OpenStack Nova 高性能虚拟机之 NUMA 架构亲和
目录
文章目录
- 目录
- 写在前面
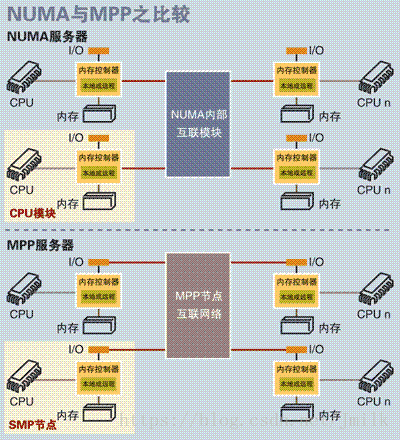
- 计算平台体系结构
- SMP 对称多处理结构
- NUMA 非统一内存访问结构
- MPP 大规模并行处理结构
- Linux 上的 NUMA
- 基本对象概念
- NUMA 调度策略
- 获取宿主机的 NUMA 拓扑
- Nova 实现的 NUMA 亲和
- Nova 定义的 NUMA 对象概念
- 实现 NUMA 亲和的背景
- 操作系统发行版许可证(Licensing)
- CPU 拓扑对性能的影响
- CPU 架构对性能的影响
- 超线程对性能的影响
- NUMA Topology
- Guest NUMA Topology
- 在 Nova 上应用 NUMA 亲和来创建高性能虚拟机
- Nova 使用 NUMA 和 CPU Binding 的 EXAMPLE
- TS1:Requested instance NUMA topology cannot fit the given host NUMA topology.
- TS2:Filter NUMATopologyFilter returned 0 hosts
写在前面
最近太忙了,笔者实在懒得画图,文章的图片大多来源于互联网,感谢创作者们(可惜找不到源出处)。
这篇博文与其说是介绍 OpenStack Nova 的高性能虚拟机,倒不如说是介绍 CPU 相关的硬件架构与应用程序之间的爱恨情仇更加贴切一些。
计算平台体系结构
SMP 对称多处理结构
SMP(Sysmmetric Multi-Processor,对称多处理器),顾名思义,SMP 由多个具有对称关系的处理器组成。所谓对称,即处理器之间是水平的镜像关系,无有主从之分。SMP 的出现使一台计算机不再由单个 CPU 组成。
SMP 的典型特征为**「多个处理器共享一个集中式存储器」**,且每个处理器访问存储器的时间片相同,使得工作负载能够均匀的分配到所有可用处理器上,极大地提高了整个系统的数据处理能力。
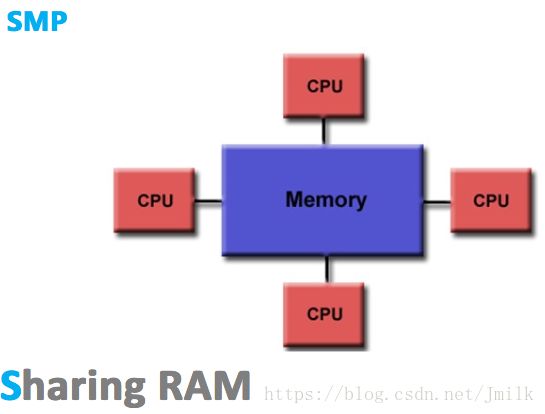
虽然 SMP 具有多个处理器,但由于只有一个共享的集中式存储器,所以 SMP 只能运行一个操作系统和数据库系统的副本(实例),依旧保持了单机特性。同时,SMP 也会要求多处理器保证共享存储器的数据一致性。如果多个处理器同时请求访问共享资源,就需要由软件或硬件实现的加锁机制来解决资源竞态的问题。由此,SMP 又称为 UMA(Uniform Memory Access,一致性存储器访问),所谓一致性指的是:
- 在任意时刻,多个处理器只能为存储器的每个数据保存或共享一个唯一的数值。
- 每个处理器访问存储器所需要的时间都是一致的
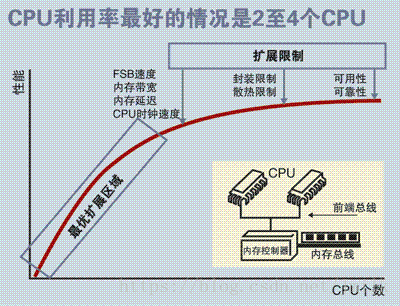
显然,这样的架构设计注定没法拥有良好的处理器数量扩展性,因为共享存储的资源竞态总是存在的,处理器利用率最好的情况只能停留在 2 到 4 颗。综合来看,SMP 架构广泛的适用于 PC 和移动设备领域,能显著提升并行计算性能。但 SMP 却不适合超大规模的服务器端场景,例如:云计算。
NUMA 非统一内存访问结构
现代计算机系统中,处理器的处理速度已经超过了主存的读写速度,限制计算机计算性能的瓶颈转移到了存储器带宽之上。SMP 由于集中式共享存储器的设计限制了处理器访问存储器的频次,导致处理器可能会经常处于对数据访问的饥饿状态。
**NUMA(Non-Uniform Memory Access,非一致性存储器访问)**的设计理念是将处理器和存储器划分到不同的节点(NUMA Node),它们都拥有几乎相等的资源。在 NUMA 节点内部会通过自己的存储总线访问内部的本地内存,而所有 NUMA 节点都可以通过主板上的共享总线来访问其他节点的远程内存。
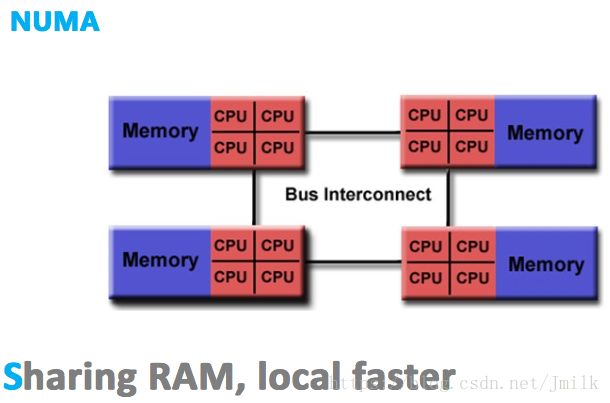
很显然,处理器访问本地内存和远程内存的时耗并不一致,NUMA 非一致性存储器访问由此得名。而且因为节点划分并没有实现真正意义上的存储隔离,所以 NUMA 同样只会保存一份操作系统和数据库系统的副本。
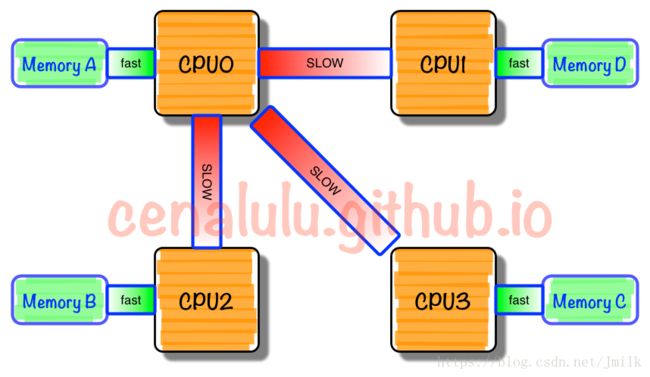
NUMA「多节点」的结构设计能够在一定程度上解决 SMP 低存储带宽的问题。假如有一个 4 NUMA 节点的系统,每一个 NUMA 节点内部具有 1GB/s 的存储带宽,外部共享总线也同样具有 1GB/s 的带宽。理想状态下,如果所有的处理器总是访问本地内存的话,那么系统就拥有了 4GB/s 的存储带宽能力,此时的每个节点可以近似的看作为一个 SMP(这种假设为了便于理解,并不完全正确);相反,在最不理想的情况下,如果所有处理器总是访问远程内存的话,那么系统就只能有 1GB/s 的存储带宽能力。
除此之外,使用外部共享总线时可能会触发 NUMA 节点间的 Cache 同步异常,这会严重影响内存密集型工作负载的性能。当 I/O 性能至关重要时,共享总线上的 Cache 资源浪费,会让连接到远程 PCIe 总线上的设备(不同 NUMA 节点间通信)作业性能急剧下降。
由于这个特性,基于 NUMA 开发的应用程序应该尽可能避免跨节点的远程内存访问。因为,跨节点内存访问不仅通信速度慢,还可能需要处理不同节点间内存和缓存的数据一致性。多线程在不同节点间的切换,是需要花费大成本的。
虽然 NUMA 相比于 SMP 具有更好的处理器扩展性,但因为 NUMA 没有实现彻底的主存隔离。所以 NUMA 远没有达到无限扩展的水平,最多可支持几百个 CPU。这是为了追求更高的并发性能所作出的妥协,一个节点未必就能完全满足多并发需求,多节点间线程切换实属一个折中的方案。这种做法使得 NUMA 具有一定的伸缩性,更加适合应用在服务器端。
MPP 大规模并行处理结构
MPP(Massive Parallel Processing,大规模并行处理),既然 NUMA 扩展性的限制是没有完全实现资源(e.g. 存储器、互联模块)的隔离性,那么 MPP 的解决思路就是为处理器提供彻底的独立资源。
MPP 拥有多个真正意义上的独立的 SMP 单元,每个 SMP 单元独占并只会访问自己本地的内存、I/O 等资源,SMP 单元间通过节点互联网络进行连接(Data Redistribution,数据重分配),是一个完全无共享(Share Nothing)的 CPU 计算平台结构。
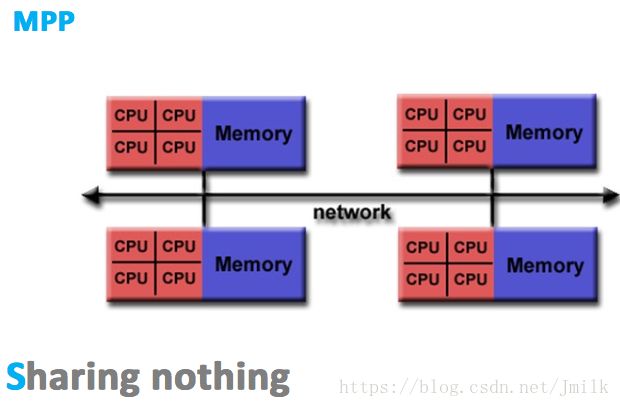
MPP 的典型特征就是**「多 SMP 单元组成,单元之间完全无共享」**。除此之外,MPP 结构还具有以下特点:
- 每个 SMP 单元内都可以包含一个操作系统副本,所以每个 SMP 单元都可以运行自己的操作系统
- MPP 需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程,目前一些基于 MPP 技术的服务器往往通过系统级软件(e.g. 数据库)来屏蔽这种复杂性
- MPP 架构的局部区域内存的访存延迟低于远地内存访存延迟,因此 Linux 会自定采用局部节点分配策略,当一个任务请求分配内存时,首先在处理器自身节点内寻找空闲页,如果没有则到相邻的节点寻找空闲页,如果还没有再到远地节点中寻找空闲页,在操作系统层面就实现了访存性能优化
因为完全的资源隔离特性,所以 MPP 的扩展性是最好的,理论上其扩展无限制,目前的技术可实现 512 个节点互联,数千个 CPU,多应用于大型机。
Linux 上的 NUMA
基本对象概念
- Node:包含有若干个 Socket 的组
- Socket:表示一颗物理 CPU 的封装,简称插槽。Intel 为了避免将物理处理器和逻辑处理器混淆,所以将物理处理器统称为插槽。
- Core:Socket 内含有的物理核。
- Thread:在具有 Intel 超线程技术的处理器上,每个 Core 可以被虚拟为若干个(通常为两个)逻辑处理器,逻辑处理器会共享大多数内核资源(e.g. 内存缓存、功能单元)。逻辑处理器被统称为 Thread。
- Processor:处理器的统称,可以区分为物理处理器(physical processor)和逻辑处理器(virtual processors),对于大多数应用程序而言,它们并不关心处理器是物理的还是逻辑的。
- Siblings:表示每一个 physical processor 所含有的 virtual processors 的数量。(If the number of siblings is equal to the number of cores then you have CPUs which are not hyperthreading or hyperthreading is switched off, If the number of siblings is 2x the number of cores then you have a hyperthreading CPU with hyperthreading switched on. )

(一个 Socket 4 个 Core)
包含关系:NUMA Node > Socket > Core > Thread
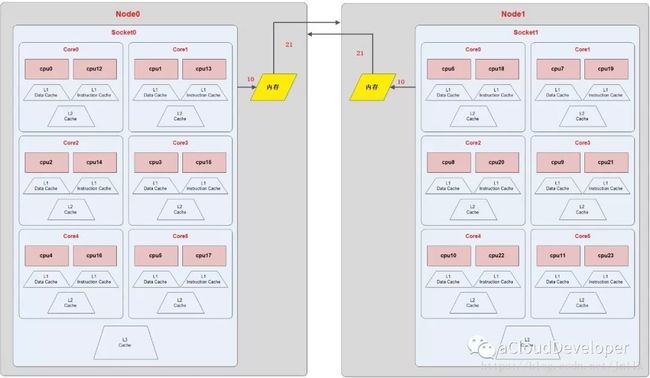
EXAMPLE:上图为一个 NUMA Topology,表示该服务器具有 2 个 numa node,每个 node 含有一个 socket,每个 socket 含有 6 个 core,每个 core 又被超线程为 2 个 thread,所以服务器总共的 processor = 2*1*6*2 = 24 颗。
NUMA 调度策略
Linux 的每个进程或线程都会延续父进程的 NUMA 策略,优先会将其约束在一个 NUMA node 内。当然了,如果 NUMA 策略允许的话,进程也可以调用其他 node 上的资源。
NUMA 的 CPU 分配策略有下列两种:
- cpunodebind:约束进程运行在指定的若干个 node 内
- physcpubind:约束进程运行在指定的若干个物理 CPU 上
NUMA 的 Memory 分配策略有下列 4 种:
- localalloc:约束进程只能请求访问本地内存
- preferred:宽松地为进程指定一个优先 node,如果优先 node 上没有足够的内存资源,那么进程允许尝试运行在别的 node 内
- membind:规定进程只能从指定的若干个 node 上请求访问内存,并不严格规定只能访问本地内存
- interleave:规定进程可以使用 RR 算法轮转地从指定的若干个 node 上请求访问内存
获取宿主机的 NUMA 拓扑
Bash 脚本:
#!/bin/bash
function get_nr_processor()
{
grep '^processor' /proc/cpuinfo | wc -l
}
function get_nr_socket()
{
grep 'physical id' /proc/cpuinfo | awk -F: '{
print $2 | "sort -un"}' | wc -l
}
function get_nr_siblings()
{
grep 'siblings' /proc/cpuinfo | awk -F: '{
print $2 | "sort -un"}'
}
function get_nr_cores_of_socket()
{
grep 'cpu cores' /proc/cpuinfo | awk -F: '{
print $2 | "sort -un"}'
}
echo '===== CPU Topology Table ====='
echo
echo '+--------------+---------+-----------+'
echo '| Processor ID | Core ID | Socket ID |'
echo '+--------------+---------+-----------+'
while read line; do
if [ -z "$line" ]; then
printf '| %-12s | %-7s | %-9s |\n' $p_id $c_id $s_id
echo '+--------------+---------+-----------+'
continue
fi
if echo "$line" | grep -q "^processor"; then
p_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
fi
if echo "$line" | grep -q "^core id"; then
c_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
fi
if echo "$line" | grep -q "^physical id"; then
s_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
fi
done < /proc/cpuinfo
echo
awk -F: '{
if ($1 ~ /processor/) {
gsub(/ /,"",$2);
p_id=$2;
} else if ($1 ~ /physical id/){
gsub(/ /,"",$2);
s_id=$2;
arr[s_id]=arr[s_id] " " p_id
}
}
END{
for (i in arr)
printf "Socket %s:%s\n", i, arr[i];
}' /proc/cpuinfo
echo
echo '===== CPU Info Summary ====='
echo
nr_processor=`get_nr_processor`
echo "Logical processors: $nr_processor"
nr_socket=`get_nr_socket`
echo "Physical socket: $nr_socket"
nr_siblings=`get_nr_siblings`
echo "Siblings in one socket: $nr_siblings"
nr_cores=`get_nr_cores_of_socket`
echo "Cores in one socket: $nr_cores"
let nr_cores*=nr_socket
echo "Cores in total: $nr_cores"
if [ "$nr_cores" = "$nr_processor" ]; then
echo "Hyper-Threading: off"
else
echo "Hyper-Threading: on"
fi
echo
echo '===== END ====='
OUTPUT:
===== CPU Topology Table =====
+--------------+---------+-----------+
| Processor ID | Core ID | Socket ID |
+--------------+---------+-----------+
| 0 | 0 | 0 |
+--------------+---------+-----------+
| 1 | 1 | 0 |
+--------------+---------+-----------+
| 2 | 2 | 0 |
+--------------+---------+-----------+
| 3 | 3 | 0 |
+--------------+---------+-----------+
| 4 | 4 | 0 |
+--------------+---------+-----------+
| 5 | 5 | 0 |
+--------------+---------+-----------+
| 6 | 0 | 1 |
+--------------+---------+-----------+
| 7 | 1 | 1 |
+--------------+---------+-----------+
| 8 | 2 | 1 |
+--------------+---------+-----------+
| 9 | 3 | 1 |
+--------------+---------+-----------+
| 10 | 4 | 1 |
+--------------+---------+-----------+
| 11 | 5 | 1 |
+--------------+---------+-----------+
| 12 | 0 | 0 |
+--------------+---------+-----------+
| 13 | 1 | 0 |
+--------------+---------+-----------+
| 14 | 2 | 0 |
+--------------+---------+-----------+
| 15 | 3 | 0 |
+--------------+---------+-----------+
| 16 | 4 | 0 |
+--------------+---------+-----------+
| 17 | 5 | 0 |
+--------------+---------+-----------+
| 18 | 0 | 1 |
+--------------+---------+-----------+
| 19 | 1 | 1 |
+--------------+---------+-----------+
| 20 | 2 | 1 |
+--------------+---------+-----------+
| 21 | 3 | 1 |
+--------------+---------+-----------+
| 22 | 4 | 1 |
+--------------+---------+-----------+
| 23 | 5 | 1 |
+--------------+---------+-----------+
Socket 0: 0 1 2 3 4 5 12 13 14 15 16 17
Socket 1: 6 7 8 9 10 11 18 19 20 21 22 23
===== CPU Info Summary =====
Logical processors: 24
Physical socket: 2
Siblings in one socket: 12
Cores in one socket: 6
Cores in total: 12
Hyper-Threading: on
===== END =====
NOTE 1:Processors / Cores = 每个物理内核超线程出来的逻辑处理器数量,一般为 2 个。
NOTE 2:上述具有相同 Socket ID 和 Core ID 的 2 个 Processors 就是由同一个 Core 超线程出来的两个逻辑处理器。
DPDK 官方提供的 Python 脚本:
#!/usr/bin/env python
# SPDX-License-Identifier: BSD-3-Clause
# Copyright(c) 2010-2014 Intel Corporation
# Copyright(c) 2017 Cavium, Inc. All rights reserved.
from __future__ import print_function
import sys
try:
xrange # Python 2
except NameError:
xrange = range # Python 3
sockets = []
cores = []
core_map = {}
base_path = "/sys/devices/system/cpu"
fd = open("{}/kernel_max".format(base_path))
max_cpus = int(fd.read())
fd.close()
for cpu in xrange(max_cpus + 1):
try:
fd = open("{}/cpu{}/topology/core_id".format(base_path, cpu))
except IOError:
continue
except:
break
core = int(fd.read())
fd.close()
fd = open("{}/cpu{}/topology/physical_package_id".format(base_path, cpu))
socket = int(fd.read())
fd.close()
if core not in cores:
cores.append(core)
if socket not in sockets:
sockets.append(socket)
key = (socket, core)
if key not in core_map:
core_map[key] = []
core_map[key].append(cpu)
print(format("=" * (47 + len(base_path))))
print("Core and Socket Information (as reported by '{}')".format(base_path))
print("{}\n".format("=" * (47 + len(base_path))))
print("cores = ", cores)
print("sockets = ", sockets)
print("")
max_processor_len = len(str(len(cores) * len(sockets) * 2 - 1))
max_thread_count = len(list(core_map.values())[0])
max_core_map_len = (max_processor_len * max_thread_count) \
+ len(", ") * (max_thread_count - 1) \
+ len('[]') + len('Socket ')
max_core_id_len = len(str(max(cores)))
output = " ".ljust(max_core_id_len + len('Core '))
for s in sockets:
output += " Socket %s" % str(s).ljust(max_core_map_len - len('Socket '))
print(output)
output = " ".ljust(max_core_id_len + len('Core '))
for s in sockets:
output += " --------".ljust(max_core_map_len)
output += " "
print(output)
for c in cores:
output = "Core %s" % str(c).ljust(max_core_id_len)
for s in sockets:
if (s,c) in core_map:
output += " " + str(core_map[(s, c)]).ljust(max_core_map_len)
else:
output += " " * (max_core_map_len + 1)
print(output)
OUTPUT:
[root@overcloud-compute-0 ~]# python cpu_topo.py
======================================================================
Core and Socket Information (as reported by '/sys/devices/system/cpu')
======================================================================
cores = [0, 1, 2, 3, 4, 5]
sockets = [0, 1]
Socket 0 Socket 1
-------- --------
Core 0 [0] [6]
Core 1 [1] [7]
Core 2 [2] [8]
Core 3 [3] [9]
Core 4 [4] [10]
Core 5 [5] [11]
上述输出的意义:
- 有两个 Socket(物理 CPU)
- 每个 Socket 有 6 个 Core(物理核),总计 12 个
Output:
[root@overcloud-compute-0 ~]# python cpu_topo.py
======================================================================
Core and Socket Information (as reported by '/sys/devices/system/cpu')
======================================================================
cores = [0, 1, 2, 3, 4, 5]
sockets = [0, 1]
Socket 0 Socket 1
-------- --------
Core 0 [0, 12] [6, 18]
Core 1 [1, 13] [7, 19]
Core 2 [2, 14] [8, 20]
Core 3 [3, 15] [9, 21]
Core 4 [4, 16] [10, 22]
Core 5 [5, 17] [11, 23]
上述输出的意义:
- 有两个 Socket(物理 CPU)
- 每个 Socket 有 6 个 Core(物理核),总计 12 个
- 每个 Core 有两个 Virtual Processor,总计 24 个
Nova 实现的 NUMA 亲和
在 Icehouse 版本之前,Nova 定义的 libvirt.xml,不会考虑 Host NUMA 的情况。导致 Libvirt 在默认情况下,有可能发生跨 NUMA node 获取 CPU/Memory 资源的情况,导致 Guest 性能下降。Openstack 在 Juno 版本中新增 NUMA 特性,用户可以通过将 Guest 的 vCPU/Memory 绑定到 Host NUMA Node上,以此来提升 Guest 的性能。
Nova 定义的 NUMA 对象概念
除了上文中提到的 NUMA 基本概念之外,Nova 还自定义一些对象概念:
- Cell:NUMA Node 的通名词,供 Libvirt API 使用
- vCPU:虚拟机的 CPU,根据虚拟机 NUMA 拓扑的不同,一个虚拟机 CPU 可以是一个 socket、core 或 thread。
- pCPU:宿主机的 CPU,根据宿主机 NUMA 拓扑的不同,一个物理机 CPU 同样可以是一个 socket、core 或 thread。
- Siblings Thread:兄弟线程,即由同一个 Core 超线程出来的 Threads。
- Host NUMA Topology:宿主机的 NUMA 拓扑。
- Guest NUMA Topology:虚拟机的 NUMA 拓扑。
NOTE 1:vCPU 和 pCPU 的定义具有一定的迷惑性,简单来理解:虚拟机实际是宿主机的一个进程,虚拟机 CPU 实际是宿主机进程中的一个特殊的线程。引入 pCPU 和 vCPU 的概念是为了让上层逻辑能够屏蔽机器 NUMA 拓扑的复杂性。
NOTE 2:Thread siblings 对象的引入是为了无论服务器是否开启了超线程,Nova 同样能够支持物理 CPU 绑定的功能。
实现 NUMA 亲和的背景
操作系统发行版许可证(Licensing)
根据不同的操作系统发行版许可证,可能会严格约束操作系统能够支持的最大 sockets 数量,同时也就约束了服务器上可运行虚拟机的数量。所以,此时应该更加偏向于使用 core 来作为 vCPU,而不是 socket。
因为许可证的影响,建议用户在上传镜像到 Glance 时,指明一个运行镜像最佳的 CPU 拓扑。云平台管理员也可以通过修改 CPU 拓扑的默认值来避免用户超出许可限制。也就是说,对于一个 4 vCPU 的虚拟机,如果使用的默认值限制最大 socket 为 2,则可以设置其 core 为 2(在 Socket 数量没有超出限制的前提下,虚拟机也能达到具有 4 Core 的效果)。
NOTE:OpenStack 管理员应该遵从操作系统许可需求,限制虚拟机使用的 CPU 拓扑(e.g. max_sockets==2)。设置默认的 CPU 拓扑参数,在保证 GuestOS 镜像能够满足许可证的同时,又不必让每个用户都单独去设置镜像属性。
CPU 拓扑对性能的影响
宿主机 CPU 拓扑的方式对其自身性能(Performance)具有很大影响。
-
单 Socket 单 Core 拓扑(单核结构):一个 Socket 只集成了一个 Core。对于多线程程序,主要是通过时间片轮转来获得 CPU 的执行权,实际上是串行执行,没有做到并行执行。

-
单 Socket 多 Core 拓扑(多核结构):一个 Socket 集成了多个水平对称(镜像)的 Core,Core 之间通过 CPU 内部数据总线通信。对于多线程程序,可以通过多 Core 实现真正的并行执行。不过对于并发数或线程数要大于 Core 数的程序而言,多核结构存在线程(上下文)切换问题。这会带来一定的开销,但好在使用的是 CPU 内部数据总线,所以开销会比较低。除此之外,还因为多 Core 是水平镜像的,所以每个 Core 都有着自己的 Cache,在某些需要使用共享数据(共享数据很可能会被 Cache 住)的场景中,存在多核 Cache 数据一致性的问题,这也会带来一些开销。
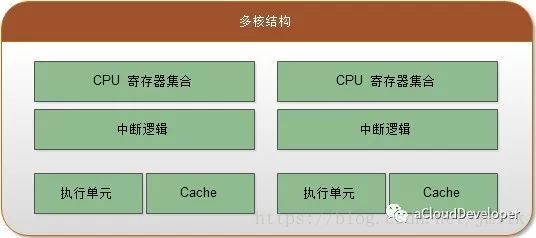
-
多 Socket 单 Core 拓扑: 多 Socket 之间通过主板上的总线进行通信,集成为一个统一的计算平台。每一个 Socket 都拥有独立的内部数据总线和 Cache。对于多线程程序,可以通过多 Socket 来实现并行执行。不同于单 Socket 多 Core 拓扑,多 Socket 单 Core 拓扑的线程切换以及 Socket 间通信走的都是外部总线,所以开销会比使用 CPU 内部数据总线高得多、延时也更长。当然,在使用共享数据的场景中,也同样存在多 Socket 间 Cache 一致性的问题。多 Socket 拓扑的性能瓶颈在于 Socket 间的 I/O 通讯成本。
-
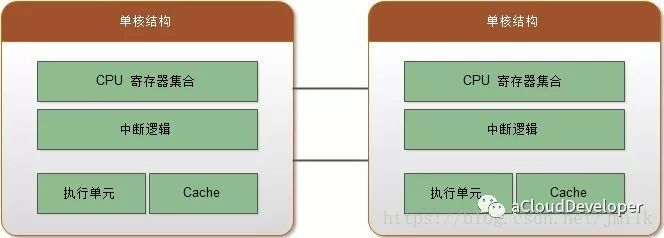
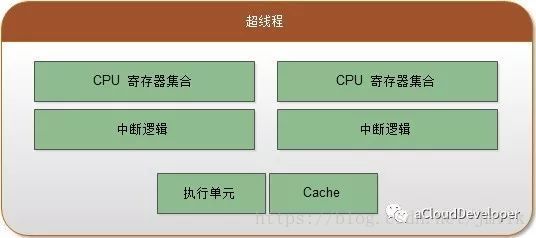
超线程拓扑(Hyper-Threading):将一个 Core 虚拟为多个 Thread(逻辑处理器),实现一个 Core 也可以并行执行多个线程。Thread 拥有自己的寄存器和中断逻辑,不过 Thread 间会共享执行单元(ALU 逻辑运算单元)和 Cache,所以性能提升是比较有限的,但也非常极致了。
-
超线程结构
-
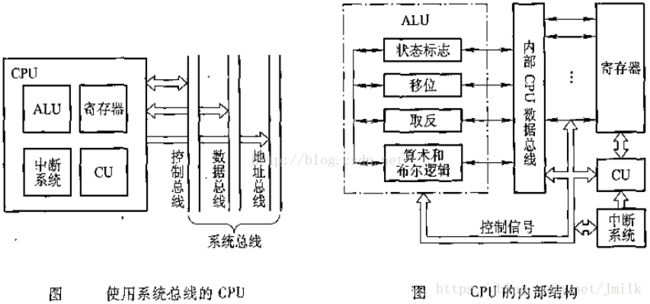
普通 CPU 内部结构
-
多 Socket 多 Core 超线程拓扑:具有多个 Socket,每个 Socket 又包含有多个 Core,每个 Core 有虚拟出多个 Thread。是上述拓扑类型的集大成者,拥有最好的性能和最先进的工艺,常见于企业级的服务器产品,例如:MPP、NUMA 计算平台系统。
NOTE 1:「多 Socket 单 Core 拓扑」的多线程,Socket 间协作要通过外部总线通信,在不同 Socket 上执行的线程间的共享数据可能会同时存放在不同的 Socket Cache 上,所以要保证不同 Cache 的数据一致性。具有通信开销大,线程切换开销大,Cache 数据一致性难维持,多 Socket 占位面积大,集成布线工艺难等问题。
NOTE 2:「单 Socket 多 Core 拓扑」的多线程,每个 Core 处理一个线程,支持并发。具有多 Core 之间通信开销小,Socket 占位面积小等优势。但是,当需要运行多个 “大程序”(一个程序就可以将内存、Cache、Core 占满)的话,就相当于多个大程序需要通过分时切片来使用 CPU。此时,程序间的上下文(指令、数据替换)切换消耗将会是巨大的。所以「单 Socket 多 Core 拓扑」在多任务、高并发、高消耗内存的程序运行环境中效率会变得非常低下(大程序会独占一个 Socket)。
综上,对于程序规模小的应用场景,建议使用「单 Socket 多 Core 拓扑」,例如个人 PC 的 Dell T3600(单 CPU 6 核,超线程支持虚拟出 12 颗逻辑核心);对于多大规模程序的应用场景(e.g. 云计算服务器端),建议使用「多 Socket 单 Core」甚至是「多 Socket 多 Core 超线程」的组合,为每个程序分配到单个 CPU,为每个程序的线程分配到单个 CPU 中的 Core。
CPU 架构对性能的影响
CPU 架构对于并发程序设计而言,主要需要考虑两个问题,一个是内存可见性问题,一个是 Cache 一致性问题。前者属于并发安全问题,后者则属于性能范畴的问题。

- 内存可见性问题:该问题在单处理器或单线程情况下是不会发生的。但在多线程环境中,因为线程会被分配到不同的 Core 上执行,所以会出现 Core1 和 Core2 可能会同时把主存中某个位置的值 load 到自己的一级缓存中,而 Core1 修改了自己一级缓存中的值后,却不更新主存中对应的值,这样对于 Core2 来说,将永远看不到 Core1 对值的修改,从而导致不能保证并发安全性。
- Cache 一致性问题:假如 Core1 和 Core2 同时把主存中的值 load 到自己的一级缓存,Core1 将值修改后,会通过 BUS 总线让 Core2 中的值失效。Core2 发现自己一级缓存中的值失效后,会再通过 BUS 总线从主存中得到最新的值。但是,总线的通信带宽是固定的,通过总线来进行各 CPU 一级缓存数据同步的动作会产生很大的流量,从而总线成为了性能的瓶颈。可以通过减小数据同步竞争来减少 Cache 一致性的流量。
超线程对性能的影响
需要注意的是,超线程技术并非万能药。从 Intel 和 VMware 对外公开的资料看,开启超线程后,Core 的总计算能力是否提升以及提升的幅度和业务模型相关,平均提升在 20%-30% 左右。但超线程对 Core 的执行资源的争抢,业务的执行时延也会相应增加。当超线程相互竞争时,超线程的计算能力相比不开超线程时的物理核甚至会下降 30% 左右。所以,超线程应该关闭还是开启,主要还是取决于应用模型。
现在很多应用,比如 Web App,大多会采用多 Worker 设计,在超线程的帮助下,两个被调度到同一个 Core 下不同 Thread 的 Worker,由于 Threads 共享 Cache,TLB(Translation Lookaside Buffer,转换检测缓冲区),所以能够大幅降低 Workers 线程切换的开销。另外,在某个 Worker 不忙的时候,超线程允许其它的 Worker 先使用物理计算资源,以此来提升 Core 的整体吞吐量。
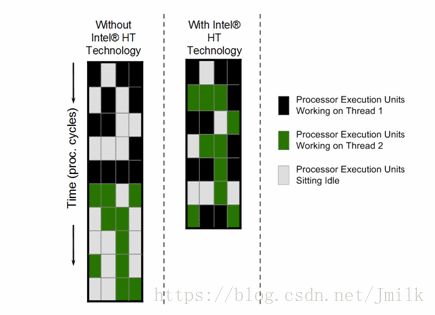
从上图可以看出,应用了 HT 技术的场景,处理器执行单元闲置的情况被有效减少了,而且 Thread 1 和 Thread 2 两个线程是被交叉处理的。
但由于 Threads 之间会争抢 Core 的物理执行资源,导致单个 Thread 的执行时延也会相应增加,响应速度不如当初。对于 CPU 密集型任务而言,当存在超线程竞争时,超线程计算能力大概是物理核的 60% 左右(非官方数据)。

NOTE:
- 对于时延敏感型任务,比如用户需要及时响应任务运行结果的场景,在节点负载过高,引发超线程竞争时,任务的执行时长会显著增加,导致影响用户体验。所以,不推荐计算密集型和时延敏感型任务使用超线程技术。
- 对于后台计算型任务,它不要求单个任务的响应速度,比如超算中心上运行的后台计算型任务(一般要运行数小时或数天),就建议开启超线程来提高整个计算节点的吞吐量。
回到虚拟机应用场景,当我们在 vSphere 的 ESXi 主机上运行两个 1 vCPU 的虚拟机,分别绑定到一个 Core 的两个 Thread 上,在虚拟机内部运行计算密集型的编译任务,并确保虚拟机内部 CPU 占用率在 50% 左右。从 ESXi 主机上看,两个 Thread 使用率在 45% 左右,但 Core 的负载就已经达到了 80%。可见,超线程竞争问题会让运行计算密集型应用的虚拟机性能损耗非常严重。
由此,需要注意,如果用户对虚拟机的性能要求比较高,那么不应该让虚拟机的 vCPU 运行在 Thread 上,而应该将 vCPU 运行在 Socket 或者 Core 上。对于开启了超线程的 Compute Node,应该提供一种机制能够将 Threads 过滤掉或抽象为一个 “Core”,这就是引入 Siblings Thread 的意义。
即便在对虚拟机性能要求不高的场景中,除非我们将虚拟机的 CPU 和宿主机的超线程一一绑定,否则并不建议应该使用超线程技术,pCPU 应该被映射为一个 Socket 或 Core。换句话说,如果我们希望开启 Nova Compute Node 的超线程功能,那么我会建议你使用 CPU 绑定功能来将虚拟机的 vCPU 绑定到某一个 pCPU(此时 pCPU 映射为一个 Thread)上。
NUMA Topology
现在的服务器基本都支持 NUMA 拓扑,上文已经提到过,主要驱动 NUMA 体系结构应用的因素是 NUMA 具有的高存储访问带宽、有效的 Cache 效率以及灵活 PCIe I/O 设备的布局设计。但由于 NUMA 跨节点远程内存访问不仅延时高、带宽低、消耗大,还可能需要处理数据一致性的问题。因此,虚拟机的 vCPU 和内存在 NUMA 节点上的错误布局,将会导宿主机资源的严重浪费,这将抹掉任何内存与 CPU 决策所带来的好处。所以,标准的策略是尽量将一个虚拟机完全局限在单个 NUMA 节点内。
Guest NUMA Topology
将虚拟机的 vCPU/Mem 完全局限在单个 NUMA 节点内是最佳的方案,但假如分配给虚拟机的 vCPU 数量以及内存大小超过了一个 NUMA 节点所拥有的资源呢?此时必须针对大资源需求的虚拟机设计出合适的策略,Guest NUMA Topology 的概念也是为此而提出。
这些策略或许禁止创建超出单一 NUMA 节点拓扑的虚拟机,或许允许虚拟机跨多 NUMA 节点运行。并且在虚拟机迁移时,允许更改这些策略。也就是说,在对宿主机(Compute Node)进行维护时,接收临时降低性能而选择次优的 NUMA 拓扑布局。当然了,NUMA 拓扑布局的问题还需要考虑到虚拟机的具体使用场景,例如,NFV 虚拟机的部署就会强制的要求严格的 NUMA 拓扑布局。
如果虚拟机具有多个 Guest NUMA Node,为了让操作系统能最大化利用其分配到的资源,宿主机的 NUMA 拓扑就必须暴露给虚拟机。让虚拟机的 Guest NUMA Node 与宿主机的 Host NUMA Node 进行关联映射。这样可以映射大块的虚拟机内存到宿主机内存,和设置 vCPU 与 pCPU 的映射。
Guest NUMA Topology 实际上是将一个大资源需求的虚拟机划分为多个小资源需求的虚拟机,将多个 Guest NUMA Node 分别绑定到不同的 Host NUMA Node。这样做是因为虚拟机内部运行的工作负载同样会遵守 NUMA 节点原则,最终的效果实际上就是虚拟机的工作负载依旧有效的被限制在了一个 Host NUMA Node 内。也就是说,如果虚拟机有 4 vCPU 需要跨两个 Host NUMA Node,vCPU 0/1 绑定到 Host NUMA Node 1,而 vCPU 2/3 绑定到 Host NUMA Node 2 上。然后虚拟机内的 DB 应用分配到 vCPU 0/1,Web 应用分配到 vCPU 2/3,这样实际就是 DB 应用和 Web 应用的线程始终被限制在了同一个 Host NUMA Node 上。但是,Guest NUMA Topology 并不强制将 vCPU 与对应的 Host NUMA Node 中特定的 pCPU 进行绑定,这可以由操作系统调度器来隐式完成。只是如果宿主机开启了超线程,则要求将超线程特性暴露给虚拟机,并在 NUMA Node 内绑定 vCPU 与 pCPU 的关系。否则 vCPU 会被分配给 Siblings Thread,由于超线程竞争,性能远不如将 vCPU 分配到 Socket 或 Core 的好。
NOTE:如果 Guest vCPU/Mem 需求超过了单个 Host NUAM Node,那么应该将 Guest NUMA Topology 划分为多个 Guest NUMA Node,并分别映射到不同的 Host NUMA Node 上。
在 Nova 上应用 NUMA 亲和来创建高性能虚拟机
首先判断该物理服务器是否支持 NUMA 功能:
$ dmesg | grep -i numa
[ 0.000000] Enabling automatic NUMA balancing. Configure with numa_balancing= or the kernel.numa_balancing sysctl
[ 0.674375] pci_bus 0000:00: on NUMA node 0
[ 0.678884] pci_bus 0000:40: on NUMA node 1
[ 0.682517] pci_bus 0000:3f: on NUMA node 0
[ 0.686182] pci_bus 0000:7f: on NUMA node 1
如果输出上述内容则表示支持 NUMA,如果输出 No NUMA configuration found 则表示不支持。
查看物理服务器的 NUMA 拓扑:
$ yum install -y numactl
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6
node 0 size: 32690 MB
node 0 free: 19579 MB
node 1 cpus: 1 3 5 7
node 1 size: 32768 MB
node 1 free: 19208 MB
node distances:
node 0 1
0: 10 20
1: 20 10
使用 numactl 指令可以查看 NUMA 的节点及各节点上逻辑 CPU 和 RAM 的情况。
查看物理服务器是否开启了超线程:可以直接执行上述 cpu_topo 脚本,也可以手动执行以下指令来判断。
# 查看物理服务器的 Socket 数量
cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
# 查看每个 Socket 的 Core 数量
cat /proc/cpuinfo | fgrep "cores" | uniq
# 查看每个 Socket 的 Siblings 数量
grep "siblings" /proc/cpuinfo|uniq
# 查看 Processor 的总数
cat /proc/cpuinfo | grep "processor" | wc -l
如果 Processors == Sockets * Cores,则表示超线程没有开启。如果 Processors 是 Sockets * Cores 的倍数,则表示开启了超线程。或者说如果每个 Socket 的 Siblings 与 Core 的数量相同,表示没有开启超线程(Core 没有 virtual processor)。
查看各逻辑 CPU 的使用情况:
$ yum install -y sysstat
$ mpstat -P ALL
Linux 3.10.0-957.1.3.el7.x86_64 (localhost) 01/19/2019 _x86_64_ (8 CPU)
03:06:35 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
03:06:35 AM all 4.35 0.00 1.73 0.32 0.00 0.02 0.00 0.77 0.00 92.80
03:06:35 AM 0 3.78 0.00 1.52 0.44 0.00 0.05 0.00 0.86 0.00 93.36
03:06:35 AM 1 5.02 0.00 1.64 0.40 0.00 0.02 0.00 0.10 0.00 92.83
03:06:35 AM 2 4.73 0.00 2.15 0.23 0.00 0.02 0.00 0.82 0.00 92.05
03:06:35 AM 3 6.09 0.00 2.14 0.41 0.00 0.02 0.00 0.11 0.00 91.24
03:06:35 AM 4 4.00 0.00 1.65 0.17 0.00 0.02 0.00 0.77 0.00 93.39
03:06:35 AM 5 4.24 0.00 1.65 0.41 0.00 0.01 0.00 0.36 0.00 93.33
03:06:35 AM 6 3.20 0.00 1.57 0.12 0.00 0.02 0.00 2.70 0.00 92.39
03:06:35 AM 7 3.76 0.00 1.55 0.41 0.00 0.01 0.00 0.45 0.00 93.82
nova-scheduler 启用 NUMATopologyFilter:
# nova.conf
[DEFAULT]
...
scheduler_default_filters=...,NUMATopologyFilter
Nova 的 NUMA 亲和原则是:将 Guest vCPU/Mem 都分配在同一个 NUMA Node 上,充分使用 NUMA node local memory,避免跨 Node 访问 remote memory。
openstack flavor set FLAVOR-NAME \
--property hw:numa_nodes=FLAVOR-NODES \
--property hw:numa_cpus.N=FLAVOR-CORES \
--property hw:numa_mem.N=FLAVOR-MEMORY
- FLAVOR-NODES(整数):设定 Guest NUMA nodes 的个数。如果不指定,则 Guest vCPUs 可以在任意可用的 Host NUMA nodes 上浮动。
- N:整数,Guest NUMA nodes ID,取值范围在 [0, FLAVOR-NODES-1]。
- FLAVOR-CORES(逗号分隔的整数):设定分配到 Guest NUMA node N 上运行的 vCPUs 列表。如果不指定,vCPUs 在 Guest NUMA nodes 之间平均分配。
- FLAVOR-MEMORY(整数):单位 MB,设定分配到 Guest NUMA node N 上 Memory Size。如果不指定,Memory 在 Guest NUMA nodes 之间平均分配。
设定 Guest NUMA Topology 的两种方式:
- 自动设定 Guest NUMA Topology:仅仅需要指定 Guest NUMA nodes 的个数,然后由 Nova 根据 Flavor 设定的虚拟机规格平均将 vCPU/Mem 分布到不同的 Host NUMA nodes 上(默认从 Host NUMA node 0 开始分配)。
NOTE:选择使用自动设定方式时,建议一同使用 hw:numa_mempolicy 属性,表示 NUMA 的 Mem 访问策略,有严格访问本地内存的 strict 和宽松的 preferred 两种选择,这样可以最大程度降低配置参数的复杂性。而且对于某些特定工作负载的 NUMA 架构问题,比如:MySQL “swap insanity” 问题 ,或许 preferred 会是一个不错的选择。
- 手动设定 Guest NUMA Topology:不仅指定 Guest NUMA nodes 的个数,还需要通过
hw:numa_cpus.N和hw:numa_mem.N来指定每个 Guest NUMA nodes 上分配的 vCPUs 和 Memory Size。
Nova Scheduler 会根据参数 hw:numa_nodes 来决定如何映射 Guest NUMA node。如果没有设置该参数,那么 Scheduler 将自由的决定在哪里运行虚拟机,而无需关心单个 NUMA 节点是否能够满足虚拟机 flavor 中的 vCPU/Mem 配置,但仍会优先考虑选出一个 NUMA 节点就可以满足情况的计算节点。
- 如果 numa_nodes = 1,Scheduler 将会选择出单个 NUMA 节点能够满足虚拟机 flavor 配置的计算节点。
- 如果 numa_nodes > 1,Scheduler 将会选择出 NUMA 节点数量以及 NUMA 节点中资源情况能够满足虚拟机 flavor 配置的计算节点。
NOTE 1:只有在设定了 hw:numa_nodes 后,hw:numa_cpus.N 和 hw:numa_mem.N 才会生效。只有当 Guest NUMA nodes 存在非对称访问 vCPU/Mem 时(Guest NUMA Nodes 之间拥有的 vCPU 数量和 Mem 大小并非是镜像的),才需要去设定这些参数。
NOTE 2:N 仅仅是 Guest NUMA node 的索引,并非实际上的 Host NUMA node 的 ID。例如,Guest NUMA node 0,可能会被映射到 Host NUMA node 1。类似的,FLAVOR-CORES 的值也仅仅是 vCPU 的索引。因此,Nova 的 NUMA 特性并不能用来约束 Guest vCPU/Mem 绑定到指定的 Host NUMA node 上。要完成 vCPU 绑定到指定的 pCPU,需要借助 CPU Pinning policy 机制。
WARNING:如果 hw:numa_cpus.N 和 hw:numa_mem.N 的设定值大于虚拟机本身可用的 CPUs/Mem,则触发异常。
EXAMPLE:定义虚拟机有 4 vCPU,4096MB Mem,设定 Guest NUMA topology 为 2 Guest NUMA node:
- Guest NUMA node 0:vCPU 0、Mem 1024MB
- Guest NUMA node 1:vCPU 1/2/3、Mem 3072MB
openstack flavor set aze-FLAVOR \
--property hw:numa_nodes=2 \
--property hw:numa_cpus.0=0 \
--property hw:numa_cpus.1=1,2,3 \
--property hw:numa_mem.0=1024 \
--property hw:numa_mem.1=3072 \
NOTE:numa_cpus 指定的是 vCPUs 的序号,而非 pCPUs。
使用该 flavor 创建的虚拟机时,最后由 Libvirt Driver 完成将 Guest NUMA node 映射到 Host NUMA node 上。
除了通过 Flavor extra-specs 来设定 Guest NUMA topology 之外,还可以通过 Image Metadata 来设定。e.g.
glance image-update --property \
hw_numa_nodes=2 \
hw_numa_cpus.0=0 \
hw_numa_mem.0=1024 \
hw_numa_cpus.1=1,2,3 \
hw_numa_mem.1=3072 \
image_name
注意,当镜像的 NUMA 约束与 Flavor 的 NUMA 约束冲突时,以 Flavor 为准。
NOTE 1:KVM 的宿主机会暴露出 Host NUMA Topology 的细节(e.g. NUMA 节点数量,NUMA 节点的内存 total 和 free,NUMA 节点的 CPU total 和 free),但其他 Hypervisor 的操作系统平台未必会将这些信息暴露出来,比如 VMware 只能通过 vSphere WS API 来获得并不 “完整” 的拓扑信息。所以,NUMA 亲和特性适配度最高的还是 KVM。
NOTE 2:nova-compute service 的 ResourceTracker 通过 Hyper Driver 定时收集宿主机的 Host NUMA Topology 信息。
Nova 使用 NUMA 和 CPU Binding 的 EXAMPLE
Step 1. 首先查看当前物理服务器的 NUMA 拓扑
[root@localhost ~]# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6
node 0 size: 32690 MB
node 0 free: 19626 MB
node 1 cpus: 1 3 5 7
node 1 size: 32768 MB
node 1 free: 19146 MB
node distances:
node 0 1
0: 10 20
1: 20 10
[root@localhost ~]# bash numa_topo.sh
===== CPU Topology Table =====
+--------------+---------+-----------+
| Processor ID | Core ID | Socket ID |
+--------------+---------+-----------+
| 0 | 0 | 0 |
+--------------+---------+-----------+
| 1 | 0 | 1 |
+--------------+---------+-----------+
| 2 | 1 | 0 |
+--------------+---------+-----------+
| 3 | 1 | 1 |
+--------------+---------+-----------+
| 4 | 2 | 0 |
+--------------+---------+-----------+
| 5 | 2 | 1 |
+--------------+---------+-----------+
| 6 | 3 | 0 |
+--------------+---------+-----------+
| 7 | 3 | 1 |
+--------------+---------+-----------+
Socket 0: 0 2 4 6
Socket 1: 1 3 5 7
===== CPU Info Summary =====
Logical processors: 8
Physical socket: 2
Siblings in one socket: 4
Cores in one socket: 4
Cores in total: 8
Hyper-Threading: off
===== END =====
显而易见,当前物理服务器具有 2 个 NUMA Node,详情为:
- 2 Socket
- 4 Core/Socket
- 1 Processor/Core(Hyper-Threading off)
- 8 Processors
Step 2. 查看逻辑 CPU 的空闲情况
[root@localhost ~]# mpstat -P ALL
Linux 3.10.0-957.1.3.el7.x86_64 (localhost) 01/19/2019 _x86_64_ (8 CPU)
03:21:19 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
03:21:19 AM all 4.35 0.00 1.73 0.32 0.00 0.02 0.00 0.77 0.00 92.80
03:21:19 AM 0 3.78 0.00 1.52 0.44 0.00 0.05 0.00 0.86 0.00 93.36
03:21:19 AM 1 5.02 0.00 1.64 0.40 0.00 0.02 0.00 0.10 0.00 92.83
03:21:19 AM 2 4.73 0.00 2.15 0.23 0.00 0.02 0.00 0.82 0.00 92.05
03:21:19 AM 3 6.09 0.00 2.14 0.41 0.00 0.02 0.00 0.11 0.00 91.24
03:21:19 AM 4 4.00 0.00 1.65 0.17 0.00 0.02 0.00 0.77 0.00 93.39
03:21:19 AM 5 4.24 0.00 1.65 0.41 0.00 0.01 0.00 0.36 0.00 93.33
03:21:19 AM 6 3.20 0.00 1.57 0.12 0.00 0.02 0.00 2.70 0.00 92.39
03:21:19 AM 7 3.76 0.00 1.55 0.41 0.00 0.01 0.00 0.45 0.00 93.82
从 %idle 字段可以看出 8 个逻辑 CPU 都比较空闲,可以任意使用。
Step 3. 启用 NUMATopologyFilter
vim /etc/nova/nova.conf
[filter_scheduler]
...
enabled_filters = ...,NUMATopologyFilter
重启 nova-scheduler 服务
systemctl restart devstack@n-sch
Step 4. 创建 Nova Flavor
[root@localhost ~]# openstack flavor create --ram 2048 --disk 20 --vcpus 2 2C2G20D-NUMA-CPU_binding
+----------------------------+--------------------------------------+
| Field | Value |
+----------------------------+--------------------------------------+
| OS-FLV-DISABLED:disabled | False |
| OS-FLV-EXT-DATA:ephemeral | 0 |
| disk | 20 |
| id | 95c75cca-f864-4d8d-ae25-c1544de8af53 |
| name | 2C2G20D-NUMA-CPU_binding |
| os-flavor-access:is_public | True |
| properties | |
| ram | 2048 |
| rxtx_factor | 1.0 |
| swap | |
| vcpus | 2 |
+----------------------------+--------------------------------------+
Step 5. Setup Guest NUMA Topo
[root@localhost ~]# openstack flavor set 2C2G20D-NUMA-CPU_binding \
> --property hw:numa_nodes=2 \
> --property hw:numa_cpus.0=0 \
> --property hw:numa_cpus.1=1 \
> --property hw:numa_mem.0=1024 \
> --property hw:numa_mem.1=1024
Step 6. Setup CPU Binding Policy
[root@localhost ~]# openstack flavor set 2C2G20D-NUMA-CPU_binding \
> --property hw:cpu_policy=dedicated \
> --property hw:cpu_thread_policy=isolate
Step 7. 启动测试虚拟机
$ openstack server create --image cirros-0.3.4-x86_64-disk --network web-server-net --flavor 2C2G20D-NUMA-CPU_binding VM1
+-------------------------------------+-----------------------------------------------------------------+
| Field | Value |
+-------------------------------------+-----------------------------------------------------------------+
| OS-DCF:diskConfig | MANUAL |
| OS-EXT-AZ:availability_zone | |
| OS-EXT-SRV-ATTR:host | None |
| OS-EXT-SRV-ATTR:hypervisor_hostname | None |
| OS-EXT-SRV-ATTR:instance_name | |
| OS-EXT-STS:power_state | NOSTATE |
| OS-EXT-STS:task_state | scheduling |
| OS-EXT-STS:vm_state | building |
| OS-SRV-USG:launched_at | None |
| OS-SRV-USG:terminated_at | None |
| accessIPv4 | |
| accessIPv6 | |
| addresses | |
| adminPass | v2NfftjquA4K |
| config_drive | |
| created | 2019-01-19T08:47:36Z |
| flavor | 2C2G20D-NUMA-CPU_binding (95c75cca-f864-4d8d-ae25-c1544de8af53) |
| hostId | |
| id | 84df4e16-c1e0-476e-8f5b-f13c656e768c |
| image | cirros-0.3.4-x86_64-disk (60076364-c413-47f2-badf-48e03acb47da) |
| key_name | None |
| name | VM1 |
| progress | 0 |
| project_id | 12b567f21ed04e80b5c3f24717507464 |
| properties | |
| security_groups | name='default' |
| status | BUILD |
| updated | 2019-01-19T08:47:36Z |
| user_id | 5ce6578ec1424796b6c883f06fcf834f |
| volumes_attached | |
+-------------------------------------+-----------------------------------------------------------------+
Step 8. 查看虚拟机的 CPU 绑定情况
[root@localhost ~]# virsh list
Id Name State
----------------------------------------------------
8 instance-0000000c running
[root@localhost ~]# virsh vcpuinfo instance-0000000c
VCPU: 0
CPU: 2
State: running
CPU time: 3.0s
CPU Affinity: --y-----
VCPU: 1
CPU: 5
State: running
CPU time: 1.0s
CPU Affinity: -----y--
一颗 vCPU 绑定在 Processor 2,另一颗绑定在 Processor 5,在两个不同的 NUMA node 上。
TS1:Requested instance NUMA topology cannot fit the given host NUMA topology.
如果你创建虚拟机失败,并且在 nova-conductor service 的日志看见 Requested instance NUMA topology cannot fit the given host NUMA topology,那么你或许应该检查一下 nova-scheduler service 是否启用了 NUMATopologyFilter 以及可以检查一下是否还具有足够的 NUMA 资源了。
TS2:Filter NUMATopologyFilter returned 0 hosts
如果你创建虚拟机是被,并且在 nova-scheduler service 的日志看见 Filter NUMATopologyFilter returned 0 hosts,则表示 ComputeNodes 已经没有足够的 NUMA 资源了。或者你可以考虑使用 hw:cpu_policy=shared 不独占 CPU 的策略。