AlexNet详解
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
✨完整代码在我的github上,有需要的朋友可以康康✨
GitHub - tt-s-t/Deep-Learning: Store some of your own in-depth learning code, which is currently in the update stage.The content covers: each algorithm should be implemented in two ways as far as possible (database debugging and self building).
目录
一、AlexNet网络的背景
二、AlexNet网络结构
1、结构图
2、整体介绍
3、输入
4、卷积层
(1)第一层
(2)第二层
(3)第三层
(4)第四层
(5)第五层
5、全连接层
(1)第六层
(2)第七层
(3)第八层
6、GPU交互
三、AlexNet的亮点
1、在多个GPU上进行模型的训练
2、使用dropout
3、使用ReLU作为激活函数代替了传统的Sigmoid
4、重叠最大池化
5、图像增广,数据增强
四、AlexNet代码实现
一、AlexNet网络的背景
AlexNet由Geoffrey和他的学生Alex提出的一个深层的卷积神经网络,并在2012年的ILSVRC竞赛中获得了第一名。为解决的是:大规模的图像分类问题。
二、AlexNet网络结构
1、结构图
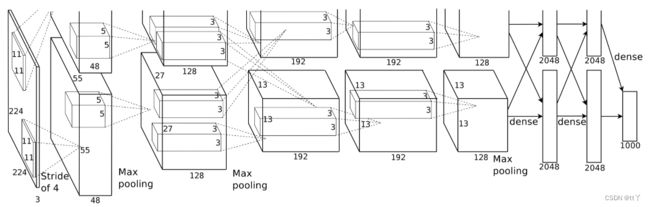

接下来我们根据这张网络结构图来探索AlexNet的网络结构。
2、整体介绍
分为上下两层,分别对应两个GPU的操作过程,除了中间某些卷积层和全连接层会有GPU间的交互外,其他层都是由两个GPU分别计算结果。
除去局部响应规范化操作(LRN),AlexNet一共包含8层,前5层由卷积层(其中卷积层1、2、5后含有下采样层)组成,(中间还夹带一个平均池化),剩下的3层为全连接层。最后一层全连接层输出,得到1000个图像分类标签对应的得分值。
除了GPU并行结构的设计,AlexNet网络结构和LeNet很相像。
3、输入
输入是(224,224,3)的图像数据
4、卷积层
(1)第一层

(224,224,3)->(55,55,64)->(27,27,64)
Note:本来这后面还接了个norm层,即LRN 局部响应归一化
(2)第二层

(27,27,64)->(27,27,192)->(13,13,192)
(3)第三层
![]()
(13,13,192) ->(13,13,384)
注:需要GPU交互
(4)第四层
![]()
(13,13,384) ->(13,13,256)
(5)第五层

(13,13,256) ->(13,13,256)->(6,6,256)
5、全连接层
(1)第六层

6*6*256 -> 4096
注:需要GPU交互
(2)第七层

4096 -> 4096
注:需要GPU交互
(3)第八层
![]()
4096 -> 1000,得到1000个图像分类标签对应的得分值
注:需要GPU交互
6、GPU交互
最早的AlexNet使用这种双数据流的GPU交互是因为早期显存的限制。现在的Alexnet的应用已经不需要这样的交互设计了。
三、AlexNet的亮点
1、在多个GPU上进行模型的训练
不但可以提高模型的训练速度,还能提升数据的使用规模,解决当时的显存受限问题。
2、使用dropout
选择性地忽略训练中的单个神经元,减缓模型的过拟合问题。
3、使用ReLU作为激活函数代替了传统的Sigmoid
(1)ReLu的计算比较简单,速度更快
(2)sigmoid函数当输出接近0或者1的时候,梯度几乎为0,会导致反向传播无法继续更新部分模型参数,而ReLU在正区间的梯度恒为1。选择ReLu,避免了模型参数初始化不当,sigmoid函数可能会得到几乎为0的梯度的问题。
4、重叠最大池化
即池化范围z与步长s存在关系z > s(如最大池化下采样中核大小为3 × 3,步距为2)
这样可以避免平均池化的平均效应。
5、图像增广,数据增强
AlexNet引入了大量图像增广,如翻转,裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
四、AlexNet代码实现
详见GitHub - tt-s-t/Deep-Learning: Store some of your own in-depth learning code, which is currently in the update stage.The content covers: each algorithm should be implemented in two ways as far as possible (database debugging and self building).
中的AlexNet文件夹。
欢迎大家在评论区批评指正,谢谢~