Kafka为什么速度这么快?
目录
数据写入
顺序写入
Memory Mapped Files
读取数据
传统模式
Zero Copy
批量压缩
总结
数据写入
Kafka消息是保存在磁盘上的。
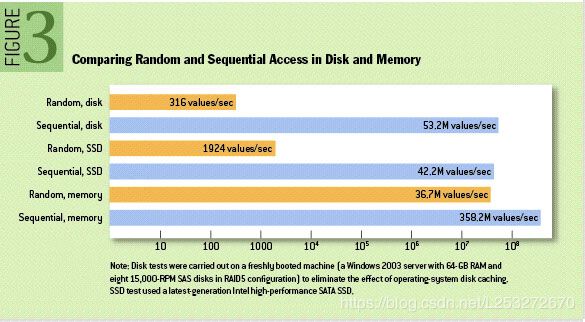
As you can see, it’s not that different. But still, sequential memory access is faster than Sequential Disk Access, why not choose memory? Because Kafka runs on top of JVM, which gives us two disadvantages.
- The memory overhead of objects is very high, often doubling the size of the data stored(or even higher).
- Garbage Collection happens every now and then, so creating objects in memory is very expensive as in-heap data increases because we will need more time to collect unused data(which is garbage).
So writing to file systems may be better than writing to memory. Even better, we can utilize MMAP(memory mapped files) to make it faster.
顺序内存访问比顺序磁盘访问快,但是Kafka在JVM上运行以下两个缺点:
- 对象的内存开销非常高,通常会使存储的数据大小翻倍(甚至更高)
- 垃圾回收时不时发生,因此在内存中创建对象非常昂贵,因为堆内数据增加,因为我们需要更多的时间来收集未使用的数据。
所以Kafka的写入采用了顺序写入和MMAP(memory mapped files) 内存映射文件
顺序写入
磁盘树村读写速度超过内存随机读写
JVM的GC效率低,内存占用大,使用磁盘可以避免这些问题
系统冷启动后,磁盘缓存依然可以使用

每一个Partition对应一个文件,收到消息后kafka会把数据插入到文件末尾
所以Kafka不会删除消费后的数据,会保留所有的数据;每个Consumer对每个Topic都有一个offset表示读取的位置
Kafka提供两种删除策略,一是基于时间,二是基于Partion文件大小
Memory Mapped Files
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并 不是实时的写入硬盘 ,它充分利用了现代操作系统 分页存储 来利用内存提高I/O效率。
Memory Mapped Files(后面简称mmap)也被翻译成 内存映射文件 ,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升, 省去了用户空间到内核空间 复制的开销(调用文件的read会把数据先放到内核空间的内存中,然后再复制到用户空间的内存中。)也有一个很明显的缺陷——不可靠, 写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。 Kafka提供了一个参数——producer.type来控制是不是主动flush,如果Kafka写入到mmap之后就立即flush然后再返回Producer叫 同步 (sync);写入mmap之后立即返回Producer不调用flush叫 异步 (async)。
读取数据
传统模式
当需要对一个文件进行传输的时候,具体流程细节如下:
- 调用read函数,文件数据copy到内核缓冲区
- read函数返回,文件数据从内核缓冲区copy到用户缓冲区
- write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区
- 数据从socket缓冲区copy到相关的协议引擎
以上经过了四次的copy操作
硬盘->内核buf->用户buf->socket相关缓冲区->协议引擎
- To fetch data from the memory, we need to copy those data from the Kernel Context into the Application Context.
- To send those data to the Internet, we need to copy the data from the Application Context into the Kernel Context.
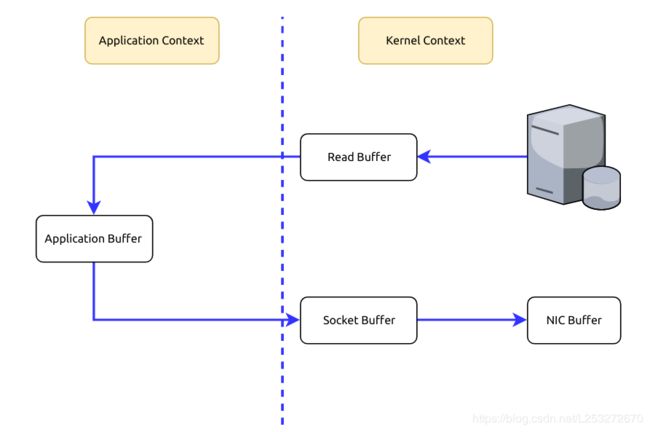
Zero Copy

而sendfile系统调用则提供了一种减少以上多次copy,提升文件传输性能的方法。
在内核版本2.1中,引入了sendfile系统调用,以简化网络上和两个本地文件之间的数据传输。 sendfile的引入不仅减少了数据复制,还减少了上下文切换。
sendfile(socket, file, len);
- sendfile系统调用,文件数据copy到内核缓冲区
- 从内核缓冲区copy到内核中的socket相关缓冲区
- 最好再socket相关缓冲区copy到协议引擎
在apache,nginx,lighttpd等web服务器中,都有sendfile相关的配置,使用sendfile可以大幅度的提升文件的传输性能
Kafka把所有的消息都存放在一个一个文件中,当消费者需要数据的时候kafka直接把文件发送给消费者,配合MMAP作为文件的读写方式,直接把它传给sendfile
批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络IO,对于需要在广域网上的数据中心之间发送消息的数据流水线尤其如此。进行数据压缩会消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑。
- 如果每个消息都压缩,但是压缩率相对很低,所以Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩
- Kafka允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩
- Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议
总结
Kafka速度快在于,把所有的消息变成一个批量的文件,进行合理的批量压缩,减少网络I/O损耗,通过MMAP提高I/O速度,写入数据由于单个Partion是末尾添加所以速度最优,读取数据时配合sendfile直接暴力输出。