ISODATA聚类分析算法原理与C++实现
文章目录
- Kmeans聚类算法的原理
- ISODATA聚类算法的原理
- ISODATA算法的基本步骤
- 关键步骤原理
- 代码实现
- 代码结构
- 主要类实现
- 代码使用
- 代码地址
- 聚类效果分析
- 内容参考
- 最后
最近在填之前的坑,尝试用C++实现一个ISODATA的聚类分析算法,目前代码已经码完了,就慢慢的把文档给补上,记录一下自己零零碎碎做的工作;给自己立的flag画一个句号吧。
Kmeans聚类算法的原理
- 在分析一些数据前,我们需要选取通过一些方式对数据的种类进行划分,“物以类聚,人以群分”,分类是为了进一步的分析数据的性质。
- Kmeans聚类算法的一般步骤为
- 随机选取k个中心点
- 遍历所有样本,将数据划分到最近的中心点中(所谓近,即欧式距离近)
- 计算每个聚类的平均值,得到新的聚类中心
- 重复上述2-3步骤,直至所有中心点趋于收敛(变化幅度较小)或达到一定的迭代次数
- kmeans的原理简单,应用也很多,但是k的选取很重要,如果没有数据的先验知识,可能需要多次尝试不同的k值进行迭代计算,观察效果。
ISODATA聚类算法的原理
- 可以看作Kmeans的一种衍生,既然我们有时候只能大致确定k的范围,而不能确定k,那么可以加入分裂、合并机制,通过更自动化的机制,灵活的确定k的值
ISODATA算法的基本步骤
-
参数设置,需要设置的参数包括:
- nc : 初始聚类中心个数
- c : 预期的聚类个数
- tn : 每一类中允许的样本最少数目(少于该数目的聚类可能会被删除)
- te : 类内相对标准差上限(超过该上限的聚类,可能会被分裂)
- tc : 聚类中心点之间的最小距离
- nt : 每次迭代中最多可以合并的次数
- ns : 最多迭代次数
-
初始化
- 在所有样本中,随机选取nc个不重复样本作为聚类中心,之后根据距离最小法判断所有样本属于哪一种聚类
- 对第一次初始化后的聚类,检测是否符合tn条件,样本数目小于tn的类别被取消,重新根据上一步的距离最小法进行分配
-
计算分类后的聚类参数,包含以下参数:
- 聚类中心
- 各类中样本到聚类中心的平均距离
- 各个样本到其所属类别中心的总体平均距离
-
根据当前的状态选择下一步的行为,进行分裂、合并或停止
- 若迭代次数达到要求,则停止
- 若当前聚类数量小于期望数量的一般,则进行分裂检测,判断当前是否需要分裂,若需要则执行分裂行为
- 若聚类数量大于期望数量的两倍,则进行合并检测,判断是否需要合并,若需要则执行合并行为
- 若聚类数量在期望聚类数量的1/2到2倍之间,奇数次迭代则执行分裂检测,偶数次迭代则进行合并检测
关键步骤原理
- 分裂检测步骤
- 计算各个类别中,各个样本到类别中心的标准差,标准差为一矢量,求出每一类内标准差向量中的最大分量
- 若标准差向量中的最大分量大于te,同时满足以下条件之一,则对该类别进行分裂
- 聚类个数小于期望个数一半
- 聚类内部平均距离大于总体平均距离且聚类样本数量大于tn两倍
- 分裂操作:
- 在类内标准差最大的维度上分裂聚类中心点
- 利用距离最小法将当前聚类的样本点分配到两个聚类中
- 更新平均距离等聚类参数
- 合并检测步骤
- 计算聚类中心两两之间的距离,距离小于tc的聚类对,按照距离越小优先级越大的原则,进行合并
- 合并的总次数小于设定值,且一次迭代中,一个聚类只能被合并一次
- 更新聚类参数
代码实现
代码结构
- Cluster.h/cpp : 聚类结构体
- common.h.cpp : 公共函数,包含一些矢量的操作符重载,主要为了编程时候的便捷
- isodata.h/cpp : isodata聚类分析算法类
- error.h : 定义了一些出错的输出字符,为了简便,会做一些出错的检查,然后报出错误,用于提示,但是本身不会做额外错误处理
主要类实现
- Cluster
//Cluster.h
//
// Created by Jeff on 2019/1/6 0006.
//
#ifndef ISODATA_CLUSTER_H
#define ISODATA_CLUSTER_H
#include - ISODATA
//
// Created by Jeff on 2019/1/2 0002.
//
#ifndef ISODATA_ISODATA_H
#define ISODATA_ISODATA_H
#include 代码使用
- 只需要包含isodata一个头文件即可
- 我提供了一份数据和使用样例
- 使用前需要自定义读数据的函数,在common.cpp中,自定义read_data函数即可
- 新建isodata对象,初始化参数
- 调用成员函数run
- 具体如下所示
#include "isodata.h"
#include "MyTime.h"
/**
* 在运行前,需要自定义common.cpp中的read_data函数
* @return
*/
int main() {
CMyTimeWrapper c;
c.tic();
isodata isodata1(4, 90, 10, 90, 20, 5, 500, read_data);
isodata1.run();
c.tocMs();
return 0;
}
- 聚类分析的结果保存在txt文件中,具体见isodata中的output函数,命令行输出的结果如下所示
Original Data Number : 927
Cluster Number : 4
Number 1 : 25
cluster center : 4.77319,16.0967
Number 2 : 604
cluster center : 30.4196,-2.65259
Number 3 : 277
cluster center : 33.988,24.7817
Number 4 : 21
cluster center : -18.4698,-33.7524
cost time: 239.088 ms
代码地址
- Github
聚类效果分析
- 利用python将聚类分析的结果绘制出来,结果如下
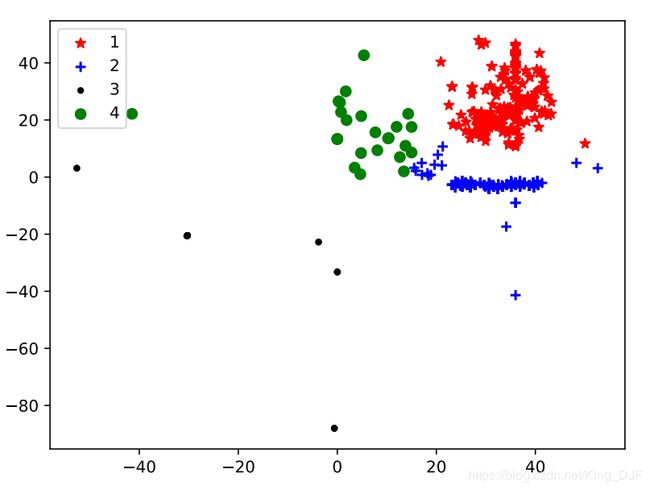
内容参考
- 李伯韬的博客
- 华东 博客
最后
觉得文章对你有帮助的,欢迎扫码关注我的公众号,我会时不时的分享我的学习经验、收获。
