机器学习.周志华《16 强化学习 》
强化学习(再励学习)
任务与奖赏
强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。
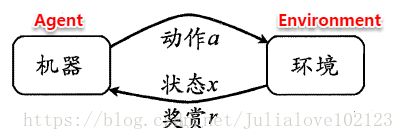
强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
状态(X):机器对环境的感知,所有可能的状态称为状态空间;
动作(A):机器所采取的动作,所有能采取的动作构成动作空间;
转移概率(P):当执行某个动作后,当前状态会以某种概率转移到另一个状态;
奖赏函数(R):在状态转移的同时,环境给反馈给机器一个奖赏。
强化学习的主要任务:通过在环境中不断地尝试,根据尝试获得的反馈信息调整策略,最终生成一个较好的策略π,机器根据这个策略便能知道在什么状态下应该执行什么动作。
常见的策略表示方法有以下两种:
确定性策略:π(x)=a,即在状态x下执行a动作;
随机性策略:P=π(x,a),即在状态x下执行a动作的概率。
一个策略的优劣取决于长期执行这一策略后的累积奖赏。
长期累积奖赏通常使用下述两种计算方法:

K-摇臂赌博机
最简单的情形:仅考虑一步操作
在状态x下只需执行一次动作a便能观察到奖赏结果。易知:欲最大化单步奖赏,我们需要知道每个动作带来的期望奖赏值,这样便能选择奖赏值最大的动作来执行。若每个动作的奖赏值为确定值,则只需要将每个动作尝试一遍即可,但大多数情形下,一个动作的奖赏值来源于一个概率分布,因此需要进行多次的尝试。
单步强化学习实质上是K-摇臂赌博机(K-armed bandit)的原型,一般我们尝试动作的次数是有限的,那如何利用有限的次数进行有效地探索呢?这里有两种基本的想法:
仅探索法:将尝试的机会平均分给每一个动作,即轮流执行,最终将每个动作的平均奖赏作为期望奖赏的近似值。
仅利用法:将尝试的机会分给当前平均奖赏值最大的动作,隐含着让一部分人先富起来的思想。
可以看出:上述两种方法是相互矛盾的:
- 仅探索法能较好地估算每个动作的期望奖赏,但是没能根据当前的反馈结果调整尝试策略;(估计摇臂的优劣)
- 仅利用法在每次尝试之后都更新尝试策略,符合强化学习的思维,但容易找不到最优动作;(选择当前最优摇臂)
- 因此需要在这两者之间进行折中。
ε-贪心
ε-贪心法基于一个概率来对探索和利用进行折中:在每次尝试时,以ε的概率进行探索,即以均匀概率随机选择一个动作;以1-ε的概率进行利用,即选择当前最优的动作。ε-贪心法只需记录每个动作的当前平均奖赏值与被选中的次数,便可以增量式更新。

Softmax
Softmax算法则基于当前每个动作的平均奖赏值来对探索和利用进行折中,Softmax函数将一组值转化为一组概率,值越大对应的概率也越高,因此当前平均奖赏值越高的动作被选中的几率也越大。Softmax函数(基于Bpltzmann分布)如下所示:


有模型学习
若学习任务中的四个要素都已知,即状态空间、动作空间、转移概率以及奖赏函数都已经给出,这样的情形称为“有模型学习”。假设状态空间和动作空间均为有限,即均为离散值,这样我们不用通过尝试便可以对某个策略进行评估。
策略评估
前面提到:在模型已知的前提下,我们可以对任意策略的进行评估(后续会给出演算过程)。一般常使用以下两种值函数来评估某个策略的优劣:
状态值函数(V):V(x),即从状态x出发,使用π策略所带来的累积奖赏;
状态-动作值函数(Q):Q(x,a),即从状态x出发,执行动作a后再使用π策略所带来的累积奖赏。
根据累积奖赏的定义,我们可以引入T步累积奖赏与r折扣累积奖赏:


由于MDP具有马尔可夫性,即现在决定未来,将来和过去无关,我们很容易找到值函数的递归关系:

类似地,对于r折扣累积奖赏可以得到:

易知:当模型已知时,策略的评估问题转化为一种动态规划问题,即以填表格的形式自底向上,先求解每个状态的单步累积奖赏,再求解每个状态的两步累积奖赏,一直迭代逐步求解出每个状态的T步累积奖赏。算法流程如下所示:

对于状态-动作值函数,只需通过简单的转化便可得到:
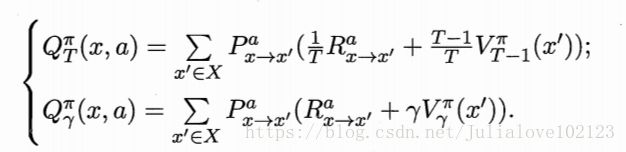
策略改进
理想的策略应能使得每个状态的累积奖赏之和最大,即:

简单来理解就是:不管处于什么状态,只要通过该策略执行动作,总能得到较好的结果。因此对于给定的某个策略,我们需要对其进行改进,从而得到最优的值函数。


最优Bellman等式改进策略的方式为:将策略选择的动作改为当前最优的动作,而不是像之前那样对每种可能的动作进行求和。易知:选择当前最优动作相当于将所有的概率都赋给累积奖赏值最大的动作,因此每次改进都会使得值函数单调递增。
![]()
策略迭代和值迭代
将策略评估与策略改进结合起来,我们便得到了生成最优策略的方法:先给定一个随机策略,现对该策略进行评估,然后再改进,接着再评估/改进一直到策略收敛、不再发生改变。这便是策略迭代算法,算法流程如下所示:

可以看出:策略迭代法在每次改进策略后都要对策略进行重新评估,因此比较耗时。若从最优化值函数的角度出发,即先迭代得到最优的值函数,再来计算如何改变策略,这便是值迭代算法,算法流程如下所示:

免模型学习
概念:学习算法不依懒于环境建模;
蒙特卡罗强化学习
由于模型参数未知,状态值函数不能像之前那样进行全概率展开,从而运用动态规划法求解。一种直接的方法便是通过采样来对策略进行评估/估算其值函数,蒙特卡罗强化学习正是基于采样来估计状态-动作值函数:对采样轨迹中的每一对状态-动作,记录其后的奖赏值之和,作为该状态-动作的一次累积奖赏,通过多次采样后,使用累积奖赏的平均作为状态-动作值的估计,并引入ε-贪心策略保证采样的多样性。

在上面的算法流程中,被评估和被改进的都是同一个策略,因此称为同策略蒙特卡罗强化学习算法。引入ε-贪心仅是为了便于采样评估,而在使用策略时并不需要ε-贪心,那能否仅在评估时使用ε-贪心策略,而在改进时使用原始策略呢?这便是异策略蒙特卡罗强化学习算法。

时序差分学习
概念:结合动态规划与蒙特卡罗方法思想;

将Sarsa修改为异策略算法得到Q-学习算法

值函数近似


基于线性值函数近似来代Sarsa算法中的值函数,得到线性值函数近似Sarsa算法

模仿学习
概念:从范例中学习,又叫“学徒学习”、“示例学习”、“观察学习”;
直接模仿学习:直接模仿人类专家的“状态-动作对”;
逆强化学习:从人类专家提供的范例数据中反推出奖赏函数;
