Python 实践心得 —— 中英混杂的字符串对齐输出
Python 实践心得 —— 中英混杂的字符串对齐输出
第一次写技术博客,Python刚刚开始学习写的不好请多指教。
据说程序猿都有点强迫症
听说Python的爬虫很厉害,于是学习着,第一次实践去爬了个起点网的网页下来。

代码如下,小白写的很渣。。。正则什么的真的好难记啊
# -*- coding:utf-8 -*-
# ======================= 库导入 ============================
import urllib
import re
# ======================= 网络参数 ===========================
# 查询网址
url = "http://a.qidian.com"
# 正则字段
target = r'target="_blank" data-eid="qd_B58" data-bid=".*?">(.*?).*?' \
r'(.*?).*?'
\
r'target="_blank" data-eid="qd_B60">(.*?)'
# ======================== 主程序 ============================
resp = urllib.urlopen(url).read() # http响应
print resp
assert isinstance(resp, basestring) # 确定是否有正确的回应
reg = re.compile(target, re.S) # 编译正则表达式
names = re.findall(reg, resp) # re模块查找
print '一共有',len(names), '个结果\n'
for i in names: # 遍历输出
print
for j in range(0, len(i)):
sys.stdout.write(i[j])然后试着用正则表达式抓取了书名、字数、分类下来,输出如下:

结果,恩,好像挤一起不是很好看
嗯,加空格或者制表符试试
加上空格试试看。根据设定的字符长度格式,检测需要输出的字符串长度,找到两者的差值,用空格补上。
这里可以用format或者ljust(靠左对齐)、rjust(靠右对齐)调教
下面的代码能让如下的字符串向左对齐,长度限定30,不够的在右侧填充‘-’(不填默认参数是空格)
str = 'This is a string.'
str.ljust(30,'-')
# 输出:
# This is a string.主程序改成了:
# ======================== 主程序 ============================
resp = urllib.urlopen(url).read() # http响应
print resp
assert isinstance(resp, basestring) # 确定是否有正确的回应
reg = re.compile(target, re.S) # 编译正则表达式
names = re.findall(reg, resp) # re模块查找
print '一共有',len(names), '个结果\n'
for i in names: # 遍历输出
print
for j in range(0, len(i)):
sys.stdout.write(i[j].ljust(30)) # 加上了ljust-结果输出结果如下:

还是没有对齐,心累。
杀死强迫症的全角字符
仔细观察发现中文在默认的utf-8编码下一个中文占用3个字符,而显示占用约2个字符。
那么问题主要就变成了如何检测中文字符了。
小白我查阅资料得到:
常见中文的Unicode编码范围是4E00-9FA5 —— 中文Unicode编码表:
http://www.qqxiuzi.cn/zh/hanzi-unicode-bianma.php

恩,明白了,检测中文字的代码就可以出来了。还有在Python 2.7环境下最好在开头加上这一段:
import sys
from utf8detect import is_chinese
reload(sys)
sys.setdefaultencoding('utf8')免得出ASCII码不能转码的错误。
另外,关于Unicode和utf-8的关系啰嗦一句。经常会因为二者令人迷惑的关系而出错。
重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一,它规定了字符如何在计算机中存储、传输等。
—— 摘自“到底utf-8和unicode是什么关系”
http://alexiter.iteye.com/blog/1533109
也就是说utf-8也属于Unicode,只是我们在Python说的Unicode是“严”定义的Unicode,详细的可以参考链接里的博客。
(注意:这里对text的utf-8解码成Unicode一定要有,不然检查不出)
# ======================== 中文检测 ==========================
def findChinese(text):
if isinstance(text, unicode):
return ''
text = text.decode('utf8')
res = re.findall(u"[\u4e00-\u9fa5]", text) # \u4e00-\u9fa5是中文常用字段
return res上面代码里的findChinese()的参数是待检测的字符串,而返回的是检测出中文组成的tuple,返回的tuple在这里已经由utf-8转码成Unicode。
其实这里改变编码的检查范围也可以用来检测其他的字符什么的。
那就填充全角字符吧
完成了中文检测,怎么对齐呢?
上♂万能的度娘去看看吧。
哦啊,原来是:
每个中文占用的是一个全角字符位置,和半角字符组合在一起就不能对齐了
于是我决定,统计所有中文字的个数,再计算出半角字符的数量。要求格式输入变量改为:
- 统一的全角字符个数lenf
- 统一的半角字符个数lenh
- 用于填充的全角字符addf
- 用于填充的全角字符addh
代码如下,函数返回的是填充的字符串:
# -*- coding:utf-8 -*-
# 功能:Python爬虫练习,目标起点网
# 内置中文检测,中文对齐
# ======================= 库导入 ============================
import urllib
import re
import sys
from utf8detect import is_chinese
reload(sys)
sys.setdefaultencoding('utf8')
# ======================== 中文检测 ==========================
def findChinese(text):
if isinstance(text, unicode):
return ''
text = text.decode('utf8')
res = re.findall(u"[\u4e00-\u9fa5]", text) # \u4e00-\u9fa5是中文常用字段
return res
# ======================== 填充指定字符 ==========================
def myAlign(un_align_str, lenh=0, lenf=0, addh=' ', addf=' '):
assert isinstance(lenh, int) # 输入长度是否为整数,否则报错
assert isinstance(lenf, int) # 输入长度是否为整数
if (lenh+lenf*2) <= len(un_align_str): # 小于输入长度返回原字符
return un_align_str
strlen = len(un_align_str)
chn = findChinese(un_align_str)
numchn = len(chn)
numsph = strlen - numchn * 3
str = addh*(lenh-numsph) + addf*(lenf-numchn)
# # 以下仅供测试输出
# print '\n' + '='*20
# print 'str = ', un_align_str
# for i in range(numchn):
# print 'Chinese = ', chn[i]
# print '中文字符数 = ', numchn
# print '半角字符数 = ', numsph
# print '全角字符数 = ', numchn
# print '总字符数 = ', strlen
return str
# ======================= 网络参数 ===========================
# 查询网址
url = "http://a.qidian.com"
# 正则字段
target = r'target="_blank" data-eid="qd_B58" data-bid=".*?">(.*?).*?' \
r'(.*?).*?'
\
r'target="_blank" data-eid="qd_B60">(.*?)'
# ======================== 主程序 ============================
resp = urllib.urlopen(url).read() # http响应
print resp
assert isinstance(resp, basestring) # 确定是否有正确的回应
reg = re.compile(target, re.S) # 编译正则表达式
names = re.findall(reg, resp) # re模块查找
print '一共有',len(names), '个结果\n'
for i in names: # 遍历输出
print
for j in range(0, len(i)):
sys.stdout.write(str(i[j]) + myAlign(i[j],10,10)) # 标准设为10个全角10个半角运行结果:

可以看到已经完美对齐了,强迫症被满足了。。。
只填充半角字符也行吧
只用一种方法?这绝对不是我们强迫症晚期的作风啊!
嗯,好像有个帖子说中文全角字符实际输出占用的是两个半角字符的位置。
那我们就继续写,给每个中文字多填充一个半角字符的位置试试看吧。
整个爬虫练习程序就贴出来吧。
# -*- coding:utf-8 -*-
# 功能:Python爬虫练习,目标起点网
# 内置中文检测
# ======================= 库导入 ============================
import urllib
import re
import sys
from utf8detect import is_chinese
reload(sys)
sys.setdefaultencoding('utf8')
# ======================== 中文检测 ==========================
def findChinese(text):
if isinstance(text, unicode):
return ''
text = text.decode('utf8')
res = re.findall(u"[\u4e00-\u9fa5]",text)
# \u4e00-\u9fa5是中文常用字段
return res
# ======================== 填充指定字符 ==========================
def myAlign(un_align_str, length=0, addin=' '):
assert isinstance(length, int) # 输入长度是否为整数
if length <= len(un_align_str): # 小于输入长度返回原字符
return un_align_str
strlen = len(un_align_str)
chn = findChinese(un_align_str)
numchn = len(chn)
numsp = length - strlen + numchn # 填充半角字符的的个数
str = addin * numsp # 生成填充字符串
return str # 返回填充的字符串
# ======================= 网络参数 ===========================
# 查询网址
url = "http://a.qidian.com"
# 正则字段
target = r'target="_blank" data-eid="qd_B58" data-bid=".*?">(.*?).*?' \
r'(.*?).*?'
\
r'target="_blank" data-eid="qd_B60">(.*?)'
# ======================== 主程序 ============================
resp = urllib.urlopen(url).read() # http响应
print resp
assert isinstance(resp, basestring) # 确定是否有正确的回应
reg = re.compile(target, re.S) # 编译正则表达式
names = re.findall(reg, resp) # re模块查找
print '一共有',len(names), '个结果\n'
for i in names: # 遍历输出
print
for j in range(0, len(i)):
sys.stdout.write(str(i[j]) + myAlign(i[j],30))运行结果:
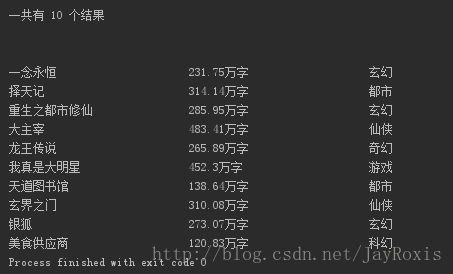
这里我设置的是以30个半角字符为标准长度,看起来完美吧。
番外:IDE字体不同对不齐的江湖传言
由于每个人使用的IDE不同,我用的是PyCharm,拥有显示区设置字体的功能。实际上如果用Python开发应用程序。需要对齐的话会受到中文英文字体变化的限制:
重点内容:在某些字体下,中文不再占用2个半角字符。
可以看出,在使用方便性上,显然是只填充半角字符会方便得多,但是为了适应字体的变化,同时填充全角字符和半角字符就会好很多。
综上可以看出,以上的两种中英文混排方法是各有好处的。
以上随便转载,造福强迫症。
如果想看到更多Py滑稽thon心得点个赞告诉我吧。