*-
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
print(f1())
print(f2())
print(f3())在上面的例子中,每次循环,都创建了一个新的函数,然后,把创建的3个函数都返回了。
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果是:

如果一定要引用循环变量怎么办?方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变:
示例八:
# -*- coding: utf-8 -*-
def count():
def f(j):
def g():
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f()
return fs
f1, f2, f3 = count()
print(f1())
print(f2())
print(f3())结果如图:

闭包的缺点在于:代码较长,不过可利用lambda函数缩短代码。
聪哥哥怎么看?
(1)一个函数可以返回一个计算结果,也可以返回一个函数;
(2)返回一个函数时,牢记该函数并未执行,返回函数中不要引用任何可能会变化的变量。
三、匿名函数
当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算f(x)=x2时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
示例九:
# -*- coding: utf-8 -*-
print(list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9])))关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数。
聪哥哥有话说:Python对匿名函数的支持有限,只有一些简单的情况下可以使用匿名函数。
四、装饰器
在Java中有一个设计模式叫装饰器模式。下面聪哥哥我借此分享下关于装饰器的知识
装饰器模式定义:
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装。
这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。
我们通过下面的实例来演示装饰器模式的用法。其中,我们将把一个形状装饰上不同的颜色,同时又不改变形状类。
介绍:
意图:动态地给一个对象添加一些额外的职责。就增加功能来说,装饰器模式相比生成子类更为灵活。
主要解决:一般的,我们为了扩展一个类经常使用继承方式实现,由于继承为类引入静态特征,并且随着扩展功能的增多,子类会很膨胀。
何时使用:在不想增加很多子类的情况下扩展类。
如何解决:将具体功能职责划分,同时继承装饰者模式。
关键代码: 1、Component 类充当抽象角色,不应该具体实现。 2、修饰类引用和继承 Component 类,具体扩展类重写父类方法。
应用实例: 1、孙悟空有 72 变,当他变成"庙宇"后,他的根本还是一只猴子,但是他又有了庙宇的功能。 2、不论一幅画有没有画框都可以挂在墙上,但是通常都是有画框的,并且实际上是画框被挂在墙上。在挂在墙上之前,画可以被蒙上玻璃,装到框子里;这时画、玻璃和画框形成了一个物体。
优点:装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能。
缺点:多层装饰比较复杂。
使用场景: 1、扩展一个类的功能。 2、动态增加功能,动态撤销。
注意事项:可代替继承。
Python也是面向对象编程,后面也会有类的实例、继承、多态等等之类的概念,后续会讲解。
示例十:
# -*- coding: utf-8 -*-
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
print(log)聪哥哥怎么看?
在面向对象(OOP)的设计模式中,decorator被称为装饰模式。OOP的装饰模式需要通过继承和组合来实现,而Python除了能支持OOP的decorator外,直接从语法层次支持decorator。Python的decorator可以用函数实现,也可以用类实现。decorator可以增强函数的功能,定义起来虽然有点复杂,但使用起来非常灵活和方便。
五、偏函数
Python的functools模块提供了很多有用的功能,其中一个就是偏函数(Partial function)。要注意,这里的偏函数和数学意义上的偏函数不一样。
在介绍函数参数的时候,我们讲到,通过设定参数的默认值,可以降低函数调用的难度。而偏函数也可以做到这一点。
例如:
int()函数可以把字符串转换为整数,当仅传入字符串时,int()函数默认按十进制转换:
# -*- coding: utf-8 -*-
import functools
int2 = functools.partial(int, base=2)
print(int2('1000000'))聪哥哥有话说:当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单。
小结:
其实聪哥哥我对于上述部分内容也不是特别理解,其实也不明白,但是学习这东西不能仅仅因为暂时不明白某个地方,而停滞。
这就好像开发的过程中,产品那边提出某个问题,那个问题,即属于业务逻辑方面,又属于技术方面的,那个任务属于紧急但不重要的评级。这时可以放放,因为当某个时候,突然大脑灵光闪现,就会顿时明白知道怎么解决,我们将这个东西称之为灵感。