HFile存储格式
Table of Contents
- HFile存储格式
-
- Block块结构
HFile存储格式
HFile是参照谷歌的SSTable存储格式进行设计的,所有的数据记录都是通过它来完成持久化,其内部主要采用分块的方式进行存储,如图所示:
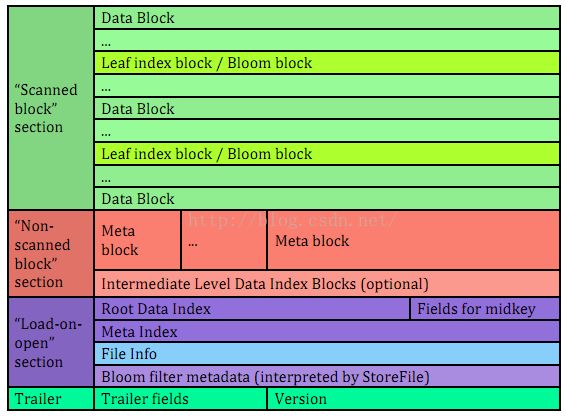
每个HFile内部包含多种不同类型的块结构,这些块结构从逻辑上来讲可归并为两类,分别用于数据存储和数据索引(简称数据块和索引块),其中数据块包括:
(1) DATA_BLOCK:存储表格数据
(2) BLOOM_CHUNK:存储布隆过滤器的位数组信息
(3) META_BLOCK:存储元数据信息
(4) FILE_INFO:存储HFile文件信息
索引块包括:
表格数据索引块(ROOT_INDEX、INTERMEDIATE_INDEX、LEAF_INDEX)
在早期的HFile版本中(version-1),表格数据是采用单层索引结构进行存储的,这样当数据量上升到一定规模时,索引数据便会消耗大量内存,导致的结果是Region加载效率低下(A region is not considered opened until all of its block index data is loaded)。
因此在version-2版本中,索引数据采用多层结构进行存储,加载HFile时只将根索引(ROOT_INDEX)数据载入内存,中间索引(INTERMEDIATE_INDEX)和叶子索引(LEAF_INDEX)在读取数据时按需加载,从而提高了Region的加载效率。
元数据索引块(META_INDEX)
新版本的元数据索引依然是单层结构,通过它来获取元数据块信息。
布隆索引信息块(BLOOM_META)
通过索引信息来遍历要检索的数据记录是通过哪一个BLOOM_CHUNK进行映射处理的。
从存储的角度来看,这些数据块会划分到不同的区域进行存储。
Trailer区域
该区域位于文件的最底部,HFile主要通过它来实现相关数据的定位功能,因此需要最先加载,其数据内容是采用protobuf进行序列化处理的,protocol声明如下:
message FileTrailerProto { optional uint64 file_info_offset = 1; optional uint64 load_on_open_data_offset = 2; optional uint64 uncompressed_data_index_size = 3; optional uint64 total_uncompressed_bytes = 4; optional uint32 data_index_count = 5; optional uint32 meta_index_count = 6; optional uint64 entry_count = 7; optional uint32 num_data_index_levels = 8; optional uint64 first_data_block_offset = 9; optional uint64 last_data_block_offset = 10; optional string comparator_class_name = 11; optional uint32 compression_codec = 12; optional bytes encryption_key = 13; }
FileInfo数据块在HFile中的偏移量信息;
Load-on-open区域在HFile中的偏移量信息;

所有表格索引块在压缩前的总大小;

所有表格数据块在压缩前的总大小;

根索引块中包含的索引实体个数;

元数据索引块中包含的索引实体个数;
文件所包含的KeyValue总数;

表格数据的索引层级数;

第一个表格数据块在HFile中的偏移量信息;
最后一个表格数据块在HFile中的偏移量信息;
在代码层面上Trailer是通过FixedFileTrailer类来封装的,可通过其readFromStream方法用来读取指定HFile的Trailer信息。
Load-on-open区域
HFile被加载之后,位于该区域中的数据将会被载入内存,该区域的起始位置通过Trailer来定位(通过其load_on_open_data_offset属性)。从该位置起依次保存的数据信息为:根索引快、元数据索引块、文件信息块以及布隆索引块。
Scanned-Block区域
在执行HFile顺序扫描时,位于该区域中的所有块信息都需要被加载,包括:表格数据块、布隆数据块和叶子索引块(后两者称之为InlineBlock)。
Non-Scanned-Block区域
在执行HFile顺序扫描时,位于该区域中的存储块可不被加载,包括:元数据块和中间索引块。
Block块结构
每个Block块是由3部分信息组成的,分别是:header信息、data信息以及用于data校验的checksum信息。不同类型的block只是在data信息的存储结构上存在差异,而header信息和checksum信息存储结构基本一致。
header主要用于存储每个Block块的元数据信息
这些信息包括:
(1)blockType:块类型,HFile一共对外声明了10种不同类型的Block,分别是:DATA(表格数据块)、META(元数据块)、BLOOM_CHUNK(布隆数据块)、FILE_INFO(文件信息块)、TRAILER、LEAF_INDEX(叶子索引块)、INTERMEDIATE_INDEX(中间索引块)、ROOT_INDEX(根索引快)、BLOOM_META(布隆索引块)、和META_INDEX(元数据索引块);
(2)onDiskSizeWithoutHeader:data信息与checksum信息所占用的磁盘空间大小;
(3)onDiskDataSizeWithHeader:data信息与header信息所占用的磁盘空间大小;
(4)uncompressedSizeWithoutHeader:每个block块在完成解压缩之后的大小(不包括header和checksum占用的空间);
(5)prevBlockOffset:距离上一个同类型block块的存储偏移量大小。
在v2版本中,header的长度为固定的33字节。
data主要用于封装每个block块的核心数据内容
如果是根索引块其数据内容如下:

主要包含多条索引实体信息(索引实体的个数记录在Trailer中)以及midKey相关信息,其中每条索引实体信息是由3部分数据组成的,分别为:
(1)Offset:索引指向的Block块在文件中的偏移量位置;
(2)DataSize:索引指向的Block块所占用的磁盘空间大小(在HFile中的长度);
(3)Key:如果索引指向的是表格数据块(DATA_BLOCK),该值为目标数据块中第一条数据记录的rowkey值(0.95版本之前是这样的,之后的版本参考HBASE-7845);如果索引指向的是其他索引块,该值为目标索引块中第一条索引实体的blockKey值。
而midKey信息主要用于定位HFile的中间位置,以便于对该HFile执行split拆分处理,其数据内容同样由3部分信息组成,分别为:
(1)midLeafBlockOffset:midKey所属叶子索引块在HFile中的偏移量位置;
(2)midLeafBlockOnDiskSize:midKey所属叶子索引块的大小(在HFile中的长度);
(3)midKeyEntry:midKey在其所属索引块中的偏移量位置。
如果是非根索引块其数据内容如下:

同样包含多条索引实体信息,但不包含midKey信息。除此之外还包含了索引实体的数量信息以及每条索引实体相对于首个索引实体的偏移量位置。
如果是表格数据块其数据内容为多条KeyValue记录,每条KeyValue的存储结构可参考Memstore组件实现章节。
如果是元数据索引块其数据内容同叶子索引块类似,只不过索引实体引向的是META数据块。
如果是布隆数据块其数据内容为布隆过滤器的位数组信息。
如果是布隆索引块其数据内容如下:

同其他索引块类似,包含多条索引实体信息,每条索引实体引向布隆数据块(BLOOM_CHUNK)。除此之外还包含与布隆过滤器相关的元数据信息,包括:
(1)version:布隆过滤器版本,在新版本HBase中布隆过滤器通过CompoundBloomFilter类来实现,其对应的版本号为3;
(2)totalByteSize:所有布隆数据块占用的磁盘空间总大小;
(3)hashCount:元素映射过程中所使用的hash函数个数;
(4)hashType:元素映射过程中所采用的hash函数类型(通过hbase.hash.type属性进行声明);
(5)totalKeyCount:所有布隆数据块中已映射的元素数量;
(6)totalMaxKeys:在满足指定误报率的情况下(默认为百分之一),所有布隆数据块能够映射的元素总量;
(7)numChunks:目前已有布隆数据块的数量;
(8)comparator:所映射元素的排序比较类,默认为org.apache.hadoop.hbase.KeyValue.RawBytesComparator
如果是文件信息块其数据内容采用protobuf进行序列化,相关protocol声明如下:
message FileInfoProto { repeated BytesBytesPair map_entry = 1; // Map of name/values }
checksum信息用于校验data数据是否正确
块信息读取
数据块的读取操作主要是通过FSReader类的readBlockData方法来实现的,在执行数据读取操作之前,需要首先知道目标数据块在HFile中的偏移量位置,有一些数据块的偏移量信息是可通过Trailer进行定位的,如:
根索引块(ROOT_INDEX)的偏移量信息可通过Trailer的load_on_open_data_offset属性来定位,在知道了根索引块的存储信息之后,便可通过它来定位所有DATA_BLOCK在HFile中的偏移量位置;
首个DATA_BLOCK的偏移量信息可通过Trailer的first_data_block_offset属性来定位。
在不知道目标数据块大小的情况下需要对HFile执行两次查询才能读取到最终想要的HFileBlock数据。第一次查询主要是为了读取目标Block的header信息,由于header具有固定的长度(HFileV2版本为33字节),因此在知道目标Block的偏移量之后,便可通过读取指定长度的数据来将header获取。
获取到header之后便可通过其onDiskSizeWithoutHeader属性来得知目标数据块的总大小。
totalSize = headerSize + onDiskSizeWithoutHeader
然后再次从Block的偏移量处读取长度为totalSize字节的数据,以此来构造完整的HFileBlock实体。
由以上逻辑来看,如果在读取数据块之前,能够事先知道该数据块的大小,那么便可省去header的查询过程,从而有效降低IO次数。为此,HBase采用的做法是在读取指定Block数据的同时,将下一个Block的header也一并读取出来(通过读取totalSize + headerSize长度的数据),并通过ThreadLocal将该header进行缓存。这样如果当前线程所访问的数据是通过两个连续的Block进行存储的,那么针对第二个Block的访问只需执行一次IO即可。
获取到HFileBlock实体之后,可通过其getByteStream方法来获取内部数据的输入流信息,在根据不同的块类型来选择相应的API进行信息读取:
(1)如果block为根索引块,其信息内容可通过BlockIndexReader进行读取,通过其readMultiLevelIndexRoot方法;
(2)如果为元数据索引块,同样采用BlockIndexReader进行读取,通过其readRootIndex方法;
(3)如果为非根索引块,可通过BlockIndexReader的locateNonRootIndexEntry方法来将数据指针定位到目标block的索引位置上,从而对目标block的偏移量、大小进行读取;
(4)如果为文件信息块,通过FileInfo类的read方法进行读取;
(5)如果为布隆索引块,通过HFile.Reader实体的getGeneralBloomFilterMetadata方法进行读取;
(6)如果为布隆数据块,通过该HFileBlock实体的getBufferWithoutHeader方法来获取布隆数据块的位数组信息(参考CompoundBloomFilter类的实现)。
块数据生成
Block数据在写入HFile之前是暂存于内存中的,通过字节数组进行存储,当其数据量大小达到指定阀值之后,在开始向HFile进行写入。写入成功后,需要再次开启一个全新的Block来接收新的数据记录,该逻辑通过HFileBlock.Writer类的startWriting方法来封装,方法执行后,会首先开启ByteArrayOutputStream输出流实例,然后在将其包装成DataOutputStream对象,用于向目标字节数组写入要添加的Block实体信息。
在HFile.Writer内部,不同类型的数据块是通过不同的Writer进行写入的,其内部封装了3种不同类型的子Writer(这些Writer共用一个FSDataOutputStream用于向HFile写入Block数据),分别如下:
HFileBlock.Writer
通过该Writer完成表格数据块(DataBlock)向HFile的写入逻辑,大致流程如下:
每当执行HFile.Writer类的append方法进行添加数据时,会检测当前DataBlock的大小是否已经超过目标阀值,如果没有,直接将数据写入DataBlock,否则需要进行如下处理:
将当前DataBlock持久化写入HFile
写入之前需要首先生成目标数据块的header和checksum信息,其中checksum信息可通过ChecksumUtil的generateChecksums方法进行获取,而header信息可通过putHeader方法来生成。
生成当前DataBlock的索引信息
索引信息是由索引key,数据块在HFile中的偏移量位置和数据块的总大小3部分信息组成的,其中索引key可通过CellComparator.getMidpoint方法进行获取,方法会试图返回一条数据记录能够满足如下约束条件:
(1)索引key在排序上大于上一个DataBlock的最后一条记录;
(2)索引key在排序上小于当前DataBlock的第一条记录;
(3)索引key的size是最小的。
经过这样处理之后能够整体降低索引块的数据量大小,从而节省了内存空间的使用,并提高了加载效率。
将索引信息写入索引块
通过HFileBlockIndex.BlockIndexWriter的addEntry方法。
判断是否有必要将InlineBlock进行持久化
InlineBlock包括叶子索引块和布隆数据块,它们的持久化逻辑分别通过BlockIndexWriter和CompoundBloomFilterWriter来完成。
开启新的DataBlock进行数据写入,同时将老的数据块退役
如果集群开启了hbase.rs.cacheblocksonwrite配置,需要将老数据块缓存至BlockCache中。
HFileBlockIndex.BlockIndexWriter
通过该Writer完成索引数据块(IndexBlock)向HFile的写入逻辑。
在HFile内部,索引数据是分层级进行存储的,包括根索引块、中间索引块和叶子索引块。其中叶子索引块又称之为InlineBlock,因为它会穿插在DataBlock之间进行存储。同DataBlock类似,IndexBlock一开始也是缓存在内存里的,每当DataBlock写入HFile之后,都会向当前叶子索引块添加一条索引实体信息。如果叶子索引块的大小超过hfile.index.block.max.size限制,便开始向HFile进行写入。写入格式为:索引实体个数、每条索引实体相对于块起始位置的偏移量信息,以及每条索引实体的详细信息(参考Block块结构)。
这主要是叶子索引块的写入逻辑,而根索引块和中间索引块的写入则主要在HFile.Writer关闭的时候进行,通过BlockIndexWriter的writeIndexBlocks方法。
在HFile内部,每一个索引块是通过BlockIndexChunk对象进行封装的,其对内声明了如下数据结构:
(1)blockKeys,封装每一条索引所指向的Block中第一条记录的key值;
(2)blockOffsets,封装每一条索引所指向的Block在HFile中的偏移量位置;
(3)onDiskDataSizes,封装每一条索引所指向的Block在HFile中的长度。
除此之外,根索引块还比较特殊,其对内声明了numSubEntriesAt集合,集合类型为List
,每当有叶子索引块写入HFile之后都会向该集合添加一条实体信息,实体的index为当前叶子索引块的个数,value为索引实体总数。这样,通过numSubEntriesAt集合便能确定midKey(中间索引)处在哪个叶子索引块上,在通过blockKeys、blockOffsets和onDiskDataSizes便能够获取最后的midkey信息。然后将其作为根索引块的一部分写入HFile,并通过FixedFileTrailer来标记根索引块的写入位置。 需要注意的是根索引块的大小也是受上限约束的,如果其大小大于hfile.index.block.max.size参数阀值(默认为128kb),需要将其拆分成多个中间索引块,然后在对这些中间索引块创建根索引,以此来降低根索引块的大小,具体逻辑可参考BlockIndexWriter类的writeIntermediateLevel方法实现。
CompoundBloomFilterWriter
通过该Writer完成布隆数据向HFile的写入逻辑。
布隆数据在HFile内部同样是分块进行存储的,每一个数据块通过ByteBloomFilter类来封装,负责存储指定区间的数据集映射信息(参考布隆过滤器实现章节)。
每当执行HFile.Writer的append方法向DataBlock添加KeyValue数据之前,都要调用ByteBloomFilter的add方法来生成该KeyValue的布隆映射信息,为了满足目标容错率,每个ByteBloomFilter实体能够映射的KeyValue数量是受上限约束的,如果达到目标上限值需要将其持久化到HFile中进行存储,然后开启新的ByteBloomFilter实例来接管之前的逻辑。
每当布隆数据块写入成功之后,都会执行BlockIndexWriter的addEntry方法来创建一条布隆索引实体,实体的key值为布隆数据块所映射的第一条KeyValue的key值。
同叶子索引块一样,布隆数据块也被称之为InlineBlock,在写入DataBlock的同时会对该类型的数据块进行穿插写入。这主要是布隆数据块的写入逻辑,而布隆索引块主要是在HFile.Writer关闭的时候进行创建的,通过CompoundBloomFilterWriter.MetaWriter的write方法,将布隆索引数据连同meta信息一同写入HFile。