视频内容理解相关方法
数据采样总结
Kinetics:
- non-local: 原视频中随机切64帧连续帧,然后取32帧+空间crop作为输入。git上作者是说原视频中随机隔M帧采一帧共采N帧,短clip为(N,M)=(32,2),长的为(128,1)。测试时:原视频采10个clip跑网络,将结果平均。
- I3D:好像没有具体说,输入是64-frame。
- C3D: 一个视频随机取5个2秒钟的clip,图像resize到128x171,然后随机crop到16x112x112作为网络的输入。
Youtube-8M:
- 每秒采一帧,一个视频最多360帧,抽InceptionV2特征。
提升点
- two-stream:除non-local外的方法,使用flow信息都有很大的提升。
- temporal信息:在整个网络中利用temporal信息(C3D,I3D,P3D,non-local)。
- 在imageNet、Kinetics上预训练。
- 对于多标签:Context Gating。
- 使用更长的temporal:但也会增加计算量。很多方法像C3D、I3D、P3D等虽然test时会在整个视频中取clip再综合结果,但是这些网络的训练仅在clip上,多clip并没有训练。多clip的融合可尝试通过aggregation再训练。
- 多分类使用MoE,3D-Net + MoE。
Test
youtube-8m中,eval_util.py中的calculate_gap函数
输入:[Batch x num_classes],此函数将每个video预测得分num_classes中的topk取出来,串成一个大的预测数组,即Batch x topk个数据,去计算AP。计算公式为:

其中i的范围在这个函数中并非20,i最大值为标签中正标签的数值total_positive,r(i)固定为1 / total_postitve。这里就会有个问题,即GAP算出的最大值不为1,因为topk中的正标签数total_positive_topk可能小于total_positive,GAP的最大值为total_positive_topk / total_postitve。
NetVLAD: CNN architecture for weakly supervised place recognition
youtube-8M比赛第一名中用到的部分网络结构,在这里放在前面。本文是做场景识别的,场景识别有几个难点,图像中对于场景识别的无用信息比较多(例如人、车等),全景数据并非由某个部分属于某个场景的标签。
本文将VLAD方法融入cnn的结构,并进行end-to-end训练,相比使用训好的模型直接抽特征,效果更好。另外改进了triploss做弱监督学习。

作者将原始的VLAD的hard assignment换成了soft assignment,因为hard无法反向求导。soft的其实就是换成了个softmax。

这样整个VLAD的部分就可以求导,只植入cnn作为一个层。
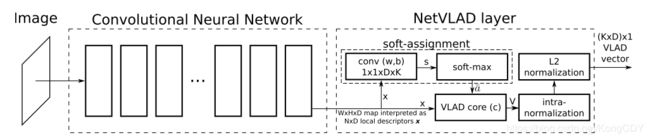
其中K是聚类数,D是cnn最后输出的通道数(可以当成featuremap每个像素的维度)
本质上是学习了一个cnn最后一层特征的每个像素对聚类中心的权重,比如场景中车、人部分的权重就小,相加并normalize后就加大了其他部分的权重,更适合场景分类。另外。softmax的权重跟聚类中心都是学习出来的,也就是聚类数是个超参。
除此之外,还有个Weakly supervised triplet ranking loss,没太细看。
Learnable pooling with Context Gating for video classification
youtube-8M比赛的第一名的论文。先说下youtube-8M数据集,是谷歌搞的8百万视频理解数据,有4800类。每个视频是多标签的,其标签为最简短描述视频主题的,而非所有视频中出现的事物。为方便比赛使用,谷歌将视频每秒一帧最对360秒进行采样,并用inception抽特征,之后使用pca白化降维,图像特征1024维,音频128维。参赛者直接使用此特征进行比赛。谷歌关注点维如何使用视频的特征进行分类。
本文结构如下:
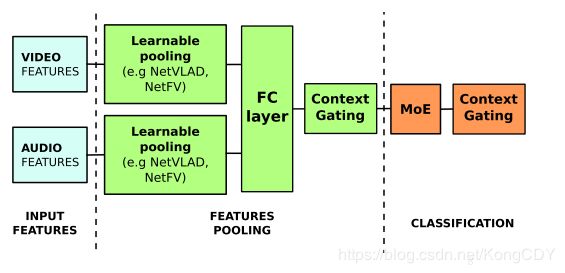
其中Context Gating为本文提出的结构,主要通过一个门操作来选特征,因为有些特征对于视频的内容并没有贡献。
![]()
Learnable pooling部分为特征的aggregation,作者用上面的NetVALD,以及一些扩展,都差不多,公式上有些许不同。
另外,作者有多次提到learnable pooling部分分时序方法(LSTM,GRU)及aggregation方法,其中时序方法作者尝试没有aggregation好,并且时序的作用在视频理解中似乎并不重要,即使将帧shuffle了也几乎没有影响,那么使用时序方法必要性就不大,还会损失信息。这可能也是视频理解跟行为识别的差别吧。
as almost all of the relevant signal relies on the static visual cues. All we actually need to do is to find a way to efficiently remember all of the relevant visual cues.
最后,作者说多个模型ensemble可以进一步提升效果,一个最高83.2,7个84.7,25个85。看来越多性能提升也越少了。
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding
第三名的百度的方法,总的来看并没有提出什么新的结构,主要是时序模型的使用。单模型GAP最高0.827,似乎比第二名清华的单模型要好一些。最终提交的57个模型ensemble达到0.845

单模型最高是这个结构,lstm输出之后通过一个fc来融合lstm之前跟之后的特征。
ActionVLAD: Learning spatio-temporal aggregation for action classification
此论文是NetVLAD的扩展,扩展到了时序上,公式仅多了个时间维度的加权:

严格来讲此方法考虑到了时间轴,或者说融合了时间轴,单并非时序。
网络已vgg为基础提特征,之后通过这个layer进行aggregation。输入也可以结合Flow信息。作者做了一些实验,结论:
- 特征使用fc前的conv特征效果更好,因为fc前的特征具有空间信息,可以更好的利用vlad层的优势。相当于通过vlad对空间进行加权,而非fc。这个结论或许我们会用到。
- 结合Flow信息的方式,Late fusion的方式更好,及两个分支完全分开,独立的vlad层后再cat。
- 另外,从各个实验结果上来看,单独使用Flow比单独使用RGB的效果要好很多。不过本篇是做动作识别的,更侧重动作上的变化。视频内容理解方面或许就不是了,这个更侧重内容。
Non-local Neural Networks
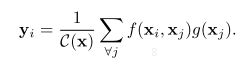
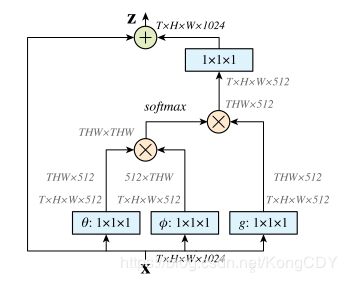
non-local的思想,融合空间跟时间的信息。结构可以植入各种网络结构中,可以加在预训练的网络里。
测试用的基网络是基于ResNet50根ResNet101,单RGB,不使用Flow。
- C2D与NL-C2D比较,加NL更好,说明NL可以捕获空间跟时间的关系。
- 不同的距离函数效果差别不大,说明距离函数不是提升点的关键。
- non-local插入的位置,在后面效果会差,猜测可能后面的空间信息不够。
- non-local越多效果提升越多,但并非是因为non-local增加了深度
- non-loca跟i3d相比,non-loca提升多一些。在i3d基础上增加NL可以进一步提升效果。
Exploiting Feature and Class Relationships in Video Categorization with Regularized Deep Neural Networks
LSVC数据提供方及比赛举办方。论文在目标函数的正则化项做了些工作,想要捕捉特征间的关系及标签间的关系。
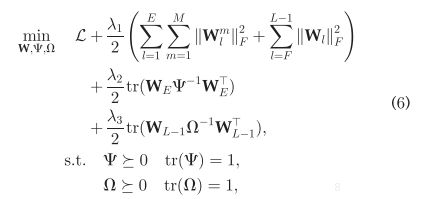
正则化项使用的MTL多任务学习里的方法,这个具体还没看过。
更新的时候这样更新那两个矩阵(所以这两个矩阵并不参与反传)
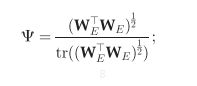
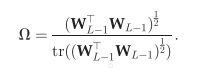
另外作者最后提了一句少数据的情况效果也还行……
Learning Spatiotemporal Features with 3D Convolutional Networks

C3D算法,用3D卷积及3D pooling捕捉时序信息。作者做了很多实验来探索卷积核变化的影响,结论:
- 3 x 3 x 3卷积核效果最好。跟2D图像有相同的结论。
另外,第一个pooling在时序上不降采样,为了在前面阶段多保留时序信息。
作者训练时的数据处理: 一个视频随机取5个2秒钟的clip,图像resize到128x171,然后随机crop到16x112x112作为网络的输入,视频图像50%概率水平flip。
测试时的视频特征抽取: 视频按16帧clip,每个clip的overlap是8帧,将所有clip走网络之后的特征求平均并L2norm作为视频特征(这里可以走VLAD aggregation)
从实验结果上来看: 单C3D比其他单模型要好一些。C3D+iDT效果较two-stream及long clip差不太多。
纵观整个论文,C3D的网络结构都比较浅,即使使用多个C3D也米有加深本身的深度,可能更深的结构不好训练?参数太多。
Action Recognition? A New Model and the Kinetics Dataset
I3D算法,文章先将在imagenet预训练的网络的卷积核扩张为3D卷积,具体做法是沿着时间维度重复2D滤波器权重N次,并且通过除以N将它们重新缩放。然后在Kinetics上训练,最后在其他数据集上fine-tune,可以取得更好的效果。文章的网络是基于InceptionV1的Two-stream 3D-Conv网络,

网络前面没有在时序上做pooling
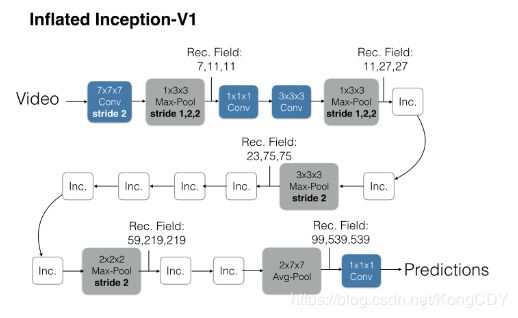
训练的时候将每一条视频采样64帧作为一个样本,测试时将全部的视频帧放进去最后average_score。主网络为加BN的InceptionV1,除最后一个卷积层之外,在每一个都加上BN层和Relu。
光流使用TV-L1算法
- two-stream I3D效果更好
- 单flow效果在UCF-101跟HMDB-51上比单rgb好很多,在Kinects上要差一些。猜测可能Kinects上的镜头变化比较大,flow的计算会不准确。
- ImageNet上预训练的base网络扩成3D版,比随机初始化的效果好。
- Kinetics上预训练比只用ImageNet预训练更好。
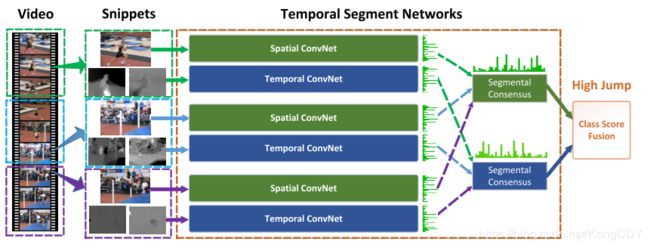
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
TSN算法,使用双流网络,一个输入rgb,一个输入stack flow
Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
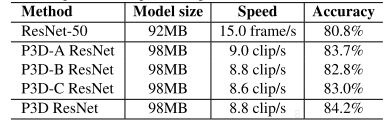
P3D算法,来自MSRA。也是一篇将2D图像预训练网络扩张成3D网络的方法,但并不是直接扩展2D卷积核,而是增加了一个时域的卷积核 t x 1 x 1, 在原网络的基础上,可以更少的增加参数。
P3D blocks的不同加法:
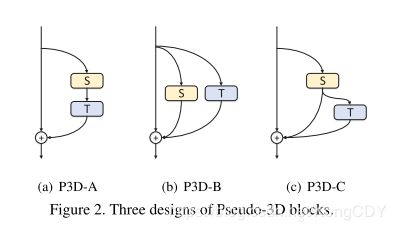
对应到bottleneck中:
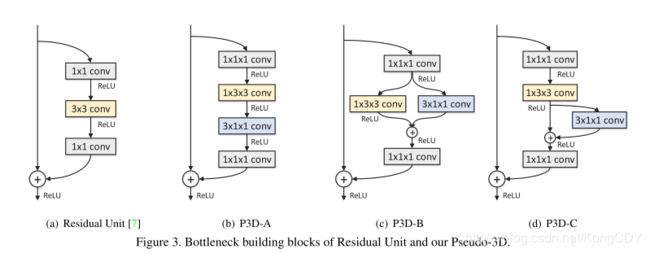
最终的网络是混合ABC三种方式的网络。
论文中作者有说3D卷积的参数很多,C3D的11层也比199层的P3D ResNet的参数要多。P3D的效果是比C3D要好的。但个人感觉这不仅仅是增加了时间域卷积的原因,也因为ResNet的层数多(50、152层)。对于识别来讲,层数深更容易获得高层语义,更加利于分类问题,然而C3D只有11层,虽然参数很多,但这是在宽度上。I3D效果就好很多了。
所以这种2D到3D的扩张方式会有一定用处,但个人认为肯定不如方形3D卷积跟nonlocal,对于参数有限制的情况,提供了一种方式。
Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet
作者将现在的一些主流方法以resnet为基网络在四大动作识别测试集上做测试(UCF-101,HMDB-51,ActivityNet,Kinetics),以验证更深的3D网络的效果。并开放了预训练的模型。
-
小网络ResNet-18在各个数据集上的效果:
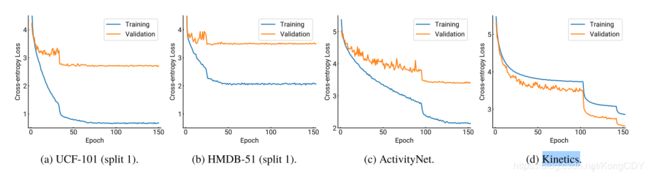
可以看出对于小数据集主要是过拟合
-
网络深度影响(Kinetics):

很明显,加深在大数据集上是有用处的。
-
对于不同的ResNet版本,ResNetXt的效果最好
-
小数据集上finetune,只训最后两层,效果当然好。
不过作者没有尝试从imagenet预训练的2D网络扩成3D网络再在视频数据集上训,都是直接随机初始化训练的
Video Classification with Channel-Separated Convolutional Networks(2019.4)
这篇文章主要调研了group conv这类方式的卷积在3D卷积上的应用,mobilenet等网络使用depthwise conv等group的方式降低了很大的计算量,而且保证了一定程度的准确率。
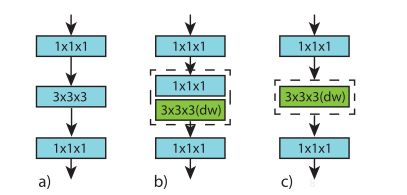
b(ip-CSN)跟c(ir-CSN)的两种方式,作者的实验在深度加大之后,bc的效果差距会降低,b会略好一点。
另外作者探究了其原因,主要是参数少降低过拟合使得测试效果更好。就训练loss而言a更低。
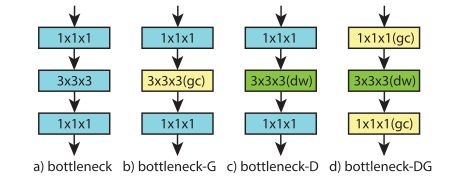
ResNet的bottleneck,其中b就是ResNeXt,c跟上面的c一样(ir-CSN),作者的实验是c最好。
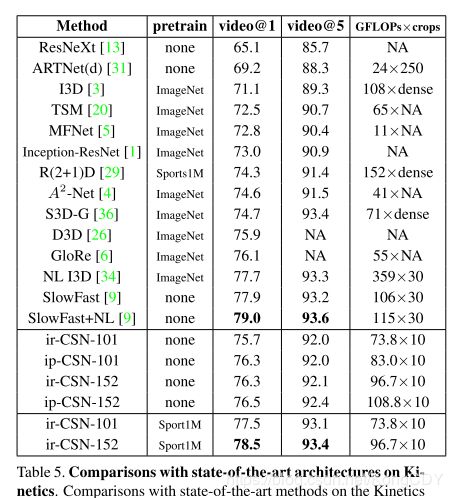
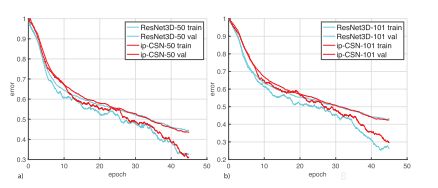
Kinetics上的实验,效果上最好的跟主流的差不多,单参数更少。加上NL也许会更好。测试比较上因为clip数不一样,所以像SlowFast的结果也不太好比较,他俩的GFLOPs倒差不多。
SlowFast Networks for Video Recognition(2018.10)
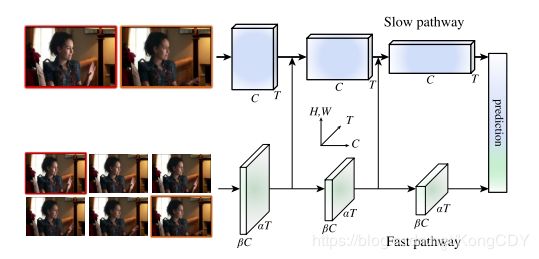
本论文两个分支都输入图像(rgb跟gray,非flow)。其中一个分支主要捕获空间信息,时间采样率很低,叫SlowPath。另一个分支主要捕获时间信息,采样率很高,但channel数少,以降低此分支的计算量。并且在时间维度没有降采样,叫FastPath。
- SlowPath:可以使用一般的3D网络,采样率很低,30fps的视频每秒2帧。另外,作者发现在后面使用3D卷积,前面不用,效果更好。更早使用时间维度的卷积会降低效果。猜测低采样率使得帧与帧的相关性不大。
- FastPath:高采样率,采样率是SlowPath的8倍。时间维度没有降采样,一直保留到最后。低通道数,通道数是SlowPath的1/8,可以降低计算量。作者也有做实验输入将rgb改为gray,对结果影响不大。因为此path关注的不是空间。
- Fuse:网络中间有单向连接(双向作者尝试结果差不多),由Fast到Slow。有多重融合方式,其中在FastPath的特征中使用5x1x1的卷积控制长度效果更好。最后的特征两个分支分别global pooling后cat起来,再分类。
实验上来看,SlowFast即使没有使用ImageNet预训练,也有很好的效果。另外,作者的训练策略也值得参考。此方法加上NL可以达到目前最高的效果(Kinetics上)
SCSampler: Sampling Salient Clips from Video for Efficient Action Recognition
本文关注如何从一段untrimmed的视频中选取对分类有意义的clips,来提高视频分类模型的效果。方法大体上来看是训练一个弱分类器来对所有clips分类,取topK端clips用于视频分类。做了挺多实验,没有细看。
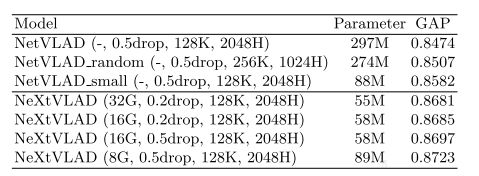
NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification(2018.11)
第二届youtube-8m比赛第三名。方法主要基于第一届的第一名进行的一定改进。如下:
- 首先是NetVLAD的部分,将输入特征分多个Group,Group间通过Attention加权,加权结果再走VLAD,目的是为了减少参数量。
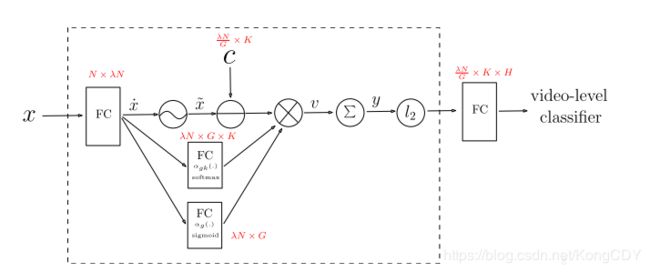
- 其次,context gating的部分,类似bottleneck那样进行了降为处理,也是为了减少参数量。
- 最后,使用了个蒸馏方式进行训练

实验结果比第一届第一名的高一些,单模型效果还不错。
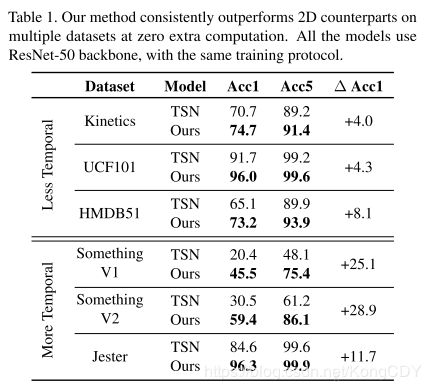
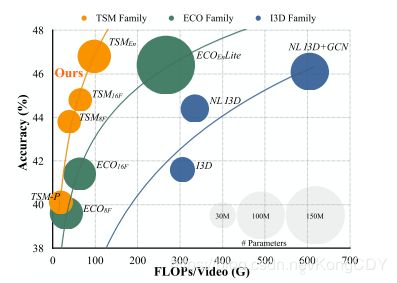
TSM: Temporal Shift Module for Efficient Video Understanding(2019.3)
本文在2D网络基础上,在时间轴上加上featuremap的shift,使得卷积核在时间轴上有一定的感受野,给2D网络增加时序性能。
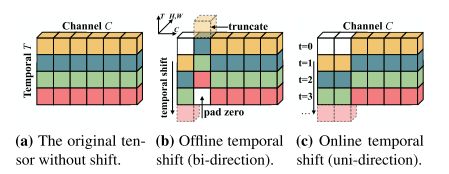
(a)是2D网络,(b)是featuremap上双向shift,offline做法。(c)是单向shift,online做法。
作者尝试了两种插入shift的方式,一种是(a)在卷积层前面加,另一种是(b)在残差网络的旁支的卷积层前加。实验结果(b)要好,因为(a)的方式会影响空间特征的学习,(b)可以通过残差分支把空间特征传过来。

Shift的大小不能太小,时间能力会变差,太大空间能力会变差,作者的实验1/4比较好。