python爬虫基础(4:数据保存)
保存数据的方式有很多,比如之前文章里用open()、write()保存到文本
本篇将介绍保存到 mysql数据库 的方法
准备工作
建数据表、安装mysql的python驱动模块 pymysql
案例依旧选择前面文章(https://blog.csdn.net/jeeson_z/article/details/81281770)的豆瓣电影Top250
连接数据库(创建一个连接对象)
一句话搞定 注意设置编码格式
# 导入pymysql驱动模块
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456xun', db='csdn', charset='utf8mb4')编写mysql语句并创建操作游标
# 编写mysql语句
sql_insert = 'INSERT INTO movies(img, name, intro, score, fans_num, quote) VALUES (%s, %s, %s, %s, %s, %s)'
# 利用cursor()方法创建一个操作游标
cursor = db.cursor()执行mysql语句并赋值提交
# 用execute()方法执行mysql插入语句
cursor.execute(sql_insert, (img, name, intro, score, fans_num, quote))
# 用commit()方法提交操作
db.commit()关闭数据库
# 操作完后关闭数据库
db.close()结果展示
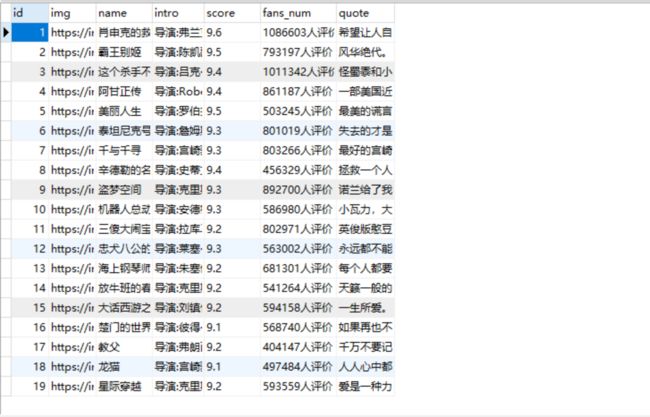
全部代码
# 导入requests模块
import requests
# 导入BeautifulSoup模块
from bs4 import BeautifulSoup
# 导入正则re模块
import re
# 导入pymysql驱动模块
import pymysql
# 用connect()方法连接数据库
db = pymysql.connect(host='localhost', user='root', password='123456xun', db='csdn', charset='utf8mb4')
# 编写mysql语句
sql_insert = 'INSERT INTO movies(img, name, intro, score, fans_num, quote) VALUES (%s, %s, %s, %s, %s, %s)'
# 利用cursor()方法创建一个操作游标
cursor = db.cursor()
# 获取要爬取的网页的url
url = 'https://movie.douban.com/top250'
# 用get()方法请求下载网页
rsp = requests.get(url)
# text属性返回网页源码的内容
text = rsp.text
# 用BeautifulSoup()方法将源码内容生成能用BeautifulSoup解析的lxml格式文件
BS = BeautifulSoup(text, 'lxml')
# 用find_all()方法找到包含电影的所有标签
movies = BS.find_all(name='div', attrs={'class': 'item'})
# 遍历每一个电影信息
for movie in movies:
# 提取图片的地址信息
img = movie.find(name='img', attrs={'width': '100'}).attrs['src']
# 提取电影名字信息
name = movie.find(name='span', attrs={'class': 'title'}).string
# 提取电影介绍信息
# 注意:get_text()能提取包含有内嵌标签的信息
intro = movie.find(name='p', attrs={'class': ''}).get_text()
# 用正则提取所有的可见字符
intro = re.findall('\S', intro, re.S)
# 将列表转化为字符串
intro = ''.join(intro)
# 提取评价信息
# 注意:评价信息分别在在多个里面,所以用findall()方法
star = movie.find(name='div', attrs={'class': 'star'}).find_all(name='span')
# 获取评分
score = star[1].string
# 获取评价人数
fans_num = star[3].string
# 获取引语
quote = movie.find(name='span', attrs={'class': 'inq'}).string
# 用execute()方法执行mysql插入语句
cursor.execute(sql_insert, (img, name, intro, score, fans_num, quote))
# 用commit()方法提交操作
db.commit()
# 操作完后关闭数据库
db.close()github 地址:https://github.com/JeesonZhang/pythonspider/blob/master/doubanmoviestop.py