Oozie的简单使用
1、Oozie的介绍
Oozie是一个工作流引擎服务器,用于运行Hadoop Map/Reduce和Hive等任务工作流.同时Oozie还是一个Java Web程序,运行在Java Servlet容器中,如Tomcat中。Oozie以action为基本任务单位,可以将多个action构成一个DAG图(有向无环图Direct Acyclic Graph)的模式进行运行。Oozie工作流通过HPDL(一种通过XML自定义处理的语言)来构造Oozie的工作流。一个oozie服务器主要包括四个服务:Oozie Workflow、Oozie Coordinator、Oozie Bundle和Oozie SLA(oozie服务器等级协定)。
1.1 Oozie四大组件服务介绍
- Oozie Workflow: 该组件用于定义和执行一个特定顺序的mapreduce、hive和pig作业。
- Oozie Coordinator:该组件用于支持基于事件、系统资源存在性等条件的workflow的自动化执行。
- Oozie Bundle:该引擎可以定义和执行"一束"应用,从而提供一个批量化的方法,将一组Coordinator应用程序一起进行管理。
- Oozie服务器等级协定(Service Level Agreement, SLA):该组件支持workflow应用程序执行过程的记录跟踪。
workflow是oozie中最基本的一个服务组件。三大服务的的关系是:bundle包含多个coordinator,coordinator包含一个workflow,workflow定义具体的action动作。

1.2 Workflow介绍
workflow使用hadoop流程定义语言(Hadoop Process Defination Language, hPDL)来描述工作流,hPDL是类似xml语言的一种相当简洁的定义类语言,使用有限数目的流控制节点和动作节点来描述workflow,说也就是workflow有两大类节点构成:工作流控制节点和动作节点。其中工作流控制节点是workflow本身提供的一种控制workflow工作流执行路径的方法,不可以自定义;动作节点是具体的操作方法,用户可以自定义。
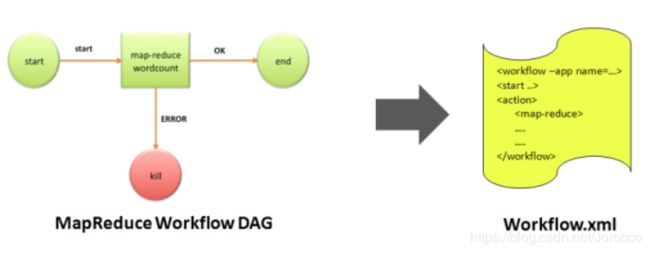
1.3 Workflow工作流生命周期

1.4 Workflow流控制节点

1.5 Workflow默认支持的action动作节点

1.6 Workflow扩展的action动作节点

1.7 Workflow异步操作
Workflow中的所有异步操作(action)都需要在hadoop集群上以mapreduce作业的方式进行执行,这样充分利用了集群的优点。oozie通过两种方式来检查任务是否完成: - 回调:当一个任务和一个计算被启动后,会为任务提供一个回调url,该任务执行完成后,会执行回调来通知oozie。
- 轮询:在任务执行回调失败的情况下,无论任何原因,都支持以轮询的方式进行查询。 oozie提供这两种方式来控制任务,将资源密集型的任务放到服务节点之外,使oozie节约服务器资源,确保单个oozie服务器可以支持上千个作业。
注意: 需要hadoop集群开启hdfs、yarn和jobhistory服务。
1.8 Workflow规则
workflow任务主要由job.properties、workflow.xml和其他动作需要的资源文件三部分组成,其中job.properties中定义workflow作业的配置信息,workflow.xml定义作业的执行工作流。workflow.xml文件是一个有定义规则的xml文件。
workflow.xml配置规则详见:workflow中的文档workflow.template.xml
job.properties配置参考:workflow中的文档job.template.properties
1.9 Coordinator介绍
coordinator支持workflow过程的自动启动,常用于一些由时间/数据可用性来触发的、会多次调用的workflow过程的设计和执行。通过定义多个顺序运行的、前一个输出作为后一个输入的workflow,coordinator也支持定义常规运行的(包括以不同时间间隔运行的)workflow作业之间的依赖。
1.10 Bundle介绍
Oozie Bundle是顶层抽象,允许将一组coordinator任务打包成为一个bundle任务。组成一个整体bundle的多个coordinator可以作为一个整体来进行控制,包括启动、停止、挂起、继续、重新执行等操作。Bundle中不支持它的coordinator应用程序之间的显示依赖关系,如果需要定义这些依赖关系,可以在 coordinator中通过输入输出事件来指定依赖。
2. Oozie的安装
Oozie使用tomcat等服务器作为web界面展示容器,使用关系型数据库存储oozie的工作流元数据,默认使用debry,由于debry的缺点,一般情况使用mysql作为oozie的元数据库,使用extjs来作为报表展示js框架。
安装步骤:
- 安装mysql
- 安装tomcat
- 安装oozie
2.1 Tomcat安装
- 下载tomcat压缩包:
wget http://archive.apache.org/dist/tomcat/tomcat-7/v7.0.8/bin/apache-tomcat-7.0.8.tar.gz - 解压压缩包
- 设置环境变量
- 启动tomcat测试是否安装成功。
2.2 Oozie安装
- 下载oozie和ext-2.2.zip
- 设置环境变量
export OOZIE_HOME=/home/hadoop/bigdater/oozie-4.0.0-cdh5.3.6
export PATH=$PATH:$OOZIE_HOME/bin
- 进行conf配置信息修改,修改conf/oozie-site.xml文件,主要就是进行元数据指定和service指定。
oozie-site.xml
oozie.services
org.apache.oozie.service.JobsConcurrencyService,
org.apache.oozie.service.SchedulerService,
org.apache.oozie.service.InstrumentationService,
org.apache.oozie.service.MemoryLocksService,
org.apache.oozie.service.CallableQueueService,
org.apache.oozie.service.UUIDService,
org.apache.oozie.service.ELService,
org.apache.oozie.service.AuthorizationService,
org.apache.oozie.service.UserGroupInformationService,
org.apache.oozie.service.HadoopAccessorService,
org.apache.oozie.service.URIHandlerService,
org.apache.oozie.service.DagXLogInfoService,
org.apache.oozie.service.SchemaService,
org.apache.oozie.service.LiteWorkflowAppService,
org.apache.oozie.service.JPAService,
org.apache.oozie.service.StoreService,
org.apache.oozie.service.CoordinatorStoreService,
org.apache.oozie.service.SLAStoreService,
org.apache.oozie.service.DBLiteWorkflowStoreService,
org.apache.oozie.service.CallbackService,
org.apache.oozie.service.ActionService,
org.apache.oozie.service.ShareLibService,
org.apache.oozie.service.ActionCheckerService,
org.apache.oozie.service.RecoveryService,
org.apache.oozie.service.PurgeService,
org.apache.oozie.service.CoordinatorEngineService,
org.apache.oozie.service.BundleEngineService,
org.apache.oozie.service.DagEngineService,
org.apache.oozie.service.CoordMaterializeTriggerService,
org.apache.oozie.service.StatusTransitService,
org.apache.oozie.service.PauseTransitService,
org.apache.oozie.service.GroupsService,
org.apache.oozie.service.ProxyUserService,
org.apache.oozie.service.XLogStreamingService,
org.apache.oozie.service.JvmPauseMonitorService
oozie.service.HadoopAccessorService.hadoop.configurations
*=/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/etc/hadoop
oozie.service.JPAService.create.db.schema
true
oozie.service.JPAService.jdbc.driver
com.mysql.jdbc.Driver
oozie.service.JPAService.jdbc.url
jdbc:mysql://hh:3306/oozie?createDatabaseIfNotExist=true
oozie.service.JPAService.jdbc.username
hive
oozie.service.JPAService.jdbc.password
hive
oozie.service.JPAService.jdbc.password
hive
oozie.processing.timezone
GMT+0800
oozie.service.SchemaService.wf.ext.schemas
oozie-sla-0.1.xsd,shell-action-0.1.xsd,hive-action-0.2.xsd
oozie.service.ActionService.executor.ext.classes
org.apache.oozie.action.hadoop.ShellActionExecutor,
org.apache.oozie.action.hadoop.HiveActionExecutor
oozie.service.coord.check.maximum.frequency
false
- 可以在conf/oozie-env.sh中进行参数修改,比如修改端口号,默认端口号为11000
- oozie根目录创建libext文件夹,复制mysql的driver压缩包到libext文件夹中
cp ~/bigdater/hive-0.13.1-cdh5.3.6/lib/mysql-connector-java-5.1.31.jar ./libext/
or
cp ~/bigdater/softs/mysql-connector-java-5.1.31.jar ./libext/
- 执行sql创建,执行完成后,mysql中出现数据库和数据表
在oozie的根目录下执行命令:ooziedb.sh create -sqlfile oozie.sql -run
- 在hadoop的core-site.xml里设置hadoop代理用户
hadoop.proxyuser.hadoop.hosts&hadoop.proxyuser.hadoop.groups
- 在hdfs上创建公用文件夹share
oozie根目录下执行命令:oozie-setup.sh sharelib create -fs hdfs://hh:8020 -locallib oozie-sharelib-4.0.0-cdh5.3.6-yarn.tar.gz
- 创建war文件
执行addtowar.sh -inputwar ./oozie.war -outputwar ./oozie-server/webapps/oozie.war -hadoop 2.5.0 $HADOOP_HOME -jars ./libext/mysql-connector-java-5.1.31.jar -extjs ../softs/ext-2.2.zip
或者
将hadoop相关包,mysql相关包和ext压缩包放到libext文件夹中,运行oozie-setup.sh prepare-war也可以创建war文件
- 运行
oozie的bin目录下执行:oozied.sh run 或者 oozied.sh start(前者在前端运行,后者在后台运行)
- 查看web界面&查看状态
oozie admin -oozie http://hh:11000/oozie -status
3. 案例介绍
- 定义fs动作,在hdfs文件系统上进行文件操作
job.properties
nameNode=hdfs://hh:8020
jobTracker=hh:8032
examplesRoot=fs
oozie.wf.application.path=${nameNode}/oozie/workflows/${examplesRoot}
workflow.xml
script failed, error message:${wf:errorMessage(wf:lastErrorNode())}
注意:需要先在本地机器上的~/jobs/oozie文件夹中创建比如fs文件夹,并将job.properties、workflow.xml放入该fs文件夹中,下面的类似。
- 定义fs动作,判断文件夹存在,就删除,如果不存在,不进行任何操作
job.properties
nameNode=hdfs://hh:8020
jobTracker=hh:8032
examplesRoot=fs2
oozie.wf.application.path=${nameNode}/oozie/workflows/${examplesRoot}
workflow.xml
${fs:exists("/beifeng/18")}
script failed, error message:${wf:errorMessage(wf:lastErrorNode())}
- 定义shell动作,在服务器的tmp目录下创建一个文件夹
job.properties
nameNode=hdfs://hh:8020
jobTracker=hh:8032
examplesRoot=shell
EXEC=script.sh
oozie.wf.application.path=${nameNode}/oozie/workflows/${examplesRoot}
workflow.xml
${jobTracker}
${nameNode}
${EXEC}
${EXEC}#${EXEC}
script failed, error message:${wf:errorMessage(wf:lastErrorNode())}
script.sh
mkdir /tmp/beifeng-net
- 定义hive动作,执行sql脚本,将数据导入到hive中的表中
job.properties
nameNode=hdfs://hh:8020
jobTracker=hh:8032
examplesRoot=hive
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/oozie/workflows/${examplesRoot}
workflow.xml
${jobTracker}
${nameNode}
oozie.hive.defaults
hive-site.xml
hive.metastore.local
false
hive.metastore.uris
thrift://hh:9083
hive.metastore.warehouse.dir
/hive
script failed, error message:${wf:errorMessage(wf:lastErrorNode())}
hive-site.xml
hive.metastore.uris
thrift://hh:9083
hive.metastore.warehouse.dir
/hive
javax.jdo.option.ConnectionURL
jdbc:mysql://hh:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
hive
javax.jdo.option.ConnectionPassword
hive
d.sql
load data inpath '/data.txt' into table t
data.txt
1
2
3
4
5
6
7
10
- 定义mapreduce动作,执行mapreduce任务
job.properties
nameNode=hdfs://hh:8020
jobTracker=hh:8032
queueName=default
examplesRoot=map-reduce
oozie.wf.application.path=${nameNode}/oozie/workflows/${examplesRoot}
workflow.xml
${jobTracker}
${nameNode}
mapred.mapper.new-api
true
mapred.reducer.new-api
true
mapreduce.job.map.class
com.beifeng.mr.wordcount.WordCountMapper
mapreduce.job.reduce.class
com.beifeng.mr.wordcount.WordCountReducer
mapreduce.input.fileinputformat.inputdir
/beifeng/api
mapreduce.job.output.key.class
org.apache.hadoop.io.Text
mapreduce.job.output.value.class
org.apache.hadoop.io.LongWritable
mapreduce.output.fileoutputformat.outputdir
/beifeng/wordcount/18
mapreduce.job.acl-view-job
*
oozie.launcher.mapreduce.job.acl-view-job
*
${wf:errorCode("wordcount")}
直接将这些文件夹上传到linux机器上(比如上传到~/jobs/oozie文件夹中),然后将所有软件上传到hdfs的/oozie/workflows文件夹中。进入linux上传的目录(这里是jobs/oozie文件夹)执行命令:
oozie job -oozie http://hh:11000/oozie -config ./xxxx/job.properties -run,这里的xxxx就是各个文件夹名称
其他相关命令:
oozie job -oozie http://hh:11000/oozie -config ./xxxx/job.properties -submit (提交任务)
oozie job -oozie http://hh:11000/oozie -start job_id (运行已经提交的任务)
oozie job -oozie http://hh:11000/oozie -config ./xxxx/job.properties -run (submit和start命令合并)
oozie job -oozie http://hh:11000/oozie -info job_id (获取任务信息)
oozie job -oozie http://hh:11000/oozie -suspend job_id (暂停/挂起任务)
oozie job -oozie http://hh:11000/oozie -rerun job_id (重新运行暂停的任务)
- 定时任务,coordinate的使用案例cron
job.properties
nameNode=hdfs://hh:8020
jobTracker=hh:8030
queueName=default
examplesRoot=cron
oozie.service.coord.check.maximum.frequency=false
oozie.coord.application.path=${nameNode}/oozie/workflows/${examplesRoot}
start=2015-11-22T08:06+0800
end=2015-11-25T08:10+0800
workflowAppUri=${oozie.coord.application.path}
workflow.xml
coordinator.xml
${workflowAppUri}
jobTracker
${jobTracker}
nameNode
${nameNode}
queueName
${queueName}