词嵌入模型浅析——Word2vec与glove
我们在进行自然语言处理(NLP)时,面临的首要问题就是怎么将自然语言输入到模型当中。因为在NLP 里面,最细粒度的是 词语,词语组成句子,句子再组成段落、篇章、文档。所以处理 NLP 的问题,首先就要拿词语开刀。一般来说,对文本的预处理流程如下:
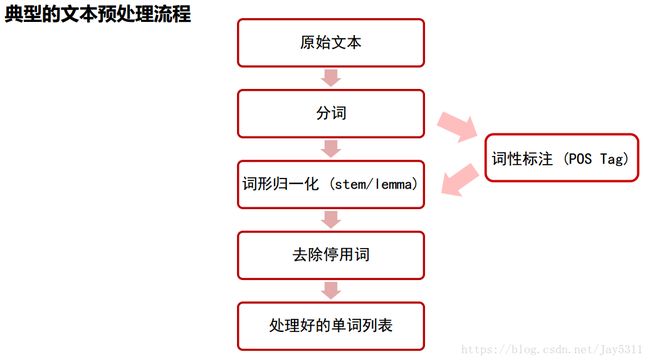
预处理结束后,我们得到的是词汇,而通用的模型接受的输入一般应为数值型。那么如何将分好词的句子转换为数值呢?
很自然的,我们会想到用one—hot vector。假设我们的语料库有10个词汇,我们按一定的规则对词汇进行排序,例如字典序。我们将“a”排在第一个,那么“a”对应的向量值为[1,0,0,0,0,0,0,0,0,0]。这种做法很简单,很容易理解。但是这样做要面临两个问题:
- 输入维度过大。通常语料库中的词汇量都在10000以上,如果以one-hot vector的方式输入神经网络等模型,那么输入的维度将和词汇表大小相同,大大增加模型的参数数量与计算量。
- 缺少语义信息。用以上方法,我们得到的都是都是不包含任何语义信息的稀疏矩阵。简单的单词编号之后,编号相近的单词之间不一定有语义相关性。
这时候就需要大名鼎鼎的word2vec来发挥神通了。
word2vec
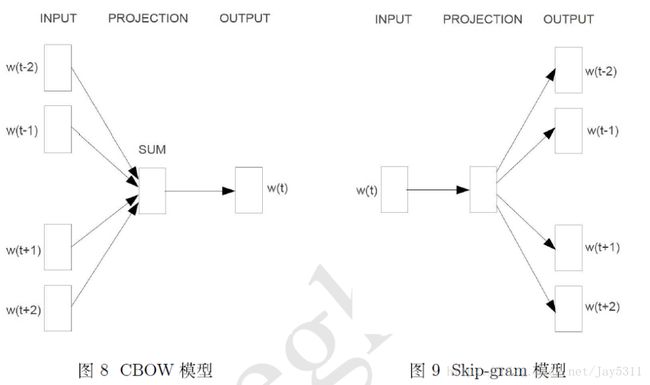
简单来说,word2vec模型就是一个小型的神经网络。既然是神经网络,那么就要给神经网络的学习定个小目标。目前流行的有以下两种模型:
- 如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』
- 而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
word2vec模型包括输入层(input),映射层(projection),隐藏层(hidden)和输出层(output)具体结构如下:
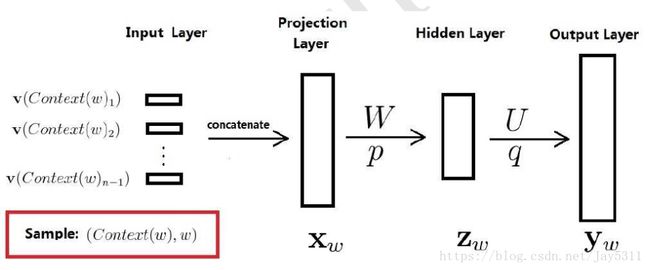
以CBOW模型为例,我们假设输入的n个上下文词汇,语料库大小为10000,我们通过one-hot 将词语转换为[1000,1]的输入向量VI。映射层有[256,1000]的参数矩阵E,输入向量VI经过映射层与E相乘得到一个[256,1]的向量输入隐藏层。我们可以使用softmax分类器,得到预测词在10000个词汇上的概率作为输出。
最终softmax的损失函数就会像之前一样,我们用y表示目标词,我们这里用的y和![]() 都是用one-hot表示的,于是损失函数就会是:
都是用one-hot表示的,于是损失函数就会是:
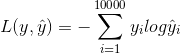
这是常用的softmax损失函数, 就是只有一个1其他都是0的one-hot向量。类似的是一个从softmax单元输出的10,000维的向量,这个向量是所有可能目标词的概率。这样,经过反向传播,我们就可以不断地训练我们的语言模型。
而我们最后得到了什么呢?是目标词的概率吗?当然不是,我们要的是映射层的参数矩阵E,有了它,我们就可以将10000维的稀疏矩阵转换为更小(例如256)且具有语义信息的词向量矩阵。很好的解决了one-hot vector面临的上述两个问题。
存在的问题:
可是这样做又有一个新的问题。我们来看softmax函数的结构:
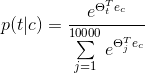 ,其中Θt是与隐藏层有关的参数;
,其中Θt是与隐藏层有关的参数;
如在上面的Softmax单元中,我们需要对所有10000个整个词汇表的词做求和计算,计算量非常庞大。常用的解决方法有以下两种:
Hierarchical Softmax(分层Softmax):
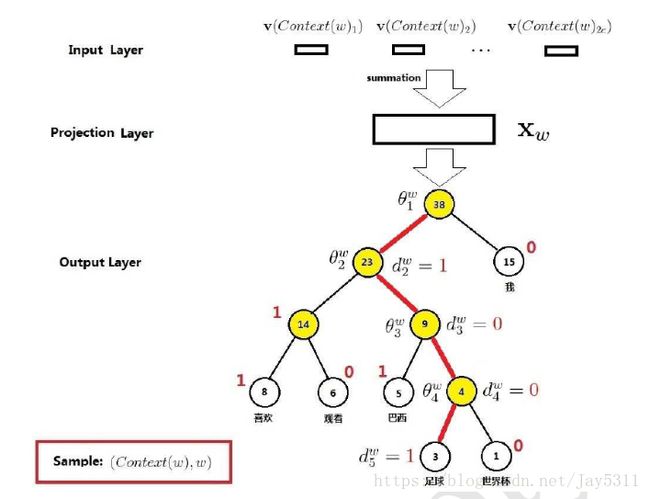
使用分级softmax分类器(相当于一个树型分类器,每个节点都是可能是一个二分类器),其计算复杂度是前面的log级别。在构造分级softmax分类器时,仿造哈夫曼树,一般常用的词会放在树的顶部位置,而不常用的词则会放在树的更深处,其并不是一个平衡的二叉树。
以哈夫曼树为例,树的最大深度为D = log(N) - 1,那么我们只需要做D次二分类,计算复杂度可粗略表示为2(log(N)-1),当N为10000,相比一次性做10000类分类,甚至更大的词汇量的时候,简化的效果就更为显著了。
又有人问,softmax是一次性计算出所有类的概率,二层次softmax一次只是计算出一条子路径上的概率,你这么对比是不对的。问得好,那我们来进一步探究一下。以下图为例,我们在每个节点上做二分类,就会得到两个子节点的概率,所以当我们得到叶节点“世界杯”的概率时(计算复杂度为O(log(D)),其实已经得到除了8,6以外所有节点的概率。显然计算8,6概率的计算复杂度O(8&6)是不会超过O(log(D)的。所以,两者相加,最后的时间复杂度还是O(log(D)。
Negative Sampling(负采样):
- 定义一个新的学习问题:预测两个词之间是否是上下文-目标词对,如果是词对,则学习的目标为1;否则为0。
- 使用k次相同的上下文,随机选择不同的目标词,并对相应的词对进行正负样本的标记,生成训练集。
- 建议:小数据集,k=5~20;大数据集,k=2~5。
- 最后学习x——y的映射关系。
在负采样模型中,我们使用logistic回归模型:
![]()
每个正样本均有k个对应的负样本。在训练的过程中,对于每个上下文词,我们就有对应的k+1k+1个分类器。如下图所示:
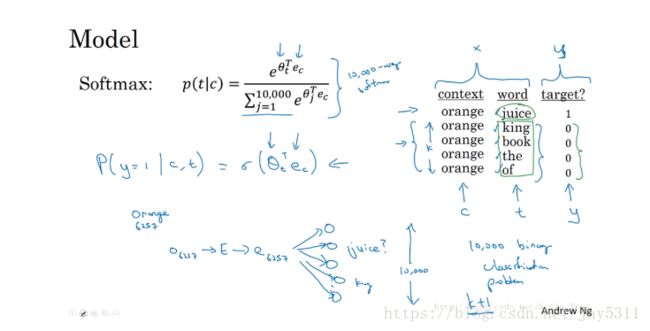
相比于Skip-grams模型,负采样不再使用一个具有词汇表大小时间复杂度高的庞大维度的Softmax,而是将其转换为词汇表大小个二分类问题。每个二分类任务都很容易解决,因为每个的训练样本均是1个正样本,外加k个负样本。
Glove模型
Glove这种训练词向量的方法的核心思想是通过对’词-词’共现矩阵进行分解从而得到词表示的方法。具体的数学推导不再细说。有兴趣的可以参考:理解GloVe模型
Glove和Skip-gram、CBOW模型对比
Skip-gram、CBOW计算时只考虑了单个窗口内的词汇信息,而Glove是同时考虑多个窗口(共现矩阵),引入了全局信息。
Glove的计算更简单,可以加快模型的训练速度。
Skip-gram、CBOW容易使得高曝光的词汇获得过高的权重,而Glove模型引入了权重函数,可以控制词的相对权重。
本篇文章相当于笔记,写的比较随意,如果有什么偏差,还请多多指教。具体的数学推导可以参考:word2vec 中的数学原理详解