Keras从头开始训练一个在CIFAR10上准确率达到89%的模型
如何用Keras从头开始训练一个在CIFAR10上准确率达到89%的模型
CIFAR10 是一个用于图像识别的经典数据集,包含了10个类型的图片。该数据集有60000张尺寸为 32 x 32 的彩色图片,其中50000张用于训练,10000张用于测试。[CIFAR10]
在几大经典图像识别数据集(MNIST / CIFAR10 / CIFAR100 / STL-10 / SVHN / ImageNet)中,对于 CIFAR10 数据集而言,目前业内 State-of-Art 级别的模型所能达到的最高准确率是 96.53%(详细排名及论文链接)。
现在就让我们用 Keras 从头开始训练一个CNN模型,目标是让模型能够在 CIFAR10 上达到将近 89% 的准确率。
1. 数据导入和预处理
- 使用 keras.datasets 可以很方便的导入 CIFAR10 的数据。
- 正规化:将像素点的取值范围从 [0, 255] 归一化至 [0, 1]。实际上,对于不同的经典模型而言,有多种正规化方法,例如 [0, 1], [-1, 1], Mean Subtraction 等等。
- 使用 keras.utils.to_categorical 对十类标签进行 One-hot 编码,以供后来Softmax分类。
nb_classes = 10
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
y_train = y_train.reshape(y_train.shape[0])
y_test = y_test.reshape(y_test.shape[0])
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
y_train = to_categorical(y_train, nb_classes)
y_test = to_categorical(y_test, nb_classes)
2. 创建模型
这里我们采用类似于 VGG16 的结构创建模型。
- 使用固定尺寸的小卷积核 3 x 3
- 两层卷积搭配一层池化
- 使用 VGG16 的前三个卷积池化结构:以2的幂次递增卷积核数量 (64, 128, 256)
- 模型的全连接层没有采用 VGG16 庞大的三层结构(VGG16 的全连接层参数数量占整个模型的90%以上)
- 卷积层输出直接上 10 分类的 Softmax Classifier(测试过添加一层128个节点的全连接层节点在输出层之前,但是训练100代只能到79%的准确率,比不加还要差)
- 权重初始化全部采用 He Normal
x = Input(shape=(32, 32, 3))
y = x
y = Convolution2D(filters=64, kernel_size=3, strides=1, padding='same', activation='relu', kernel_initializer='he_normal')(y)
y = Convolution2D(filters=64, kernel_size=3, strides=1, padding='same', activation='relu', kernel_initializer='he_normal')(y)
y = MaxPooling2D(pool_size=2, strides=2, padding='same')(y)
y = Convolution2D(filters=128, kernel_size=3, strides=1, padding='same', activation='relu', kernel_initializer='he_normal')(y)
y = Convolution2D(filters=128, kernel_size=3, strides=1, padding='same', activation='relu', kernel_initializer='he_normal')(y)
y = MaxPooling2D(pool_size=2, strides=2, padding='same')(y)
y = Convolution2D(filters=256, kernel_size=3, strides=1, padding='same', activation='relu', kernel_initializer='he_normal')(y)
y = Convolution2D(filters=256, kernel_size=3, strides=1, padding='same', activation='relu', kernel_initializer='he_normal')(y)
y = MaxPooling2D(pool_size=2, strides=2, padding='same')(y)
y = Flatten()(y)
y = Dropout(0.5)(y)
y = Dense(units=nb_classes, activation='softmax', kernel_initializer='he_normal')(y)
model1 = Model(inputs=x, outputs=y, name='model1')
model1.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
用 summary() 查看一下模型的完整结构。
同时可以注意到,模型的总参数量为 118 万左右 (这还是简化后的模型)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv2d_19 (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
conv2d_20 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
max_pooling2d_10 (MaxPooling (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_21 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
conv2d_22 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
max_pooling2d_11 (MaxPooling (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_23 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
conv2d_24 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
max_pooling2d_12 (MaxPooling (None, 4, 4, 256) 0
_________________________________________________________________
flatten_4 (Flatten) (None, 4096) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_6 (Dense) (None, 10) 40970
=================================================================
Total params: 1,186,378
Trainable params: 1,186,378
Non-trainable params: 0
_________________________________________________________________
3. 定义训练方式
Keras比较有意思的一点就是你可以使用各种回调函数来让你的训练过程更轻松快捷。
- Early Stopping:通过监测性能指标的变化趋势来及时停止训练,避免过拟合。
- Model Checkpoint:自动保存每一代训练后的模型快照,可以只记录性能提升的代。
- Tensor Board:自动配置强大的可视化工具 TensorBoard,将每代训练数据都保存并绘制在 TensorBoard 上,方便后期对比模型的性能。
4. 模型性能提升的几个方向
为了提升模型的性能,我目前了解到通常可以在以下几种方向上下功夫:
- Data Augmentation
- Weight Initialization
- Transfer Learning + Fine-tune
- Ensemble / Model Fusion
下面用的是第一个:图像增强。Keras 很方便的自带了图像增强的生成器。这个生成器函数提供了很多图像变换的参数,例如旋转、平移、白化等等。可以直接定义图像增强生成器对象,然后用 flow 函数生成真正可以用于训练的生成器。我定义的完整训练函数如下。
import os
from datetime import datetime
def train(model, batch, epoch, data_augmentation=True):
start = time()
log_dir = datetime.now().strftime('model_%Y%m%d_%H%M')
os.mkdir(log_dir)
es = EarlyStopping(monitor='val_acc', patience=20)
mc = ModelCheckpoint(log_dir + '\\CIFAR10-EP{epoch:02d}-ACC{val_acc:.4f}.h5',
monitor='val_acc', save_best_only=True)
tb = TensorBoard(log_dir=log_dir, histogram_freq=0)
if data_augmentation:
aug = ImageDataGenerator(width_shift_range = 0.125, height_shift_range = 0.125, horizontal_flip = True)
aug.fit(X_train)
gen = aug.flow(X_train, y_train, batch_size=batch)
h = model.fit_generator(generator=gen,
steps_per_epoch=50000/batch,
epochs=epoch,
validation_data=(X_test, y_test),
callbacks=[es, mc, tb])
else:
start = time()
h = model.fit(x=X_train,
y=y_train,
batch_size=batch,
epochs=epoch,
validation_data=(X_test, y_test),
callbacks=[es, mc, tb])
print('\n@ Total Time Spent: %.2f seconds' % (time() - start))
acc, val_acc = h.history['acc'], h.history['val_acc']
m_acc, m_val_acc = np.argmax(acc), np.argmax(val_acc)
print("@ Best Training Accuracy: %.2f %% achieved at EP #%d." % (acc[m_acc] * 100, m_acc + 1))
print("@ Best Testing Accuracy: %.2f %% achieved at EP #%d." % (val_acc[m_val_acc] * 100, m_val_acc + 1))
return h
5. 训练模型
我们首先使用 batch size = 64 对模型进行训练。
accuracy_curve 是通过训练结束返回的历史信息绘制出的 accuracy 和 loss 曲线。代码见:utils.py。如果用TensorBoard的话,看到同样的图表信息。
epoch = 200
batch = 64
h = train(model1, batch, epoch)
accuracy_curve(h)
-----------------------
........
Epoch 105/200
16s - loss: 0.0656 - acc: 0.9782 - val_loss: 0.5996 - val_acc: 0.8947
Epoch 106/200
16s - loss: 0.0661 - acc: 0.9782 - val_loss: 0.6633 - val_acc: 0.8938
@ Total Time Spent: 1875.35 seconds
@ Best Training Accuracy: 97.89 % achieved at EP #98.
@ Best Testing Accuracy: 90.00 % achieved at EP #85.
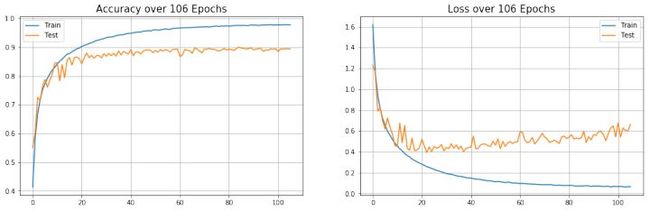
6. 分析训练结果
训练结果显示模型最高在第85代达到了90%的测试准确率。
但是,我们可以观察到,从第40代开始模型的 Testing Loss 曲线就不再下降而是开始上升,这说明模型已经进入过拟合状态,不应继续训练。这是由于我在 Early Stopping 检测的性能指标不是 val_loss 而是 val_acc,因此并不能够在模型的 Loss 停止下降时就及时结束训练。
所以实际上模型正常收敛的测试准确率应该在20 - 40代之间,即准确率在 88% - 89% 左右。
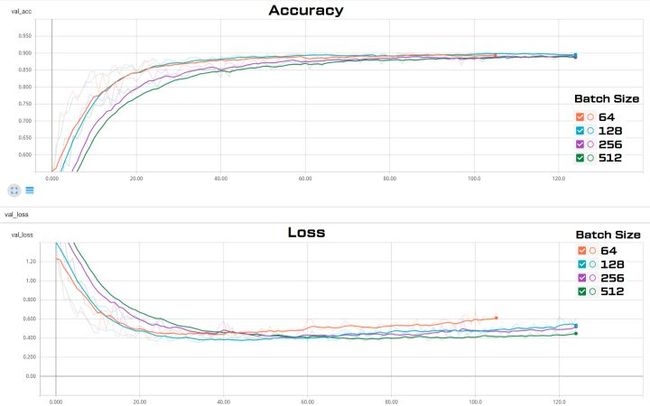
7. 使用 TensorBoard 对比不同 Batch Size 下的模型训练过程
我对上面的模型尝试了四种不同的 Batch Size = 64 / 128 / 256 / 512,并通过 TensorBoard 将这四个模型的训练准确度和Loss曲线绘制在一张图上,结果很有趣。
- 横轴是训练代数
- 半透明的折线是原始数据
- 实线是经过平滑后的数据,能够更清晰的看到每个模型在同一个训练指标上的变化趋势
- 放大细节图
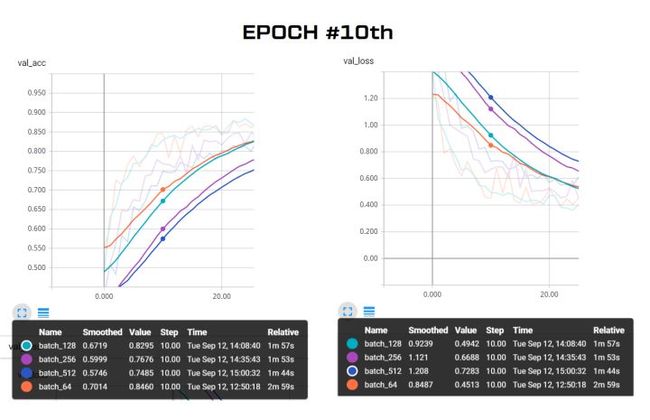


通过这个简单的对比试验,可以得到以下几条关于 Batch Size 对训练模型影响的结论:
- Batch Size 越大,每代训练的训练时间越短,但缩短到一定程度就不再下降
- Batch Size 越大,模型收敛的越慢,直至不能收敛
- Batch Size 越大,过拟合会越晚体现出来
代码链接
- CIFAR10 Image Classification using Keras (Concise)
转载自:https://zhuanlan.zhihu.com/p/29214791