Hive实战
•Hive系统结构
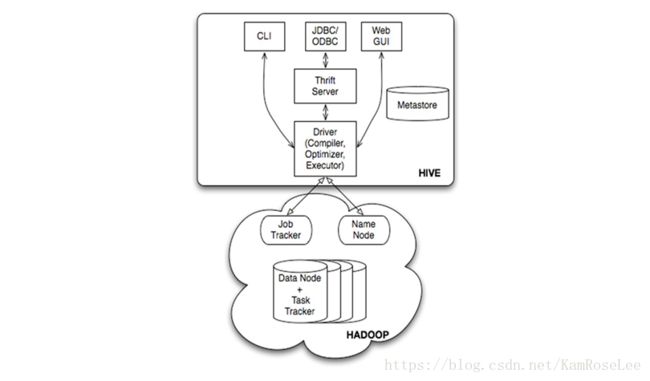
•数据流(in taobao)
–数据源:weblog/db/…
–数据同步:jdbcdump
–报表计算/预处理/ETL:Hive
–数据入库:dbloader
Hive QL
•数据类型
–Primitive
•int / bigint / smallint / tinyint
•boolean
•double / float
•string
–Array
–Map
–Struct
–No precision / length config
–No date / datetime type
Hive QL
•DDL – create table
–CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type, ...)]
[PARTITIONED BY (col_name data_type, ...)]
[ [ROW FORMAT row_format] [STORED AS file_format] | [ WITH SERDEPROPERTIES (...) ] ]
[LOCATION hdfs_path]
Hive QL
•DDL – create table example
CREATE TABLE page_view(
viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING COMMENT 'IP Address of the User‘
)
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS SEQUENCEFILE;
Hive QL
•DML – load data
–LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
Hive QL
•DML – insert
–INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement
–FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 [INSERT OVERWRITE TABLE tablename2 [PARTITION ...] select_statement2] ...
–INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement
–(HDFS)不支持UPDATE!
Hive QL
•DML/DDL – add partition
–ALTER TABLE table_name ADD PARTITION (partcol1=val1, partcol2=val2 ...) [LOCATION 'filepath' ]
Hive QL
•Query - select
–SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ]
[LIMIT number]
–不支持exist in子查询
Hive QL
•Query - join
–join_table: table_reference JOIN table_factor [join_condition] | table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
–table_reference: table_factor | join_table
–table_factor: tbl_name [alias] | table_subquery alias | ( table_references )
–join_condition: ON equality_expression ( AND equality_expression )* equality_expression: expression = expression
–等值Join
–合并Join的原则
–NULL值处理
Hive QL
•Query - subqueries
–SELECT ... FROM (subquery) name ...
–select_statement UNION ALL select_statement UNION ALL select_statement ...
Hive扩展
•UDFs
–类别
•UDF - 1:1
•UDAF – N:1
•(UDTF)
–Implement UDF
•extends UDF / GenericUDF
•implement evaluate() function
–Implement UDAF
•extends UDAF / GenericUDAF
•implement
–iterate
–merge
–terminatePartial
–terminate
Hive扩展
•Transform
–FROM (
FROM src
MAP expression (',' expression)*
USING 'my_map_script'
( AS colName (',' colName)* )?
( clusterBy? | distributeBy? sortBy? ) src_alias
)
REDUCE
expression (',' expression)*
USING 'my_reduce_script'
( AS colName (',' colName)* )?
Hive vs SQL
•语义
–无关系约束(第一范式?)
–不支持exist in子查询
–只支持等值Join
•数据类型
Hive优化器
•Partition Pruning (ppr)分区裁减where(pt=‘’)
•Predicate Push down (ppd)
•Column Pruning (cp)
•Mapjoin transformer
Hive优化
•数据偏斜
–MapJoin缺点:1内存2小表数*MAP数是否太大
–Group by (distinct) skew
•内存优化
–驱动表:优化内存,将大表作为驱动表即a join b
b为驱动表
•I/O优化
–Map aggregation
•MR任务合并
–multi-insert节省两次m/r的扫描
–multi-groupby
–multi-distinct