woe第二集
自动最优分箱函数,基于卡方检验的分箱
def graphforbestbin(DF, X, Y, n=5,q=20,graph=True):
'''
参数:
DF: 需要输入的数据
X: 需要分箱的列名
Y: 分箱数据对应的标签 Y 列名
n: 保留分箱个数
q: 初始分箱的个数
graph: 是否要画出IV图像
区间为前开后闭 (]
'''
DF = DF[[X,Y]].copy()
DF["qcut"],bins = pd.qcut(DF[X], retbins=True, q=q,duplicates="drop")
coount_y0 = DF.loc[DF[Y]==0].groupby(by="qcut").count()[Y]
coount_y1 = DF.loc[DF[Y]==1].groupby(by="qcut").count()[Y]
num_bins = [*zip(bins,bins[1:],coount_y0,coount_y1)]
for i in range(q):
if 0 in num_bins[0][2:]:
num_bins[0:2] = [(
num_bins[0][0],
num_bins[1][1],
num_bins[0][2]+num_bins[1][2],
num_bins[0][3]+num_bins[1][3])]
continue
for i in range(len(num_bins)):
if 0 in num_bins[i][2:]:
num_bins[i-1:i+1] = [(
num_bins[i-1][0],
num_bins[i][1],
num_bins[i-1][2]+num_bins[i][2],
num_bins[i-1][3]+num_bins[i][3])]
break
else:
break
def get_woe(num_bins):
columns = ["min","max","count_0","count_1"]
df = pd.DataFrame(num_bins,columns=columns)
df["total"] = df.count_0 + df.count_1
df["percentage"] = df.total / df.total.sum()
df["bad_rate"] = df.count_1 / df.total
df["good%"] = df.count_0/df.count_0.sum()
df["bad%"] = df.count_1/df.count_1.sum()
df["woe"] = np.log(df["good%"] / df["bad%"])
return df
def get_iv(df):
rate = df["good%"] - df["bad%"]
iv = np.sum(rate * df.woe)
return iv
IV = []
axisx = []
while len(num_bins) > n:
pvs = []
for i in range(len(num_bins)-1):
x1 = num_bins[i][2:]
x2 = num_bins[i+1][2:]
pv = scipy.stats.chi2_contingency([x1,x2])[1]
pvs.append(pv)
i = pvs.index(max(pvs))
num_bins[i:i+2] = [(
num_bins[i][0],
num_bins[i+1][1],
num_bins[i][2]+num_bins[i+1][2],
num_bins[i][3]+num_bins[i+1][3])]
bins_df = pd.DataFrame(get_woe(num_bins))
axisx.append(len(num_bins))
IV.append(get_iv(bins_df))
if graph:
plt.figure()
plt.plot(axisx,IV)
plt.xticks(axisx)
plt.xlabel("number of box")
plt.ylabel("IV")
plt.show()
return bins_df
model_data.columns

for i in model_data.columns[1:-1]:
print(i)
graphforbestbin(model_data,i,"SeriousDlqin2yrs",n=2,q=20)

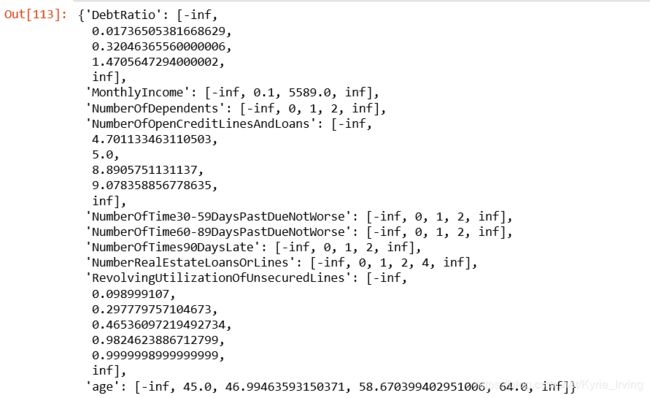
auto_col_bins = {"RevolvingUtilizationOfUnsecuredLines":6,
"age":5,
"DebtRatio":4,
"MonthlyIncome":3,
"NumberOfOpenCreditLinesAndLoans":5}
#不能使用自动分箱的变量
hand_bins = {"NumberOfTime30-59DaysPastDueNotWorse":[0,1,2,13]
,"NumberOfTimes90DaysLate":[0,1,2,17]
,"NumberRealEstateLoansOrLines":[0,1,2,4,54]
,"NumberOfTime60-89DaysPastDueNotWorse":[0,1,2,8]
,"NumberOfDependents":[0,1,2,3]}
#保证区间覆盖使用 np.inf替换最大值,用-np.inf替换最小值
#原因:比如一些新的值出现,例如家庭人数为30,以前没出现过,改成范围为极大值之后,这些新值就都能分到箱里边了
hand_bins = {k:[-np.inf,*v[:-1],np.inf] for k,v in hand_bins.items()}
生成自动分箱的分箱区间和分箱后的 IV 值
for col in auto_col_bins:
bins_df = graphforbestbin(model_data,col
,"SeriousDlqin2yrs"
,n=auto_col_bins[col]
#使用字典的性质来取出每个特征所对应的箱的数量
,q=20
,graph=False)
bins_list = sorted(set(bins_df["min"]).union(bins_df["max"]))
#保证区间覆盖使用 np.inf 替换最大值 -np.inf 替换最小值
bins_list[0],bins_list[-1] = -np.inf,np.inf
bins_of_col[col] = bins_list
#合并手动分箱数据
bins_of_col.update(hand_bins)
bins_of_col
data = model_data.copy()
#函数pd.cut,可以根据已知的分箱间隔把数据分箱
#参数为 pd.cut(数据,以列表表示的分箱间隔)
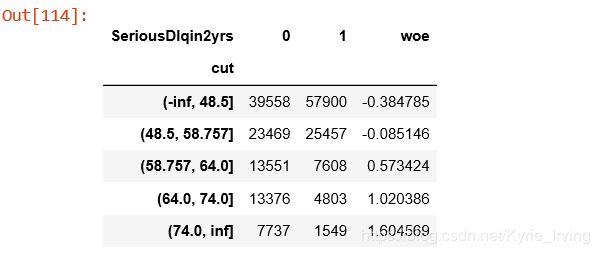
data = data[["age","SeriousDlqin2yrs"]].copy()
data["cut"] = pd.cut(data["age"],[-np.inf, 48.49986200790144, 58.757170160044694, 64.0, 74.0, np.inf])
data.head()
#将数据按分箱结果聚合,并取出其中的标签值
data.groupby("cut")["SeriousDlqin2yrs"].value_counts()
#使用unstack()来将树状结构变成表状结构
data.groupby("cut")["SeriousDlqin2yrs"].value_counts().unstack()
bins_df = data.groupby("cut")["SeriousDlqin2yrs"].value_counts().unstack()
bins_df["woe"] = np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
bins_df
def get_woe(df,col,y,bins):
df = df[[col,y]].copy()
df["cut"] = pd.cut(df[col],bins)
bins_df = df.groupby("cut")[y].value_counts().unstack()
woe = bins_df["woe"] = np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
return woe
#将所有特征的WOE存储到字典当中
woeall = {}
for col in bins_of_col:
woeall[col] = get_woe(model_data,col,"SeriousDlqin2yrs",bins_of_col[col])
woeall

得到建模数据
#不希望覆盖掉原本的数据,创建一个新的DataFrame,索引和原始数据model_data一模一样
model_woe = pd.DataFrame(index=model_data.index)
#将原数据分箱后,按箱的结果把WOE结构用map函数映射到数据中
model_woe["age"] = pd.cut(model_data["age"],bins_of_col["age"]).map(woeall["age"])
#对所有特征操作可以写成:
for col in bins_of_col:
model_woe[col] = pd.cut(model_data[col],bins_of_col[col]).map(woeall[col])
#将标签补充到数据中
model_woe["SeriousDlqin2yrs"] = model_data["SeriousDlqin2yrs"]
#这就是我们的建模数据了
model_woe.head()
vali_woe = pd.DataFrame(index=vali_data.index)
for col in bins_of_col:
vali_woe[col] = pd.cut(vali_data[col],bins_of_col[col]).map(woeall[col])
vali_woe["SeriousDlqin2yrs"] = vali_data["SeriousDlqin2yrs"]
vali_X = vali_woe.iloc[:,:-1]
vali_y = vali_woe.iloc[:,-1]
X = model_woe.iloc[:,:-1]
y = model_woe.iloc[:,-1]
from sklearn.linear_model import LogisticRegression as LR
lr = LR().fit(X,y)
lr.score(vali_X,vali_y)#0.8641356370249832
找最优正则化强度C
c_1 = np.linspace(0.01,1,20)
c_2 = np.linspace(0.01,0.2,20)
score = []
for i in c_1:
lr = LR(solver='liblinear',C=i).fit(X,y)
score.append(lr.score(vali_X,vali_y))
plt.figure()
plt.plot(c_1,score)
plt.show()
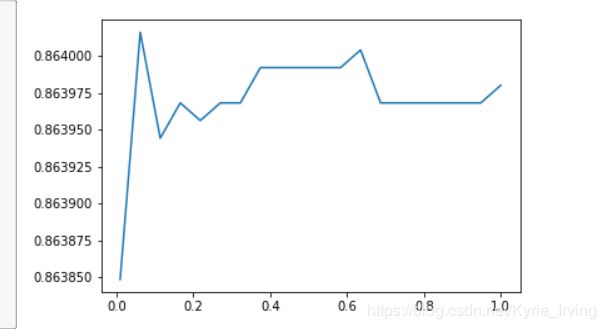
score = []
for i in [1,2,3,4,5,6]:
lr = LR(solver='liblinear',C=0.025,max_iter=i).fit(X,y)
score.append(lr.score(vali_X,vali_y))
plt.figure()
plt.plot([1,2,3,4,5,6],score)
plt.show()

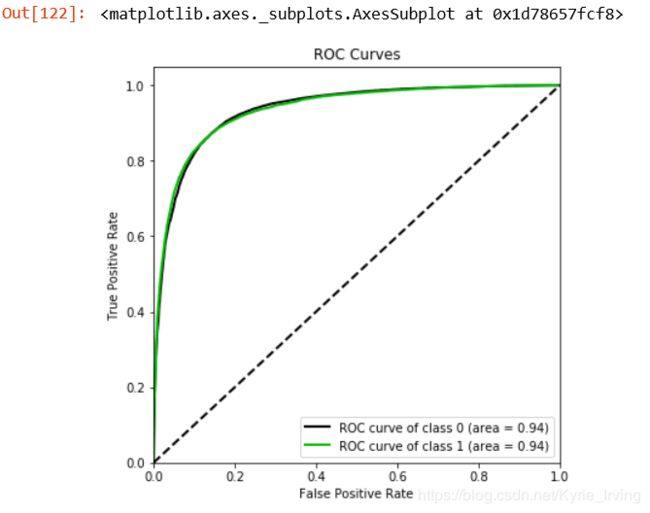
绘制roc
import scikitplot as skplt
#%%cmd
#pip install scikit-plot
vali_proba_df = pd.DataFrame(lr.predict_proba(vali_X))
skplt.metrics.plot_roc(vali_y, vali_proba_df,
plot_micro=False,figsize=(6,6),
plot_macro=False)
B = 20/np.log(2)
A = 600 + B*np.log(1/60)
B,A
(28.85390081777927, 481.8621880878296)
base_score = A - B*lr.intercept_#lr.intercept_:截距
base_score#array([481.56390143])
score_age = woeall["age"] * (-B*lr.coef_[0][1])#lr.coef_:每一个特征建模之后得出的系数
score_age#"age"特征中每个箱对应的分数

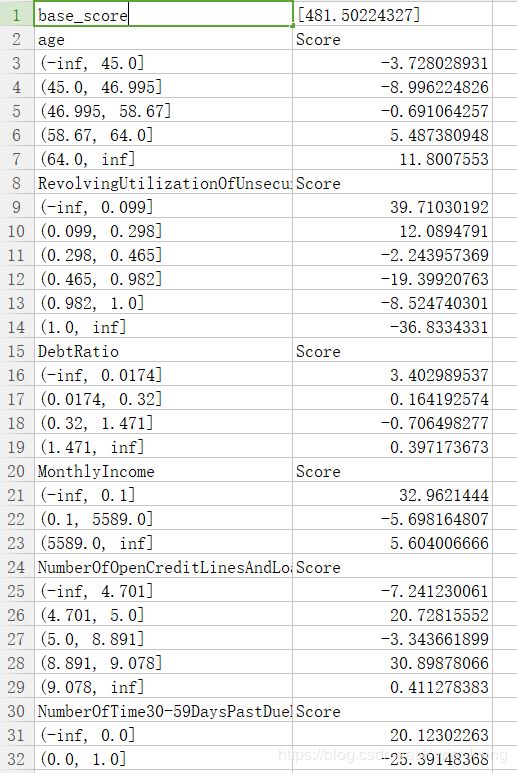
file = "./ScoreData1.csv"
#open是用来打开文件的python命令,第一个参数是文件的路径+文件名,如果你的文件是放在根目录下,则你只需要文件名就好
#第二个参数是打开文件后的用途,"w"表示用于写入,通常使用的是"r",表示打开来阅读
#首先写入基准分数
#之后使用循环,每次生成一组score_age类似的分档和分数,不断写入文件之中
with open(file,"w") as fdata:
fdata.write("base_score,{}\n".format(base_score))
for i,col in enumerate(X.columns):#[*enumerate(X.columns)]
score = woeall[col] * (-B*lr.coef_[0][i])
score.name = "Score"
score.index.name = col
score.to_csv(file,header=True,mode="a")