爬虫学习笔记——Selenium爬取淘宝商品信息并保存
在使用selenium来模拟浏览器操作,抓取淘宝商品信息前,先完成一些准备工作。
准备工作:需要安装selenium,pyquery,以及Chrome浏览器并配置ChromeDriver。
安装selenium:pip install selenium
安装pyquery:pip install pyquery
ChromeDriver配置:参考Window 下配置ChromeDriver
做好这些之后开始进入正题:选择各类品牌男鞋从销量高到低进行爬取
1、突破反爬虫
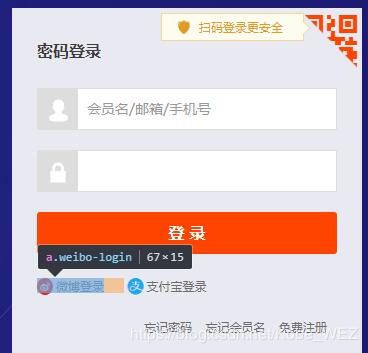
要爬取淘宝首先要突破淘宝的反爬机制,这里用selenium模拟器微博登陆淘宝
通过模拟点击网页输入登陆淘宝
#对象初始化
def __init__(self):
url = 'https://login.taobao.com/member/login.jhtml'
self.url = url
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
self.browser = webdriver.Chrome(options=options)
self.wait = WebDriverWait(self.browser, 10) #超时时长为10s
#登录淘宝
def login(self):
# 打开网页
self.browser.get(self.url)
# 自适应等待,点击密码登录选项
self.browser.implicitly_wait(30) #智能等待,直到网页加载完毕,最长等待时间为30s
self.browser.find_element_by_xpath('//*[@class="forget-pwd J_Quick2Static"]').click()
# 自适应等待,点击微博登录宣传
self.browser.implicitly_wait(30)
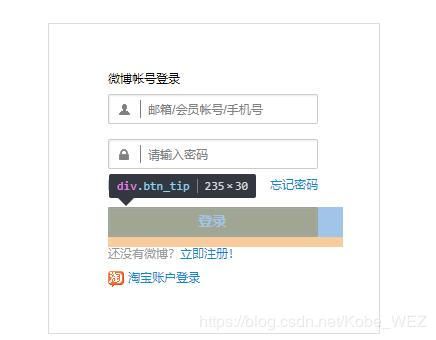
self.browser.find_element_by_xpath('//*[@class="weibo-login"]').click()
# 自适应等待,输入微博账号
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('username').send_keys(weibo_username)
# 自适应等待,输入微博密码
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('password').send_keys(weibo_password)
# 自适应等待,点击确认登录按钮
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click()
# 直到获取到淘宝会员昵称才能确定是登录成功
taobao_name = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ')))
# 输出淘宝昵称
print(taobao_name.text)
2、页面爬取
根据类别商品对应的元素进行爬取

data=["20578","20579","29529","3424764","29510","20069292","3227291",
"20592","49429","31840","40843","20581","32462"]
num=["0","44","88"]
# 对我已买到的宝贝商品数据进行爬虫
for i in range(len(data)):
for j in range(len(num)):
self.browser.get("https://s.taobao.com/search?q=%E7%94%B7%E9%9E%8B&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20190403&ie=utf8&cps=yes&ppath=20000%3A"+data[i]+"&sort=sale-desc"+"&bcoffset=0&p4ppushleft=%2C44&s="+num[j])
# 遍历所有页数
#for page in range(1,13):
# 等待该页面全部已买到的宝贝商品数据加载完毕
#good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist > div.J_MouserOnverReq')))
# 获取本页面源代码
html = self.browser.page_source
# pq模块解析网页源代码
doc = pq(html)
3、信息爬取
这里爬取商品的价格、销量、介绍、地址和图片链接
# 遍历该页的所有宝贝
data1=[]
taobao_data1=[]
for item in good_items:
money = item.find('.g_price-highlight').text().replace('\n', "").replace('\r', "")
number = item.find('.deal-cnt').text().replace('\n', "").replace('\r', "")
Introduction = item.find('.row.row-2.title').text().replace('\n', "").replace('\r', "")
location = item.find('.row.row-3.g-clearfix').text().replace('\n', "").replace('\r', "")
href=item.find('.J_ItemPic.img').attr("data-src")
print(money, number, Introduction, location,href)
data1.append([money, number, Introduction,location,href])
4、信息存储
这里把爬取的信息放入json文件
for each in data1:
taobao_data1.append({
"money": each[0],
"number": each[1],
"Introduction": each[2],
"location": each[3],
"href": each[4]
})
with open('hello.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(taobao_data1, indent=2, ensure_ascii=False))
最后附上完整代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
from time import sleep
import random
import json
import time
#定义一个taobao类
class taobao_infos:
#对象初始化
def __init__(self):
url = 'https://login.taobao.com/member/login.jhtml'
self.url = url
options = webdriver.ChromeOptions()
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
self.browser = webdriver.Chrome(options=options)
self.wait = WebDriverWait(self.browser, 10) #超时时长为10s
#登录淘宝
def login(self):
# 打开网页
self.browser.get(self.url)
# 自适应等待,点击密码登录选项
self.browser.implicitly_wait(30) #智能等待,直到网页加载完毕,最长等待时间为30s
self.browser.find_element_by_xpath('//*[@class="forget-pwd J_Quick2Static"]').click()
# 自适应等待,点击微博登录宣传
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="weibo-login"]').click()
# 自适应等待,输入微博账号
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('username').send_keys(weibo_username)
# 自适应等待,输入微博密码
self.browser.implicitly_wait(30)
self.browser.find_element_by_name('password').send_keys(weibo_password)
# 自适应等待,点击确认登录按钮
self.browser.implicitly_wait(30)
self.browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click()
# 直到获取到淘宝会员昵称才能确定是登录成功
taobao_name = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ')))
# 输出淘宝昵称
print(taobao_name.text)
# 模拟向下滑动浏览
def swipe_down(self,second):
for i in range(int(second/0.1)):
#根据i的值,模拟上下滑动
if(i%2==0):
js = "var q=document.documentElement.scrollTop=" + str(300+400*i)
else:
js = "var q=document.documentElement.scrollTop=" + str(200 * i)
self.browser.execute_script(js)
sleep(0.1)
js = "var q=document.documentElement.scrollTop=100000"
self.browser.execute_script(js)
sleep(0.1)
# 爬取淘宝 我已买到的宝贝商品数据
def crawl_good_buy_data(self):
data=["20578","20579","29529","3424764","29510","20069292","3227291",
"20592","49429","31840","40843","20581","32462"]
num=["0","44","88"]
# 对我已买到的宝贝商品数据进行爬虫
for i in range(len(data)):
for j in range(len(num)):
self.browser.get("https://s.taobao.com/search?q=%E7%94%B7%E9%9E%8B&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20190403&ie=utf8&cps=yes&ppath=20000%3A"+data[i]+"&sort=sale-desc"+"&bcoffset=0&p4ppushleft=%2C44&s="+num[j])
# 遍历所有页数
#for page in range(1,13):
# 等待该页面全部已买到的宝贝商品数据加载完毕
#good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist > div.J_MouserOnverReq')))
# 获取本页面源代码
html = self.browser.page_source
# pq模块解析网页源代码
doc = pq(html)
# # 存储该页已经买到的宝贝数据
good_items = doc('#mainsrp-itemlist .J_MouserOnverReq').items()
# 遍历该页的所有宝贝
data1=[]
taobao_data1=[]
for item in good_items:
money = item.find('.g_price-highlight').text().replace('\n', "").replace('\r', "")
number = item.find('.deal-cnt').text().replace('\n', "").replace('\r', "")
Introduction = item.find('.row.row-2.title').text().replace('\n', "").replace('\r', "")
location = item.find('.row.row-3.g-clearfix').text().replace('\n', "").replace('\r', "")
href=item.find('.J_ItemPic.img').attr("data-src")
print(money, number, Introduction, location,href)
data1.append([money, number, Introduction,location,href])
for each in data1:
taobao_data1.append({
"money": each[0],
"number": each[1],
"Introduction": each[2],
"location": each[3],
"href": each[4]
})
with open('hello.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(taobao_data1, indent=2, ensure_ascii=False))
print('\n\n')
# 大部分人被检测为机器人就是因为进一步模拟人工操作
# 模拟人工向下浏览商品,即进行模拟下滑操作,防止被识别出是机器人
# 随机滑动延时时间
swipe_time = random.randint(1, 3)
self.swipe_down(swipe_time)
sleep(2)
print('\n\n')
if __name__ == "__main__":
weibo_username ='xxxxxxxx" #改成你的微博账号
weibo_password = "xxxxxxxx" #改成你的微博密码
a = taobao_infos()
a.login() #登录
a.crawl_good_buy_data() #爬取淘宝 我已买到的宝贝商品数据