Pandas中的数据加载、存储和文件格式
一、读写文本格式数据:
基本的文件读取:
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,其中用的最多的就是read_csv()函数和read_table()函数,具体的如下表所示:
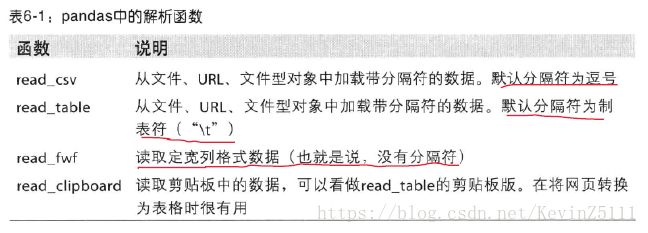
将数据文本转换为DataFrame时需要考虑的方面:
索引:当将一个或多个列当做返回的DataFrame处理时,是否要从文件、用户获取列名;
类型推断和数据转换:包括用户定义值的转换、缺失值标记列表等;
日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列;
迭代:支持对大文件进行逐块迭代;
不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西;
通过read_csv()函数和read_table()函数的参数的设置,我们就可以完成以上的大部分功能,具体的参数设置如下图所示:


下面我们结合几个例子来看read_csv函数和read_table函数的用法:
例1:读取一个以逗号分隔的csv文本文件:read_csv()可以直接读取,read_table()要指定分隔符:
import pandas as pd
import numpy as np
df = pd.read_csv('ch06/ex1.csv')
df1 = pd.read_table('ch06/ex1.csv',sep=',')
例2:为DataFrame设置列名,通过read_csv()函数的name参数来设置自定义的列名;若将header参数设置为None,则会采用默认的列名:
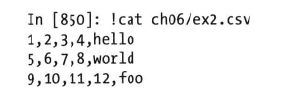
首先我们先查看文本文件ex2.csv:
我们既可以让pandas为其默认分配列名,也可以自己定义列名:
df = pd.read_csv('ch06/ex2.csv',header=None)
df = pd.read_csv('ch06/ex2.csv',names=['a','b','c','d','message'])
例3:设置某一列或某几列作为DataFrame的索引,通过设置index_col参数可以完成这个操作:
names = ['a','b','c','d','message']
df = pd.read_csv('ch06/ex2.csv', names=names, index_col='message')
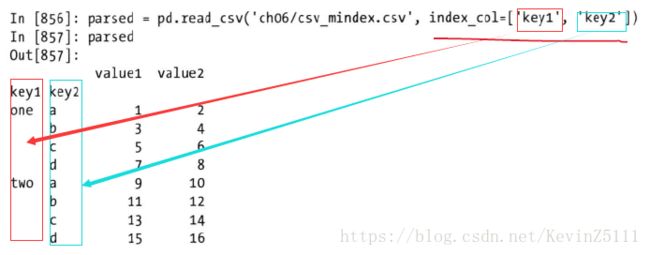
parsed = pd.read_csv('ch06/csv_mindex.csv', index_col=['key1','key2'])
例4:有些表格不是以固定的分割符去分割字段的,对于这种情况,需要编写一个正则表达式作为read_table的分隔符:
我们由这么一个文件,各个字段由数量不定的空白符分隔,具体如下图所示:

对于这个情况,我们可以使用正则表达式\s+表示,并且read_table()的sep参数设置为该正则表达式,于是我们就有:
result = pd.read_table('ch06/ex3.txt', sep='\s+')

例5:有时候在处理csv文件的时候,需要跳过某几行(跳过文件头),可以通过skiprows参数的设置来做到,在这个例子中我们跳过文件的第一行、第三行和第四行:
df = pd.read_csv('ch06/ex4.csv', skiprows=[0,2,3])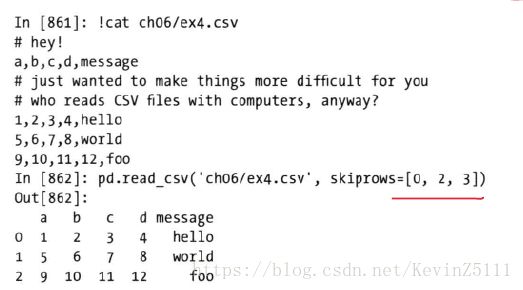
例6:处理缺失值处理是文件解析任务中一个重要的组成部分,缺失数据经常是要么没有(空字符串),要么用某个标记表示。默认情况下,pandas会用一组经常出现的标记值进行识别,如NA,-1,#IND,NULL等。
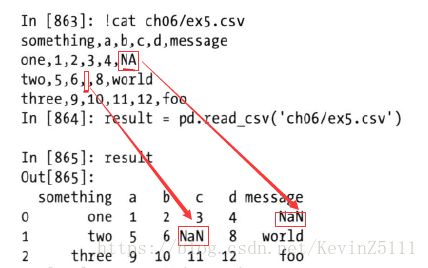
此外,我们还可以通过na_values参数的设置,将某些特定的值转换为NaN值,也可以指定某些列的某些值转换为NaN值:
result = pd.read_csv('ch06/ex5.csv', na_values=['NULL']) # 将文件中所有值为'NULL'都转换为NaN
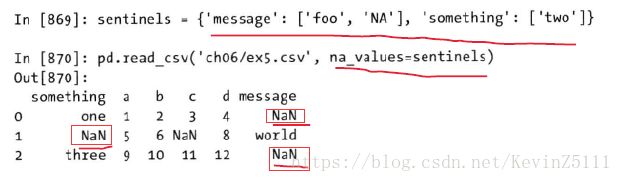
sentinels = {'message':['foo','NA'],'something':['two']}
pd.read_csv('ch06/ex5.csv', na_values=sentinels)

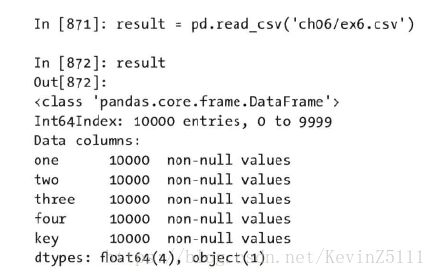
逐块读取文本文件:
在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,你可能只想读取文件的一小部分或逐块对文件进行迭代。例如我们有个文件,如下所示:
例1:只想读取以上文件的几行(避免读整个文件),可以通过read_csv()函数的nrow参数做到:
pd.read_csv('ch06/ex6.csv', nrows=5)
例2:逐块读取文件,需要设置chunksize参数,read_csv()所返回是个TextParser对象,可以根据chunksize对文件进行逐块迭代:
chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000)
我们可以迭代处理ex6.csv,将值计数聚合到"key"列中,如下所示:
chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000)
tot = pd.Series([])
for peice in chunker:
tot = tot.append(piece['key'].value_counts(), fill_value=0)
tot = tot.order(ascending=False)
将数据写出到文本格式:
数据也可以被输出为分隔符格式的文本,利用DataFrame的to_csv()函数,我们能将数据写到一个以逗号分隔的文件中:
例1:利用to_csv()函数,将数据写到一个以逗号分隔的文件中:
data = pd.read_csv('ch06/ex5.csv')
data.to_csv('ch06/out.csv')
例2:通过to_csv()的sep参数,还可以设置使用其他分隔符:
这里直接写出到sys.stdout,仅仅是为了打印出文本结果:
data.to_csv(sys.stdout, sep='|')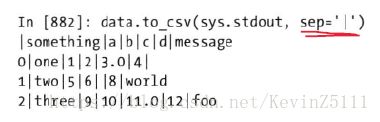
例3:在保存DataFrame的时候,其缺失值在输出结果中会被表示为空字符串,但是可以通过na_rep参数将其表示为别的标记值:
data.to_csv(sys.stdout, na_rep='NULL')
例4:默认情况下,输出结果中是会出现行和列的标签的,也可以通过index参数、header参数设置,禁用行和列标签:
data.to_csv(sys.stdout, index=False, header=False)
例5:通过cols参数可以设置只写出一部分的列,并且可以指定列的排序:
data.to_csv(sys.stdout. index=False, cols=['a','b','c'])
手工处理分隔符格式:
JSON数据:
JSON(JavaScript Object Notation)已经成为通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标准格式之一。它是一种比表格型文本格式(如csv)灵活得多的数据格式。JSON非常接近于有效的python代码,对象中所有的键都必须是字符串。如下所示,就是一个JSON的例子:
obj = """
{"name":"Wes",
"places_lived":["United States","Spain","Germany"],
"pet":null,
"siblings":[{"name":"Scott","age":25,"pet":"Zuko"},
{"name":"Katie","age":31,"pet":"Cisco"}]
}
"""许多python库都可以读写JSON数据,在这里我们使用json,它是构建于python标准库中的,通过json.loads即可将JSON字符串转换为python形式:
例1:通过json库的loads()函数读写JSON数据,dumps()函数则是将python对象转换成JSON格式,并且创建一个DataFrame
import json
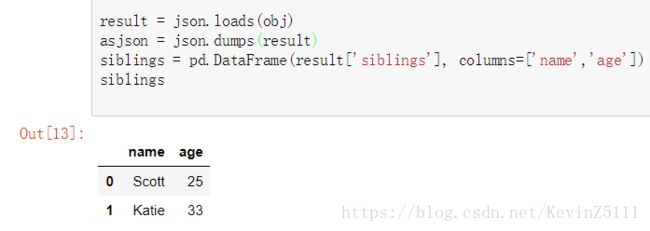
result = json.loads(obj)
asjson = json.dumps(result)
siblings = pd.DataFrame(result['siblings'], columns=['name','age'])
例2:pandas中还有read_json()函数,能直接将JSON字符串转换为DataFrame:
data1 = """
{"columns":["col 1","col 2"],
"index":["row 1","row 2"],
"data":[["a","b"],["c","d"]]}
"""
data2 = """
{"row 1":{"col 1":"a","col 2":"b"},"row 2":{"col 1":"c","col 2":"d"}}
"""
data3 = """
[{"col 1":"a","col 2":"b"},{"col 1":"c","col 2":"d"}]
"""
"""
'split' : dict like {index -> [index], columns -> [columns], data -> [values]}
'index' : dict like {index -> {column -> value}}
'records' : list like [{column -> value}, ... , {column -> value}]
"""
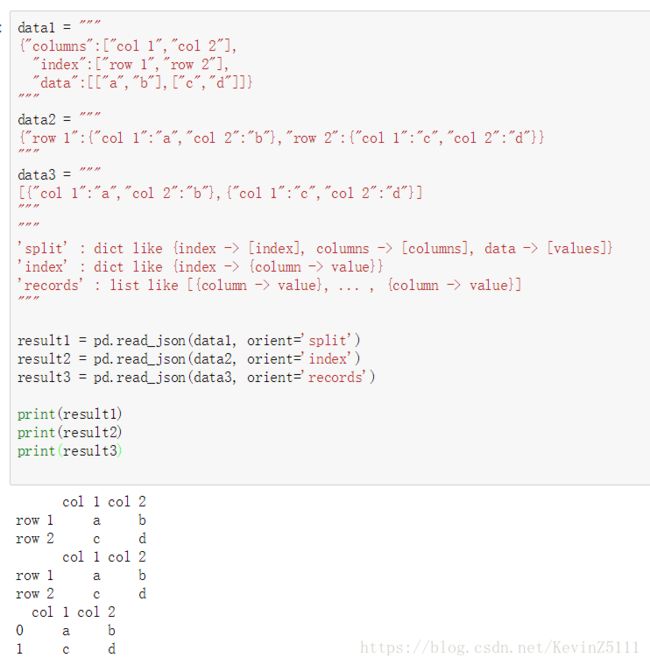
result1 = pd.read_json(data1, orient='split')
result2 = pd.read_json(data2, orient='index')
result3 = pd.read_json(data3, orient='records')
print(result1)
print(result2)
print(result3)
XML和HTML:Web信息收集:
python有许多可以读写HTML和XML格式数据的库,lxml就是其中之一,它能够高效且可靠地解析大文件。我们可以使用lxml.html来处理HTML,使用lxml.objectify来处理XML:
1.使用lxml.html处理HTML:
处理步骤:(1)、首先通过urllib2库中的urlopen()函数打开希望获取数据的URL;
(2)、利用lxml.html库中的parse()函数解析得到数据流;
(3)、利用数据流的getroot()函数,获得文档的根节点;
(4)、使用根节点的findall()函数,获得某个HTML元素对象;
(5)、使用HTML元素的get()函数获得其属性,text_content()函数获得标签的内容;
(6)、再将感兴趣的内容转换为DataFrame;
例:想要得到该文档中所有的URL链接,而HTML中的链接是a标签:
from lxml.html import parse
from urllib2 import urlopen
parsed = parse(urlopen('http://finance.yahoo.com/q/op?s=AAPL+Options'))
doc = parsed.getroot()
links = doc.findall('.//a')
urls = [lnk.get('href') for lnk in links]2.使用lxml.objectify解析XML:
XML(Extensible Markup Language)是另一种常见的支持分层、嵌套数据以及元数据的结构化数据格式。在这里,我们使用lxml.objectify库来操作XML数据。
处理步骤:(1)、先用lxml.objectify解析要操作的文件,返回一个被解析的对象;
(2)、使用被解析对象的getroot()函数,得到该XML文件的根节点的引用;
(3)、
例:假设我们有一个XML文件如下所示,我们想用DataFrame表示数据,则有:
from lxml import objectify
path = 'Performance_MNR.xml'
parsed = objectify.parse(open(path))
root = parsed.getroot()
data = []
skip_fields = ['PARENT_SEQ','INDICATOR_SEQ','DESIRED_CHANGE','DECIMAL_PLACES']
for elt in root.INDICATOR:
el_data = {}
for child in elt.getChildren():
if child.tag in skip_fields:
continue
el_data[child.tag] = child.pyval
data.append(el_data)
perf = pd.DataFrame(data)
二、二进制格式数据:
使用pickle形式:
实现数据的二进制格式存储的最简单的办法之一是使用python内置的pickle序列化,pandas对象都有一个用于将数据以pickle形式保存到磁盘上的save()函数:
frame = pd.read_csv('ch06/ex1.csv')
frame.save('ch06/frame_pickle')
pd.load('ch06/frame_pickle')
使用HDF5格式:
HDF5是一个流行的工业级库,它能实现高效读写磁盘上以二进制格式存储的数据,它是一个C库,带有很多语言的接口,如Java、python、Matlab等。HDF5中的HDF指的是层次型数据格式(hierarchical data format),每个HDF5文件都含有一个文件系统式的节点结构,它使你能够存储多个数据集并支持元数据。与其他简单格式相比,HDF5支持多种压缩器的即时压缩,还能更高效地存储重复模式数据。对于那些非常大的无法直接放入内存的数据集,HDF5就是不错的选择,因为它可以高效地分块读写。
python中的HDF5库有两个接口,即pytables和h5py,pandas有一个最小化的类似于字典的HDFStore类,它通过PyTables存储pandas对象:
store = pd.HDFStore('mydata.h5')
frame = pd.read_csv('ch06/ex1.csv')
store['obj1'] = frame
store['obj1_col'] = frame['a']

HDF5文件中的对象可以通过与字典一样的方式进行获取:
store['obj1']
读取Excel文件:
pandas的ExcelFile类支持读取存储在Excel 2003或更高版本中的表格型数据,通过传入一个xls或xlsx文件的路径就可以创建一个ExcelFile实例,存放在ExcelFile实例的某个工作表可以通过parse读取到DataFrame中:
xls_file = pd.ExcelFile('data.xls')
table = xls_file.parse('Sheet1')
三、使用html和web api:
许多网站都有一些通过JSON或其他格式提供数据的公共API,通过python访问这些API的办法有很多,有一个简单易用的办法是requests包。为了在Twitter上搜索"python pandas",我们可以发送一个HTTP GET请求,具体的如下所示:
import requests
import json
url = 'http://search.twitter.com/search.json?q=python%20pandas'
resp = requests.get(url)
data = json.loads(resp.text)
data.keys()
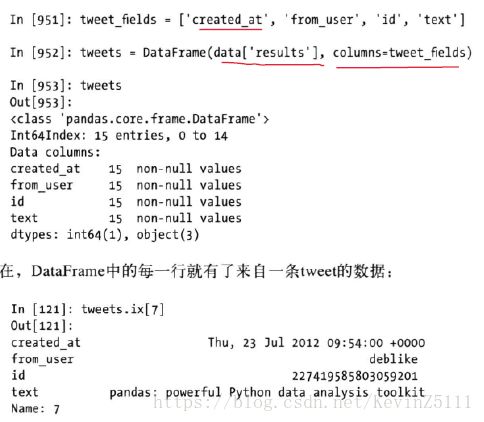
tweet_fields = ['created_at','from_user','id','text']
tweet = pd.DataFrame(data['results'],columns=tweet_fields)requests的get()函数会根据url返回一个Response对象,该对象的text属性含有GET请求的内容。

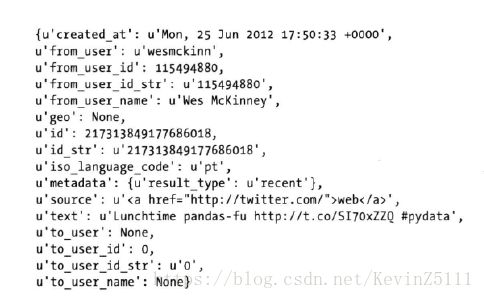
在响应结果中的results字段中含有一组tweet,每条tweet被表示为一个python字典:
最后根据感兴趣的内容,选择相应的字段,创建相应的DataFrame:
四、使用数据库:
使用关系型数据库:
将数据从SQL加载到DataFrame的过程很简单,此外pandas还有一些能够简化该过程的函数,在这里我们使用SQLite数据库:
import sqlite3
# 创建一张表
query = """
create table test(a varchar(20), b varchar(20), c real, d integer);
"""
con = sqlite3.connect(':memory:')
con.execute(query)
con.commit()
# 插入几行数据
data=[('Atlanta','Georgia',1.25,6),
('Tallahassee','Florida',2.6,3),
('Sacramento','California',1.7,5)]
stmt = "insert into test values(?,?,?,?)"
con.executemany(stmt,data)
con.commit()
# 从表中查询数据
cursor = con.execute('select * from test')
rows = cursor.fetchall()
cursor.description
df = pd.DataFrame(rows,columns=zip(*cursor.description)[0])

使用非关系型数据库:
NoSQL数据库有许多不同的形式。有些是简单的字典式键值对存储(如BerkeleyDB和Tokyo Cabinet),另一些则是基于文档的(其中的基本单元是字典型对象)。这里我们选用的是MongoDB,存储在MongoDB中的文档被组织在数据库的集合中,MongoDB服务器的每个运行实例可以有多个数据库,而每个数据库又可以有多个集合。
import pymongo
import requests,json
con = pymongo.Connection('localhost', port=27017)
url = 'http://search.twitter.com/search.json?q=python%20pandas'
data = json.loads(requests.get(url).text)
for tweet in data['results']:
tweets.save(tweet)