微服务架构适用场景分析
核心要点
- 微服务并不是什么灵丹妙言,在现代架构中,它有自己的位置,但并不适用于任何的地方;
- 在判断基于微服务的方案是否适合时,理解业务域是至关重要的;
- 单职责原则是划分微服务边界的关键;
- 与其他架构风格类似,微服务是由一系列的原则来监管的;
- 微服务必须在更广阔的分布式架构和分布式计算上下文中进行考量。
在本文中,我们将会深入研究主数据管理(Master Data Management,MDM)场景中微服务架构的适用情况,并且会分析在问题域中,如果需要计算密集型的任务,基于微服务的架构所面临的挑战,比如在计算无担保消费信贷组合的预期损失的时候。
我们首先会介绍业务架构的元模型,并使用模型的元素及其关联关系定义业务域和问题域。然后我们采用领域驱动设计的方式去理解复杂的业务域,并帮助我们创建技术解决方案。
随后,我们将会引入微服务这种新的架构范式,对其进行剖析并简单阐述其优势和不足。我们还会分析使用微服务来实现MDM Data Hub的适用情况。
最后,我们会讨论针对大容量数据的计算密集型任务时,基于微服务的架构所面临的局限性,探讨这种架构风格是否适用于这种类型的应用。
业务架构元模型
图1引入了一个简化的业务架构元模型,在本文中,我们都会使用这些元素来定义业务域。元模型包含了五个元素,我们对这些构建块提供了简洁的定义。
(点击放大图像)
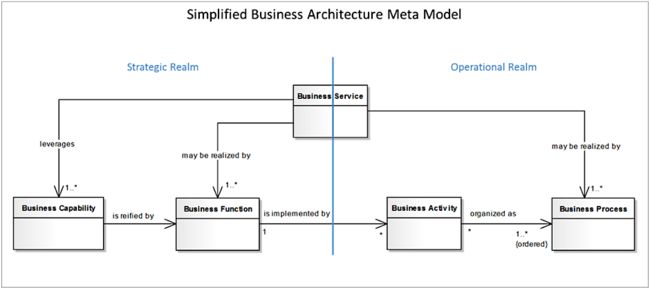
图1:简化的业务架构元模型
业务服务(Business Service)会暴露满足客户业务需求的一些功能,不管这些客户是组织内部的还是外部的。业务能力(Business Capabilities)表明组织要做些什么事情来达成其业务目标,它并不反映该如何做。它们是业务架构的顶层元素,属于战略业务域,并且由组织的业务原则来监管。通常来讲,会使用一个或多个业务能力来实现一个或一组业务服务。业务能力要通过多个业务功能(Business Function)来具体化实现,业务功能又通过多个业务活动(Business Activities)来实现。业务活动会被组织成业务过程(Business Processes)。业务功能定义为一个业务行为元素,该元素会基于给定的标准(一般是所需的业务资源和/或权限)对行为进行分组。业务能力包含一个或多个业务功能。简化起见,业务过程定义为一个行为元素,它会基于排序的活动对行为进行分组。这样的话,就能生成一组定义好的产品或业务服务。最后,业务活动代表了在业务过程中要完成的工作。(业务活动可能是原子的,也可能是复合的,但是它们之间的差异并不会影响我们目前讨论的话题。)
业务能力、功能、过程和活动是由组织中的一个或多个角色(也就是某个人或团队)来执行的。
与建筑行业不同,软件开发的方法论依然还处于非常模糊的状态。在过去的20年间,涌现出很多的方法论,首先是瀑布式的方法,然后敏捷方法,比如SCRUM,还有敏捷相关的方法,比如极限编程(Extreme Programming,XP)以及统一软件开发过程(Rational Unified Process,RUP)。
领域驱动设计(Domain-Driven Design,DDD)是软件行业最新的方法论,它所设计的软件与问题域的概念模型是匹配的。换句话说,领域驱动设计倡导基于实际业务的具体用例进行建模。按照最简单的形式,DDD会将业务域解耦为更小的功能块,要么在业务功能级别,要么在业务过程级别,这样的话,复杂的业务或问题域就能更容易地理解并通过技术手段来解决。为了展现其效果,我们使用图2阐述之前提到的业务架构元模型中的各个元素是如何进行协作并组成两个业务域的。
因为面向服务架构(Service Oriented architecture,SOA)的很多文档化实现遭到了失败,或者只是这种架构的自然演化,在最近的几年间出现了一种新的架构风格。尽管植根于SOA,但是它集成了一项很重要的面向对象设计原则。这种新的架构风格以单职责原则(Single Responsibility Principle,SRP)为核心,倡导将多个独立的服务应用组合起来,并且借助限界上下文(bounded context)使这些服务应用从一开始就能独立进行开发。DDD构件代表了一个或多个业务能力的逻辑子集,能够从给定角色的角度提供业务价值。逻辑子集的边界进而会定义业务上下文,角色会被限制在这个上下文中进行操作,如图2所示。这种架构风格的名称就是微服务。

图2:领域驱动设计与微服务的概念视图
来自ThoughtWorks的James Lewis和Martin Fowler是这样来定义微服务的:“简而言之,微服务架构风格会将一个应用开发为一系列小的服务,每个服务运行在自己的进程中,彼此之间通过轻量级的机制实现通信,通常会是HTTP资源API。这些服务是围绕业务能力构建的,并且能够通过自动化的部署机制独立部署。其中,会有一个最小化的中心管理机制,管理这些服务,这些服务可能会使用不同的编程语言编写并使用不同的存储技术”。微服务的这个定义非常重要,因为它识别出了一些重要的原则(tenets),本文稍后会用到这些原则进行判断。图3剖析了微服务,并在此基础上试图可视化这些基础原则。
(点击放大图像)
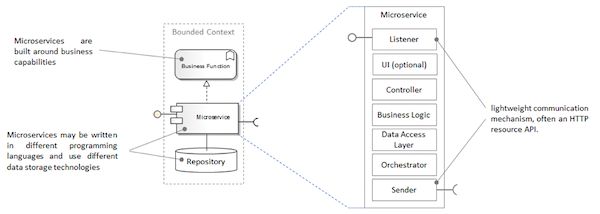
图3:微服务剖析
为了阐述领域驱动设计和基于微服务的架构,我们以交易成本分析(Transaction Cost Analysis,TCA)的场景作为样例。图4描述了一个典型的交易时间线,展现了这种分析通常会在何处进行。
资产管理公司可能会有最佳的投资模型,但如果金融工具不采取实际交易的话,那它们就毫无价值。任何资产组合的总业绩都会受到标的资产类别的选择和分配、实施质量以及其他关键维度的影响。实际上,通过购买和销售金融工具来实现投资组合时,它的成本通常会降低投资组合的回报。
(点击放大图像)
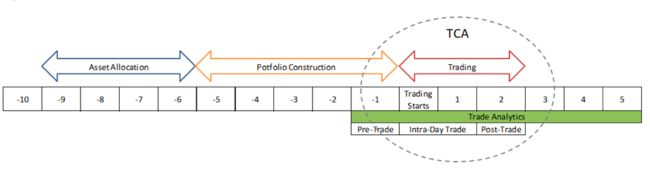
图4:交易的时间线
投资组合的实施成本能够将高质量的投资变成中等收益的投资,或者将低质量的投资变得无利可图。因此,投资经理必须要主动地管理交易成本,因为更低的交易成本就意味着更高的投资回报。通过为投资策略和交易业绩提供更高的透明度,TCA能够帮助投资经理降低交易成本并确定其投资组合交易的有效性。
因此,使用我们前面提到的业务架构元模型,按照最简单形式,TCA可以建模为一个业务能力,它由三个业务功能具体实现,如图5所示。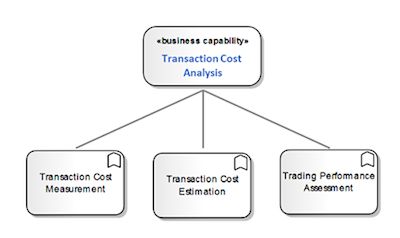
图5:交易成本分析——简化的业务模型
交易成本度量(Transaction Cost Measurement)业务功能通常会受到显式和隐式成本的影响,如下表所示。

表1
关于显式成本和隐式成本的介绍表明交易成本度量这个业务功能至少可以进一步分解为两个子域:显式交易成本度量(Explicit Transaction Cost Measurement)和隐式交易成本度量(Implicit Transaction Cost Measurement)。为了简单起见,我们省略了其他业务功能的DDD分解。
图6为显式交易成本度量和隐式成本度量这两个业务功能建立了基本的context map。Eric Evans在其关于DDD的重要著作中指出,Context Map是明确上下文边界的主要工具,它在限界上下文和业务领域的角度展现了微服务。在TCA样例中,针对每个子业务领域,识别出了五个可能的微服务。
(点击放大图像)
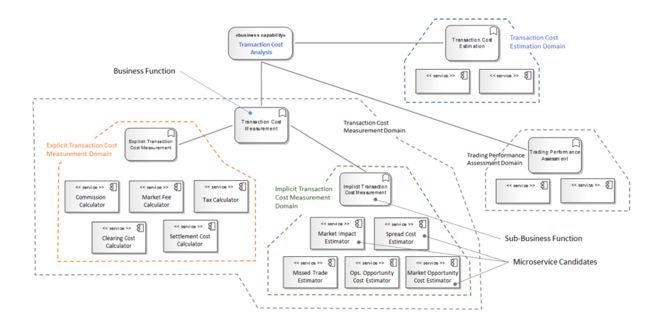
图6:针对交易成本分析的简化Context Map
基于微服务的架构提供了很多的优势。这种范式所引入的模块化能够提升开发的便利性和开发速度,从而匹配业务的节奏。更新某个子集的功能也会非常容易,因为它只位于一个或几个软件之中。微服务的模块化特性还会增强安全性并隔离故障。如果给定的一组代码被损坏或出现问题,它能够与其他的服务完全隔离,从而避免整个应用出现不可用的状况。
但是,微服务也有不少的缺点,编排(orchestration)就是其中很主要的一个样例。大量微服务的协作可能是很有挑战性的,如果每个微服务只对自己的交互负责的话,那么更会如此。数据存储是可能面临困难的另外一个方面。因为每个微服务负责自己的持久化,所以在由多个微服务组成的应用中,非常有可能出现数据冗余的情况,这会影响到主数据管理(Master Data Management)传统的操作方式。微服务会影响到的另外一个领域就是报告。除此之外,微服务的划分还会让集成测试变成一个很困难的问题。这些收益和缺点并非详尽无遗的,我只是使用它们来完成关于微服务的概要介绍。
本文剩余的部分将会引入两个特定的主题域,探讨这种新的范式是否适用。这也是微服务架构第一次在主数据管理的场景下进行充分性检验。它的适用性在计算密集型的任务中会面临一些挑战,比如总损失的分布计算。
主数据管理是一个很宽泛的领域,有个简短的定义能够让我们快速对其达成共识。主数据管理是一个进程和技术的框架,致力于创建和维护权威的、可靠的、可持续的、准确的和安全的数据环境,这个环境代表了现实情况的一个单一、全面的版本,用于主数据及其关联关系。主数据指的是对企业、关键业务过程以及应用系统至关重要的实体、关联关系以及属性。客户信息、州、邮政编码、货币符号(Currency Symbol)或安全收报机(Security Ticker)都是这样的实体。
在功能上来讲,MDM需要通过清理、充实和丢弃冗余数据来对主实体进行主动管理,如下面的用例图所示。
(点击放大图像)
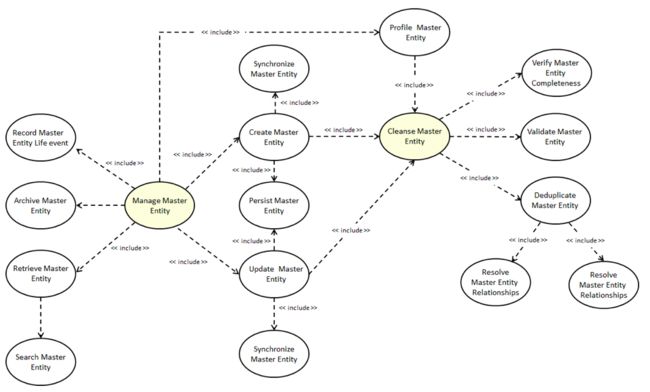
图7:MDM用例图——简化的视图
多年以来,MDM的技术实现在持续进步,以便于更好地解决该领域的企业级需求。这种演进以引入新的架构范式为特点,其目的是满足MDM技术解决方案在演进性、可维护性、可扩展性以及性能方面的要求。
图8以可视化的方式追溯了MDM Data Hubs的架构演化过程,从客户端-服务器应用开始,直到可能基于微服务的架构实现。在接下来的几个章节中,我们将会回顾一下如何借助单体架构以及传统的SOA架构实现Master Data Hub的方案。随后,我们会将基于微服务的架构作为一个可能的架构替代方案。
(点击放大图像)

图8:MDM Data Hub——架构演化
在分布式架构尤其是面向服务的架构出现之前,主数据管理通常会作为单体应用的一部分来实现。MDM的功能以及关联的逻辑会与应用本身所解决的特定业务域或问题域的功能关联到一起。同样,MDM数据的持久化也会与系统的事务化域(transactional domain)关联在一起,如图9所示。例如,在客户端-服务器交易应用中,不管是用PowerBuilder 6还是Visual Basic 6编写的,通常都会将主数据关联的实体比如Customer、State Code或Security放到用于存储单个事务的底层数据库中。

图9:单体/客户端-服务器MDM Data Hub架构
在这种方式下,MDM和事务性数据在物理上非常接近,所以几乎没有延迟,但是从架构的角度来看,MDM和业务特定功能的耦合将会引入架构的刚性,阻碍每个功能区域的独立演化。另外,在企业级来说,这种架构范式通常会造成功能和数据的重复,如图10所示。

图10
采用分布式架构,尤其是SOA,能够将MDM相关的功能和持久化与领域相关的实现解耦(关注点分离的原则,Separation of Concern),如图11所示。不管MDM的架构风格是什么(Repository、Registry或其他),这种分离都会增加架构的灵活性,允许每个域解决方案进行独立地演化以满足各自的功能需求。但是,直到NoSQL数据库出现之前,MDM数据的持久化依然是使用关系型数据库,因为当时并没有合适的替代方案。
(点击放大图像)
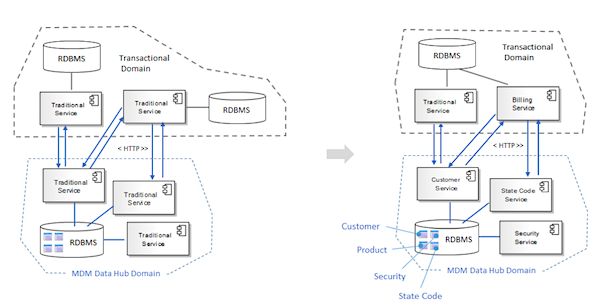
图11:传统的SOA MDM Data Hub架构——Registry风格
从数据架构的角度来看,很多的MDM Data Hub实现使用了Master-Slave构造或它的变种,比如sharding。在Master-Slave方式中,会有很多的服务器处理读取请求,但是只有一个(在sharding场景下会有几个)服务器实际执行写入操作,这样的话,就能维护主数据的一致性状态,如图12所示。
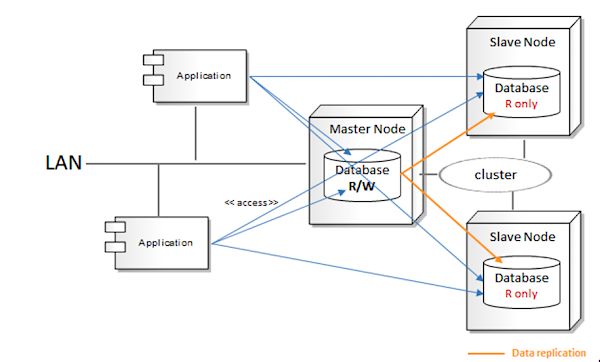
图12:Master-Slave架构
这种架构通常会引入单点故障,可能会限制高可用性以及无缝水平扩展的能力。因此,在实现MDM Data Hub解决方案时,数据架构是需要考虑的一个重要方面。随着NoSQL数据库的出现,这一点变得尤为重要,因为这些数据库提供了存储主数据的可靠替代方案,在与微服务结合时,它们的重要性更加明显。
传统的SOA已经在MDM和以业务为中心的OLTP应用间实现了功能与持久化的分离,因此主数据能够实现企业内更高的复用。微服务构建在这些收益之上,为分布式架构提供了更好的支持,如果涉及到多个zone的话,其收益会更明显(会在单独的文章中进行讨论)。它们关注功能边界和部署模型,能够让微服务更靠近消费者进行部署,可能会增强可用性、可扩展性和吞吐量,如图13所示。同时,每个微服务只会对自己的数据负责,这意味着主数据的结构和存储可以进行定制,以便于更好地适应使用它们的服务或系统。例如,State Code的微服务可以通过key-value仓库来实现,而不一定采用RDBMS中的表。这种微服务的多个实例可以部署到不同的物理区域上,从而满足东海岸运行的客户端应用以及西海岸运行的账单服务的需求。
(点击放大图像)

图13:基于微服务的MDM Data Hub架构
但是,对这种架构范式可能会出现缺点进行评估是非常重要的。例如,在每个主数据相关的微服务中,可能会重复出现数据的合理化或实体解析(rationalization or entity resolution)、数据清洗和强化(enrichment)功能。同时,在组织内,主实体的唯一性恐怕会难以保证,因为MDM的本质倾向于从企业转移至更靠近限界上下文。因此,在维度设计中,我们甚至需要重新考虑使用一致的维度。
在接下来的内容中,我们将会探讨微服务架构是否能够用于需要密集计算的业务领域。为此,我们将会以5000万份记录作为样例,计算零售信用卡投资组合的总损失分布。图14在一个较高的层级,以可视化的方式展现了如何基于单个损失事件生成总损失分布的步骤。
(点击放大图像)

图14:总损失分布的概要
从年度总亏损的角度来看,零售信贷市场有其独特之处,与大宗的贷款不同,我们无法通过简单地缩减模型就能进行分析。按照一位分析师的说法,“零售信贷市场会向那些没有进行评级的借款人提供资金。每笔贷款的规模相对较小,这就意味着每笔贷款的绝对信贷风险也比较小。任何一笔零售贷款的风险都不会导致银行的破产。因此,确定每笔零售贷款信用风险的成本往往会高于规避风险所带来收益,查清每笔零售贷款的信用风险可能并不是一件值得去做的事情。”
因此,开发一种技术方案来确定几个账户的信用风险可能并没有太大的经济意义,如果要解决不安全贷款相关的信用风险问题,所给出的技术解决方案必须要基于大量的账号来操作,只有这样在经济上才是划算的。同时,该业务领域相关的数据量是造成基于微服务的架构不适合解决计算密集型任务的关键因素之一。在计算不安全的信用卡投资组合所带来的总损失分布时,本文从三个方面介绍了基于微服务的架构所面临的挑战。具体来讲,包括:
- 数据的多样性(Heterogeneity)与数据存储
- 计算能力/强度
- HTTP语义的不适用性
数据的多样性与数据存储
在概念上,微服务鼓励基于限界上下文拥有自己的数据和存储。每个微服务相关的数据格式、内容以及存储形式都可以采用最适合业务功能的方式,如下图所示。因此,在基于微服务的架构中,我们通常会看到各种数据仓库(RDBM与NoSQL)和模式。
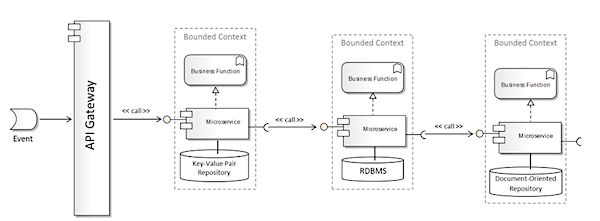
图15:微服务架构——概念视图
但是,预期损失(Expected Loss)和风险值(Value-at-Risk)的计算都依赖于时序数据。这表明源数据不仅需要是完整的,还要非常一致和标准,这样在数据模式多样性方面所能留下的空间就很小了。因此,为了适应时序数据的需求,图15所阐述的概念架构就会演进成图16的样子。这样的话,微服务会共享相同的数据存储,两个repository实例就显得冗余了,这违反了微服务的一个核心原则。
(点击放大图像)
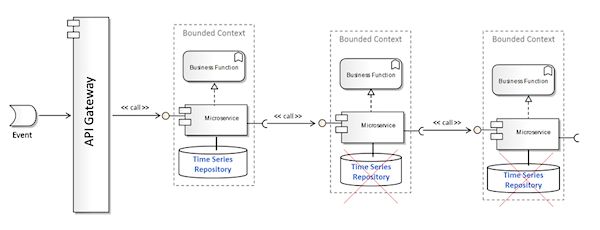
图16
结合图16,从功能的角度来看,下图描述了生成总损失分布(年度总亏损)时,可能采用的context map。从概念上来看,将这些步骤拆分为微服务似乎是可行的。

图17:计算总损失分布时,可能采用的Context Map
但是,在这里数据阻抗(data impedance)可能会再次违反微服务的一个核心原则。总损失分布的计算要从单个损失事件的计算开始。按照前文所述,所有的损失事件记录必须要符合相同的模式。
第一步需要为所有的损失事件创建风险矩阵(risk matrix)。第一步计算得到的尽管是中间结果,但也可能需要进行存储。为了本文的简洁性,这里不再讨论ACID的需求。为了遵循微服务的原则,每个微服务要负责管理自己的数据和底层存储,如图18所示。
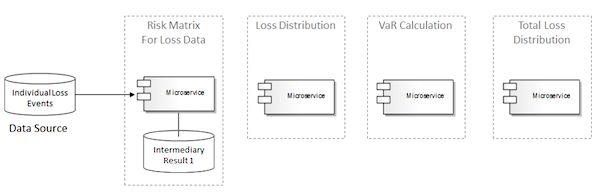
图18
第二步涉及到生成损失分布。这个限界上下文的微服务需要第一个微服务的结果来完成它的功能,但是Loss Distribution微服务不应该直接访问Risk Matrix Loss Data上下文中的数据,否则的话,就会引入紧密耦合了,这样会违反微服务架构的另一个原则,如图19所示。
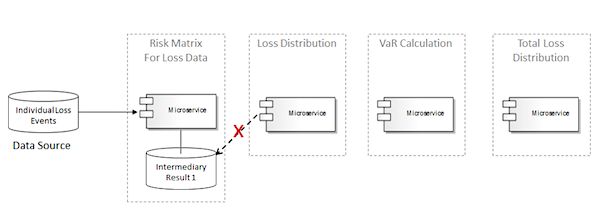
图19
Loss Distribution微服务有两种方式来获取来自Risk Matrix Loss Data上下文中的数据。第一种方式就是对Risk Matrix Loss Data微服务进行READ调用,如图20所示。但是,这种方式并不理想,因为这涉及到转移上百万条的记录。
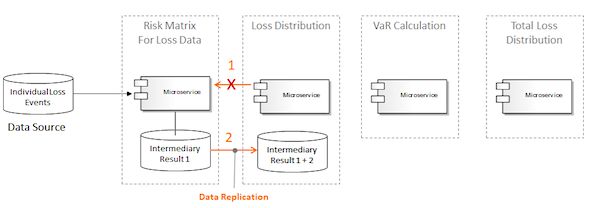
图20
第二种方式就是将来自Risk Matrix Loss Data上下文的数据复制到Loss Distribution上下文中。比起前面的方案,这种方式在技术上更加易于接受,但是,这里所需的数据转移会影响整个进程的性能,当需要转移上百万行的记录时,这种影响会更加明显。
VaR Calculation和Total Loss Distribution微服务会遇到和上面描述完全类似的问题,所以简洁起见,这里我就将其省略了。
通过引入数据缓存,上面所讨论的数据转移的问题可以得到解决,如图21所示。这种设计在本质上是让微服务共享相同的数据存储,尽管是虚拟的,但是它再次规避了微服务架构的一个主要原则。另外,值得一提的是,在每个限界上下文中,为了持久化中间结果,它们的数据存储都有可能会增加,在以上的三个步骤中,都允许重新运行计算。
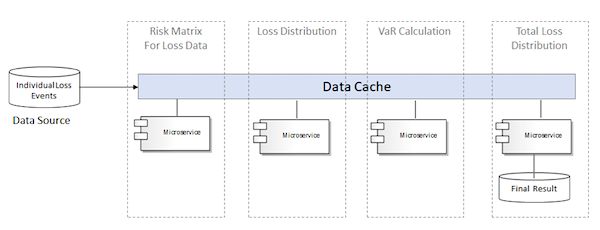
图21
图21中的架构会引出微服务架构不适合计算密集型任务的第二个原因,那就是依赖于所选择的基础设施架构。
计算能力/强度
图22阐述了托管微服务的典型基础设施配置。第一个方案展现的微服务#1部署到了3个节点的集群中,其中每个节点包含两个CPU(这里负载均衡器被省略掉了)。第二个配置所展现的微服务# 2部署到了一个虚拟集群中,它有两个虚拟服务器组成,每台机器同样有两个CPU。
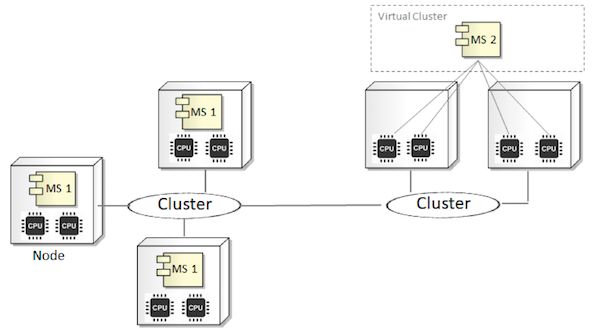
图22:微服务的典型部署架构
通常来讲,这些基础设施配置对于处理OLTP的系统来讲是非常合适的(容错、负载均衡、可扩展性),但是对于计算密集型的任务,它的处理能力可能就不够了,当与任务群(task farm)和网格计算(grid computing)对比时,它的不足就会更加明显了,如图23所示。
(点击放大图像)
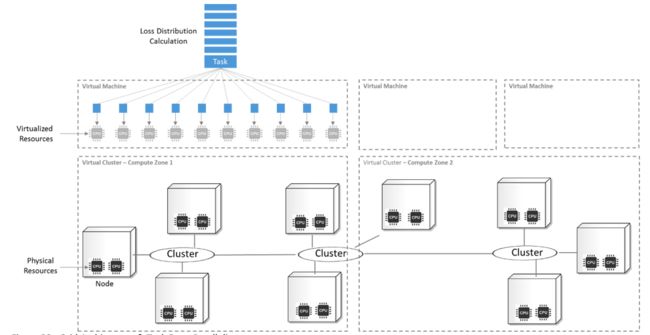
图23:网格架构与任务群并行
HTTP语义的不适用性
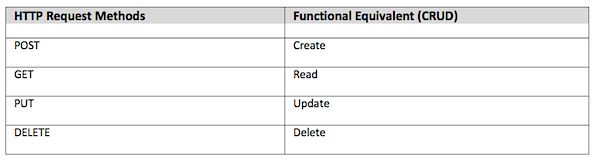
在计算密集的任务中使用基于RESTful的微服务时,所面临的另外一个维度的挑战就是HTTP协议相关的语义。从功能的角度来看,如果对一条或数量有限(比如几百条)的记录进行事务性操作,那么HTTP请求是非常匹配的,如下面的表格所示。
软件设计技术会建议我们暴露一个公开的接口,这个接口反应了底层程序的实际功能,这样的话,消费者在使用接口的时候就不会有任何的歧义性。在总损失分布计算的场景中,支持Loss Distribution上下文的微服务应该暴露一个或多个方法,这些方法代表了生成损失分布的功能,这与CRUD操作是不同的,如下图所示。所以,从语义上来讲,HTTP协议缺乏必要的词汇来处理那些本质上不是事务性的操作。
(点击放大图像)

图24
为了进一步阐述这一点,假设与Risk Matrix for Loss Data上下文相关的微服务能够生成上千条记录的矩阵,我们暂且不提上百万条记录这件事。如前所述,接下来的功能步骤涉及损失分布的生成。但是,Loss Distribution微服务所提供的操作与风险矩阵所要执行任务存在功能上的不匹配。根据名字,第二个服务所暴露的HTTP方法中,我们找不到一个方法应该包含生成损失分布的代码。图25描述了Loss Distribution微服务应该暴露的公开接口。
(点击放大图像)

图25
即使修改第二个微服务的公开接口,以便于更好地反映其功能职责,那也无助于解决将上百万条记录从一个微服务转移至另一个微服务所面临的挑战。从技术的角度来看,合适的方案是尽可能减少数据的转移,所以Hadoop生态系统以及Apache Cassandra是值得深入探讨的相关技术。
总而言之,如果每个微服务的数据和功能都能描述清楚,并且它们之间的依赖能够保持最小,那么基于微服务的架构可能会运行得非常好,至少它是可控的。只要不严格要求ACID特性(CAP理论与最终一致性),OLTP或事务性的系统可能也适用于基于微服务的架构。但是,在涉及到分析领域相关的问题域时,这种架构范式所带来的收益将会很难实现。
查看英文原文:Perspective on Architectural Fitness of Microservices