Coursera-Applied Data Science with Python-Introduction to Data Science in Python-Week3
一、Merging Dataframes:
首先,我们先复习一下上周所学的内容,上周主要是学习了Pandas中两个核心的数据结构:一维结构的Series和二维结构的DataFrame。查询这两个数据结构中的值有两种方式:第一种是行查询(row-based querying),通过使用loc、iloc属性;第二张是列查询(column-based querying),通过使用方括号操作符("[]")完成。而且还学习了通过Boolean Masking 来过滤数据。

1.向已存在的DataFrame内添加列:

通过之前的学习,我们已经知道了一种向DataFrame里添加数据的方式,即我们给带有新列名的方括号操作符赋值来达到这个目的。

但是这种方法有个局限就是,要求进行赋值的列表的长度必须要和DataFrame的index的长度一样,换句话说就是要把DataFrame里每一行这属性的值交代清楚,否则就会出现错误:

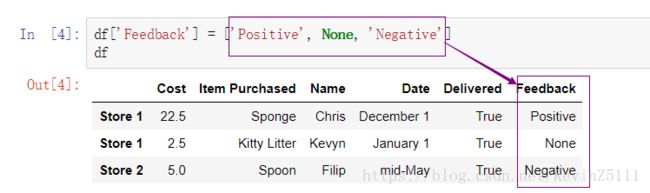
要注意的是,对于数值型数据(scalar value)例如,整数,字符串等等,上面的方法是可用的,具体地如下图所示:

那么,如果我们想给某一列的不同位置赋不同的值,那就必须创建一个和DataFrame的index的长度一样的list,list的里按顺序存放希望的内容(包括缺失值missing value):
如果,DataFrame里的每一行都有着唯一的索引,那么我们就可以通过索引给要添加的那列的具体位置赋值,这样做的好处就是可以不用自己填写缺失值。

2.合并DataFrame:
使用Pandas里的merge函数能完成将两个DataFrame合并的操作,该方法的签名为:
Pandas.merge(left,right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
主要参数介绍:
left:参与合并的左边的DataFrame(相当于SQL的join中的左表);
right:参数合并的右边的DataFrame(相当于SQL的join中的右表);
how:为合并的方式,分别为'inner','outer','left','right',默认为'inner'(相当于SQl中表连接的内连接、外链接、左链接和右连接,说白了就是:内连接是求交集;外连接是求并集;左连接是以左边的数据为准,查询出右边的数据;右连接则是反过来);
on:两个DataFrame用户连接的列名,必须同时存在于两个DataFrame中,如果未指定则为两个表的交集作为连接键;
left_on:左表用于连接的列(主要用户两个DataFrame不存在相同的列名时);
right_on:右表用于连接的列;
left_index:将左边的DataFrame的索引作为连接键;
right_index:将右边的DataFrame的索引作为连接键;
sort:根据连接键对合并的结果进行排序;
suffixes:字符串的元组,用于追加于重叠列名的末尾,默认为(_x,_y)
具体地我们通过代码来理解,先创建两个DateFrame
staff_df = pd.DataFrame([{'Name': 'Kelly', 'Role': 'Director of HR'},
{'Name': 'Sally', 'Role': 'Course liasion'},
{'Name': 'James', 'Role': 'Grader'}])
staff_df = staff_df.set_index('Name')
student_df = pd.DataFrame([{'Name': 'James', 'School': 'Business'},
{'Name': 'Mike', 'School': 'Law'},
{'Name': 'Sally', 'School': 'Engineering'}])
student_df = student_df.set_index('Name') a.连接情况一:外连接
pd.merge(staff_df, student_df, how='outer', left_index=True, right_index=True)这段代码的意思是,将staff_df和student_df进行外连接,将staff_df和student_df的索引作为连接键。最后得到的结果是:

b.连接情况二:内连接
pd.merge(staff_df, student_df, how='inner', left_index=True, right_index=True)
c.连接情况三:左连接
pd.merge(staff_df, student_df, how='left', left_index=True, right_index=True)
d.连接情况四:右连接
pd.merge(staff_df, student_df, how='right', left_index=True, right_index=True)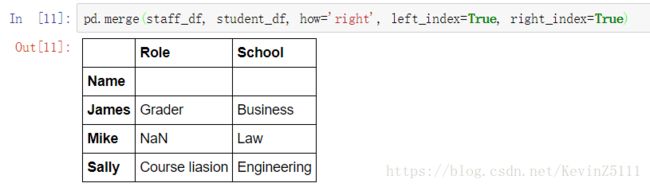
e.连接情况五:不以索引进行连接,而是以某一列进行连接
staff_df = staff_df.reset_index()
student_df = student_df.reset_index()
pd.merge(staff_df, student_df, how='left', left_on='Name', right_on='Name') 这段代码先是把staff_df和student_df的索引设置为以0开始自增的索引,将左边DataFrame连接键设置为:Name列,将右边DataFrame连接键设置为Name列:

f.连接情况六:合并的两个DataFrame有两个同名的列:
staff_df = pd.DataFrame([{'Name': 'Kelly', 'Role': 'Director of HR', 'Location': 'State Street'},
{'Name': 'Sally', 'Role': 'Course liasion', 'Location': 'Washington Avenue'},
{'Name': 'James', 'Role': 'Grader', 'Location': 'Washington Avenue'}])
student_df = pd.DataFrame([{'Name': 'James', 'School': 'Business', 'Location': '1024 Billiard Avenue'},
{'Name': 'Mike', 'School': 'Law', 'Location': 'Fraternity House #22'},
{'Name': 'Sally', 'School': 'Engineering', 'Location': '512 Wilson Crescent'}])
pd.merge(staff_df, student_df, how='left', left_on='Name', right_on='Name')可以看到staff_df和student_df有两个同名的列Location,但是表达的意思是不同的,Pandas在处理这种问题时,会将两列都保留:

g.连接情况七:多列作为连接键进行合并
staff_df = pd.DataFrame([{'First Name': 'Kelly', 'Last Name': 'Desjardins', 'Role': 'Director of HR'},
{'First Name': 'Sally', 'Last Name': 'Brooks', 'Role': 'Course liasion'},
{'First Name': 'James', 'Last Name': 'Wilde', 'Role': 'Grader'}])
student_df = pd.DataFrame([{'First Name': 'James', 'Last Name': 'Hammond', 'School': 'Business'},
{'First Name': 'Mike', 'Last Name': 'Smith', 'School': 'Law'},
{'First Name': 'Sally', 'Last Name': 'Brooks', 'School': 'Engineering'}])
staff_df
student_df
pd.merge(staff_df, student_df, how='inner', left_on=['First Name','Last Name'], right_on=['First Name','Last Name'])其中left_on和right_on的参数值是一个list,这就是作为连接键的列名:

二、Idiomatic Pandas:Making Code Pandorable
在python以及pandas中解决一个问题的方法是不止一种的,但是通常是由几种推荐的解决方案,把它们称作惯用方法。通常,这些惯用方法有着高性能和高可读性的特点。在Pandas社区里把这些惯用语称为pandorable。对于如何使得代码更加pandorable,有几个关键点:
1.尽量少用链式索引,多用方法链接:
链式索引就是类似于(df.loc["Washtennaw"]["Total Population"])的语句,这种语句有个缺点就是,你并不知道这样返回的是一个副本还是一个视图,这完全由底层的Numpy库决定。Tom Osberger曾经说过,一旦你连续的使用方括号操作符时,你应该认真考虑一下这样做是否真确。

然而,方法链接是有点不同的。由于方法链接返回的都是原对象的引用,这就意味着我们的操作都是在原DataFrame上的。下面是两个例子:
import pandas as pd
df = pd.read_csv('census.csv')
(df.where(df['SUMLEV']==50)
.dropna()
.set_index(['STNAME','CTYNAME'])
.rename(columns={'ESTIMATESBASE2010': 'Estimates Base 2010'}))
df = df[df['SUMLEV']==50]
df.set_index(['STNAME','CTYNAME'], inplace=True)
df.rename(columns={'ESTIMATESBASE2010': 'Estimates Base 2010'})  从结果上看,两段代码是一样的,而且说实话第二段代码对于新手来说还更容易看懂,但是我们要说还是第一段代码更pandorable。
从结果上看,两段代码是一样的,而且说实话第二段代码对于新手来说还更容易看懂,但是我们要说还是第一段代码更pandorable。
2.使用apply函数和lambda表达式来操作DataFrame的数据。我们使用之前的人口评估的数据:
例1:我们想要找出每行数据中的最大最小值:
import numpy as np
def min_max(row):
data = row[['POPESTIMATE2010',
'POPESTIMATE2011',
'POPESTIMATE2012',
'POPESTIMATE2013',
'POPESTIMATE2014',
'POPESTIMATE2015']]
return pd.Series({'min': np.min(data), 'max': np.max(data)})
df.apply(min_max, axis=1)
apply函数的参数axis=1表示沿着水平方向进行数据处理,而另一个参数则是要应用的处理函数,即min_max。df中的每一行数据都会被应用上这个处理函数。
import numpy as np
def min_max(row):
data = row[['POPESTIMATE2010',
'POPESTIMATE2011',
'POPESTIMATE2012',
'POPESTIMATE2013',
'POPESTIMATE2014',
'POPESTIMATE2015']]
row['max'] = np.max(data)
row['min'] = np.min(data)
return row
df.apply(min_max, axis=1)
一般来说,我们是不会将大型函数应用于DataFrame的apply函数的,都是使用lambda表达式:
rows = ['POPESTIMATE2010',
'POPESTIMATE2011',
'POPESTIMATE2012',
'POPESTIMATE2013',
'POPESTIMATE2014',
'POPESTIMATE2015']
df.apply(lambda x: np.max(x[rows]), axis=1)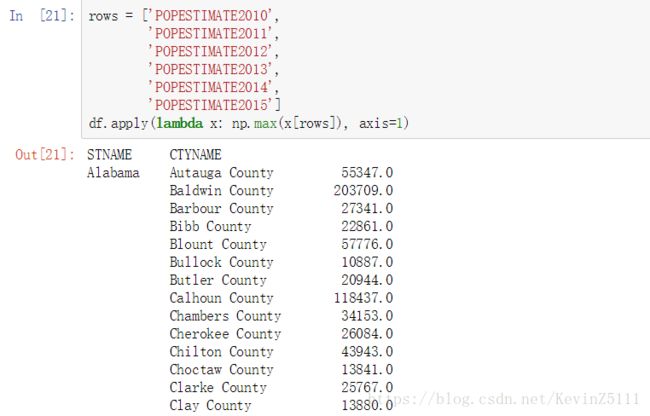
三、Group by
虽然Pandas能允许我们通过迭代的方式获得DataFrame里的数据,但是通常来说这种方法是很慢的,而且也不是Pandorable。例如:
%%timeit -n 10
for state in df['STNAME'].unique():
avg = np.average(df.where(df['STNAME']==state).dropna()['CENSUS2010POP'])
print('Counties in state ' + state + ' have an average population of ' + str(avg))另一种完成这个功能的方法就是使用groupby()函数,这个函数通过列名把DataFrame分割成基于列名的一小块数据。该方法会返回两个值,第一个值是一个以分组条件为集合的元组,第二个值是通过分组而得到的DataFrame。下面是一个例子:
%%timeit -n 10
for group, frame in df.groupby('STNAME'):
avg = np.average(frame['CENSUS2010POP'])
print('Counties in state ' + group + ' have an average population of ' + str(avg))
函数也能作为groupby的参数,就相当于把所有数据都应用于该函数。下面是一个例子,假设我们有一大批的数据要处理,而且你想在给定的时间里处理三分之一的数据,我们可以创建一个函数:依据每个州的首字母将这些数据分成三个部分。然后我们让groupby函数调用这个函数进行数据分割,但是先要把DataFrame的索引换成想要进行groupby的那列。
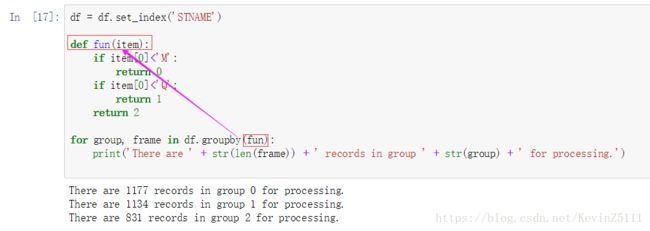
通常来说,groupby的工作流程是,分割数据,应用一些功能函数,然后合并结果,这样被称作拆分(split)、应用(apply)、组合(combine)模式。现在我们要讨论一下如何应用功能函数:groupby对象有一个被称为agg的函数,也就是aggregate(聚合)的意思。agg函数会将一列或几列的数据应用于另一个函数,并且返回相应的结果。有了agg函数,你只需要给该函数传递一个字典类型的参数,以你感兴趣的列名为key,以你想应用的函数为value。下面是一个例子:
df = pd.read_csv('census.csv')
df = df[df['SUMLEV']==50]
df.groupby('STNAME').agg({'CENSUS2010POP': np.average})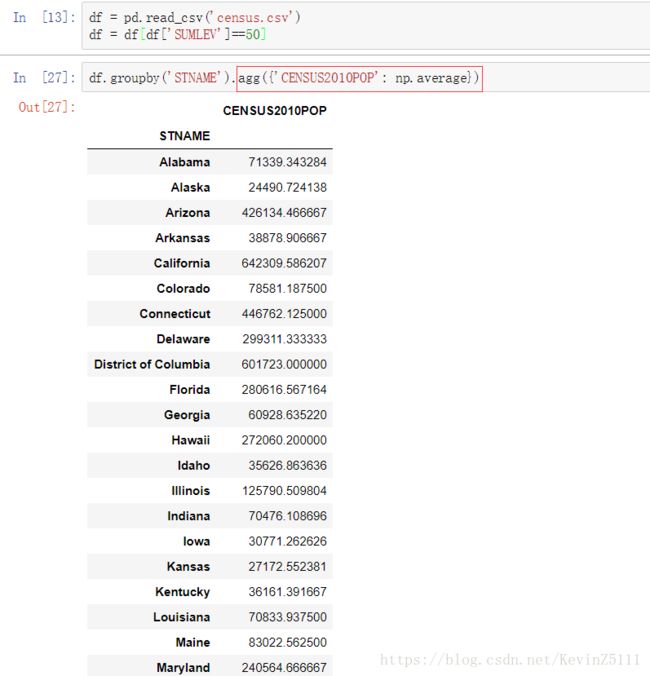
当你给agg函数传入一个字典时,它既可以是要被处理的数据的列名,也可以是要输出的列名。之所以要这样说就是由于DataFrameGroupBy和SeriesGroupBy是两种不同的数据类型,它们在进行agg操作时会有不同的结果

a.对SeriesGroupBy类型进行操作:
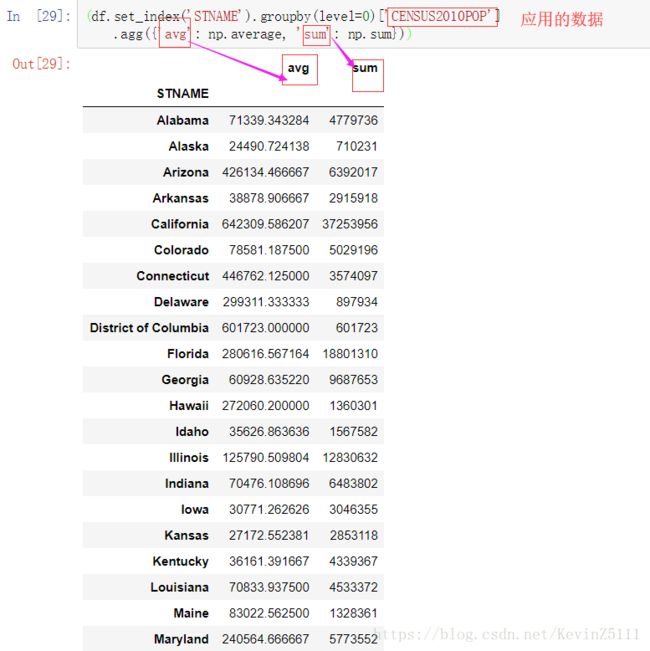
(df.set_index('STNAME').groupby(level=0)['CENSUS2010POP']
.agg({'avg': np.average, 'sum': np.sum}))这段代码的意思是,将CENSUS2010POP这行数据按照州的名字进行求平均值、求和。由于仅仅只有一行数据,所以average函数、sum函数都会作用于这一列。结果如下图
b.对DataFrameGroupBy类型进行操作:
(df.set_index('STNAME').groupby(level=0)['POPESTIMATE2010','POPESTIMATE2011']
.agg({'avg': np.average, 'sum': np.sum}))这段代码的意思是将POPESTIMATE2010和POPESTIMATE2011这两列数据进行求平均值和求和的操作。操作结果如下图:

但是,如果这么使用:
(df.set_index('STNAME').groupby(level=0)['POPESTIMATE2010','POPESTIMATE2011']
.agg({'POPESTIMATE2010': np.average, 'POPESTIMATE2011': np.sum}))最后的结果是:

四、Scales
现在我们来看一下数据的类型(type)和尺度(scale)。我们已经见识过了Pandas所支持的计算数据类型,例如String,integers和floating point,但是这并不包括数据尺度。什么是尺度?例如对于成绩的衡量标准A+、A、A-...D+、D、D-就是一个典型的尺度,有四个尺度是我们需要知道的:定距型数据(Interval Scale)、定序型数据(Ordinal Scale)、定类型数据(Nominal Scale)和定比型数据 (Ratio Scale)。
定比型尺度(Ratio Scale): 具体表现就是数值,而且单位数值间是等距的,支持加减乘除。例如高度,长度等等。
定距离尺度(Inerval Scale):就是数字型变量,可以求加减平均值等,但是不存在基准0值。如温度,当温度为0时,并不代表没有温度。
定序型尺度(Ordinal Scale): 具有内在固定的大小或高低顺序,一般可以用字符或数字表示。如年龄变量可以有老、中、青三个取值,分别用A、B、C表示,这里的A、B、C是有大小或高低顺序的,但之间不是等距的,所以可以进行排序但不能加减。
定类型尺度(Nominal Scale):一般是指类别,内在没有固定的大小或高低顺序。例如性别男或女

之所以要提Scale的原因是,Pandas有许多有趣的函数进行Scale间的转换。
1.Nominal Scale->Ordinal Scale
df = pd.DataFrame(['A+', 'A', 'A-', 'B+', 'B', 'B-', 'C+', 'C', 'C-', 'D+', 'D'],
index=['excellent', 'excellent', 'excellent', 'good', 'good', 'good', 'ok', 'ok', 'ok', 'poor', 'poor'])
df.rename(columns={0: 'Grades'}, inplace=True)
df
df['Grades'].astype('category').head()这段代码先是创建了一个表示成绩的DateFrame,然后使用astype()函数将其转成Nominal Scale。

grades = df['Grades'].astype('category',
categories=['D', 'D+', 'C-', 'C', 'C+', 'B-', 'B', 'B+', 'A-', 'A', 'A+'],
ordered=True)
grades.head()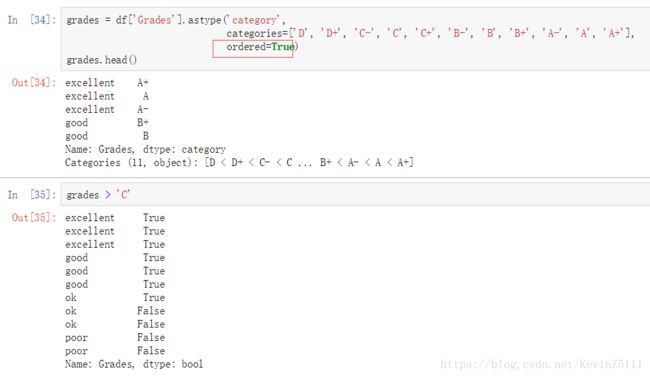
在pandas中我们将布尔变量也称为dummyvariables,而且pandas有个BIF叫做get_dummies()。
2.Ratio Scale->Nominal Scale:
我们使用Pandas的cut()函数来做到这一点。cut函数有两个参数,第一个参数要进行分割的数据,第二个参数则是要进行等分的份数。例如:
s = pd.Series([168, 180, 174, 190, 170, 185, 179, 181, 175, 169, 182, 177, 180, 171])
pd.cut(s, 3)
pd.cut(s, 3, labels=['Small', 'Medium', 'Large'])pd.cut(s,3)的结果:实际上就是把168~190这个区间等分成3份,然后给出每个数据位于那个区间内。

pd.cut(s,3,labels=['Small','Medium','Large'])的结果,这就是将三个区间和三个标签对应上。

五、Pivot Tables
数据透视表(Pivot Tables)是为了特定的分析目的,将DataFrame数据聚合的一种方式。数据透视表伴随着大量的agg函数的使用,而且它自己也是一个DataFrame。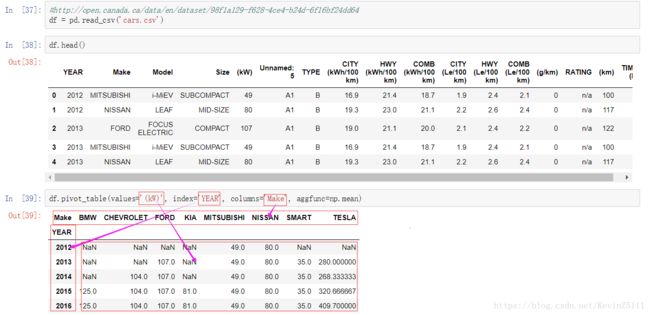
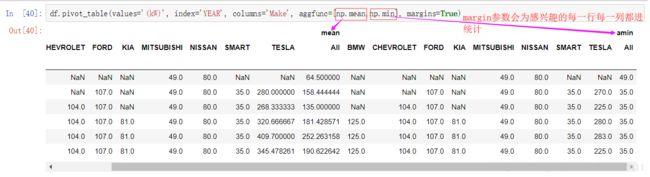
我们还可以应用多个函数:
六、Date Functionality in Pandas
1.Timestamp:
Timestamp代表的是单个时间戳,其值是与时间点相关联的。在大部分情况下,Timestamp和Python的datetime是可以相互转换的。

2.Period:
Period代表的是一段时间,单个时间跨度,例如特定的日期或者月份。

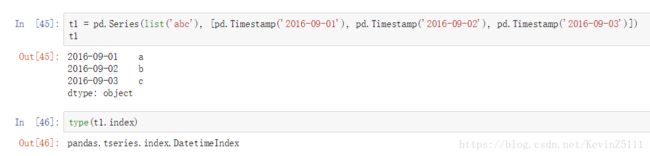
3.DatetimeIndex:
Timestamp作为索引就被称为DatetimeIndex。例如:
4.PeriodIndex:
Period作为索引就被称为PeriodIndex。例如:

5.转换成Datetime
我们先以字符串的形式创建几个日期,然后把这些日期作为DataFrame的索引。
d1 = ['2 June 2013', 'Aug 29, 2014', '2015-06-26', '7/12/16']
ts3 = pd.DataFrame(np.random.randint(10, 100, (4,2)), index=d1, columns=list('ab'))
ts3从上面可以看到,时间的格式是不同的,我们可以使用pandas的to_datetime函数将它们转成标准的形式。
ts3.index = pd.to_datetime(ts3.index)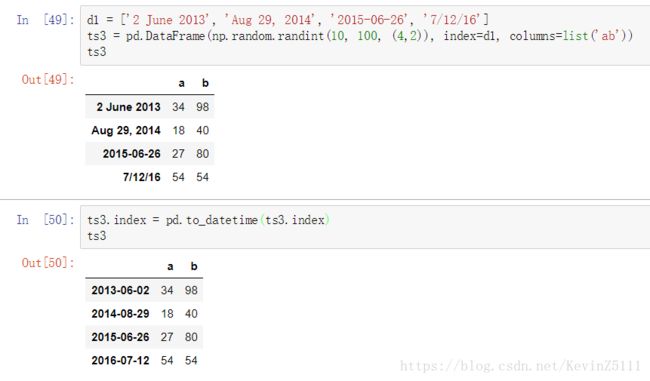
6.Timedeltas:
Timedeltas是指时间差。

7.Working with Dates in a DateFrame:
假设我们要查看某些数据,这些数据是从2016年10月开始,每两周的周日测量一次所得到的9个数据,我们可以使用date_range函数创建一个符合要求的DatetimeIndex,然后我们给每个索引创建一些随机值。具体的代码如下:
dates = pd.date_range('10-01-2016', periods=9, freq='2W-SUN')
df = pd.DataFrame({'Count 1': 100 + np.random.randint(-5, 10, 9).cumsum(),
'Count 2': 120 + np.random.randint(-5, 10, 9)}, index=dates)
df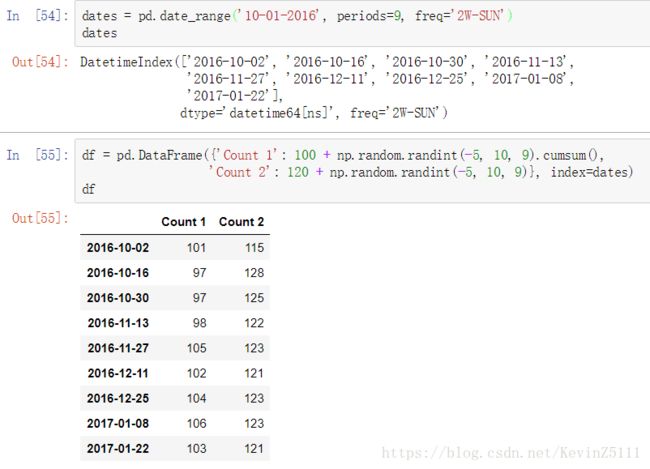
通过weekday_name属性,我们可以查看每个特定的日期是星期几。

通过diff()函数,我们可以查看每个日期对应的值间的差值:

通过resample函数能得到每个月的平均值:
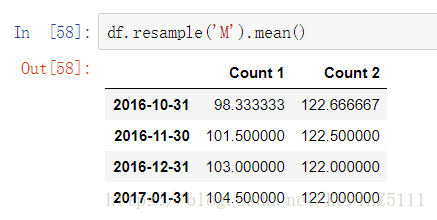
直接使用方括号能根据给定的年、月、日进行查找,甚至能进行分片:

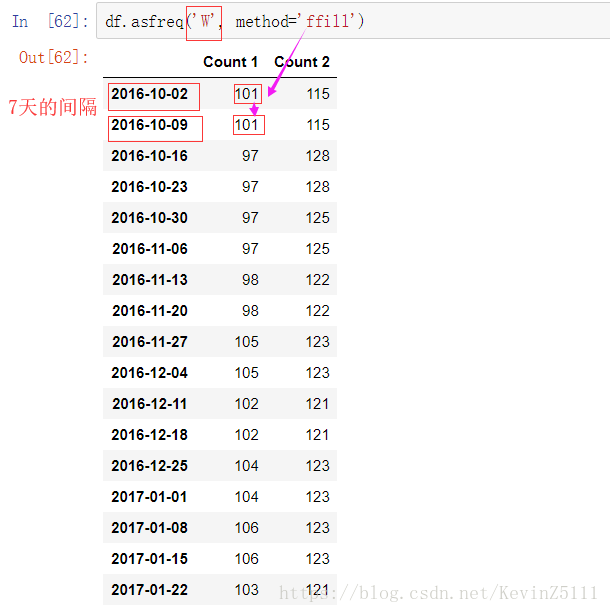
使用asfreq()函数能改变DataFrame里的日期出现的频率,例如我们相对上面的df对象中的日期频率进行修改,想把它改成每周的周日都进行采样,于是我们要使用asfreq函数,将第一个参数设置为‘W’表示每个星期一次,method参数设置为‘ffill’,即向前填充,把前一个的值填充到下个缺失的值。