【论文笔记】Question Answering with Subgraph Embeddings
一、概要
该文章发于EMNLP 2014,作者提出了一个基于Freebase,根据问题中的主题词在知识库中确定候选答案,构建出一个模型来学习问题和候选答案的representation,然后通过这些representation来计算问题和候选答案的相关度来选出正确答案,在不适用词表、规则、句法和依存树解析等条件下,超越了当时最好的结果。
二、模型方法
2.1 数据简介
假设每给一个问题都含有相应的回答,并且在知识库中存在结构化的答案,本文使用了WebQuestions数据集以及Freebase知识库。除此之外,作者还剔除了Freebase中包含出现频率低于5次实体的三元组,得到一个知识库子集,其中包含了14M个三元组、2.2M个实体和7K关系,然后基于每一个三元组,(例如:subject,type1.type2.predicate, object),通过自动化的方式生成问题答案对:Quesiton:“What is the predicate of the type2subject?” Answer:object。例如:
另外作者根据前人的做法,基于在ClueWeb上提取到的2M个三元组(例如:subject, “text string”, object),通过简单的模板将三元组变换为问题,例如:Where barack obama was allegedly bear in?” (hawaii)。基于这些方法,作者扩建到了一个新的数据集。同时构建的部分数据不是真实数据,为了使得训练的模型更加贴近真实数据,作者在WikiAnswers中提取了2.2M个问题,然后把这些问题350k个类,后面训练模型时也使用这些数据进行训练,因为每一类的问题意思是相近的,所以我们的目的是训练的模型得到想同类的问题之间评分尽可能的高。
2.2 Embedding Questions and Answers
本文的目的是通过模型学习问题中出现的单词和Freebase的实体和关系类型映射到低维的Embedding,使得问题和相应的答案在联合Embedding空间中彼此接近。
假设存在问题q以及候选答案a,假设模型学到了它们的representation后,那么我们可以通过函数 S(q,a)来计算它们的得分,如果它们是匹配的,那么分数则高,反之则低,计算方式如下:
其中q和a都是由单词或者符号组成,假设存在矩阵 W∈Rk×N ,k为embedding的维度大小, N=NW+NS , NW 表示单词的个数, NS 表示实体和关系的个数,通过函数 f(q)=Wϕ(q) 将问题映射到空间 RK ,其中 ϕ(q)∈NN 是一个稀疏向量,表示每个单词在问题q(通常为0或1)中出现的次数,可以发现这本质上就是一个词袋模型(Bag-of-words model)。
同样 g(a)=Wφ(a) 将答案映射到空间 RK , φ(a)∈NN 是答案的稀疏向量表示,但是在构建大难的向量表示时存在三种方法,分别为:
①Single Entity。因为每一个答案都是一个知识库中的实体,那么可以使用one-hot的表达,即 φ(a) 表示该答案实体所在位置为1,其他为0的表达方法,但是很明显这个方法很难把答案的蕴含信息传到输入空间中。
②Path Representation。即通过问题的实体在知识库中找到对应节点,然后考虑一跳或者两跳节点作为答案( 如(barack obama, people.person.place of birth, honolulu) 是1-hop ,(barack obama, people.person.place of birth, location. location.containedby, hawaii)是2-hop),考虑该路径上的实体关系实体以3-hot或者4-hot的形式作为输入向量进行表示。
③Subgraph Representation。这里即对上面的第二种方法记性encode,又对于每一个候选答案对应的属性和关系也加进来,即知识库子图,同样也在1跳或2跳范围,同时为了区别路径和子图的不同,这里对实体和关系进行双倍表示,即: N=NW+2NS ,即输入向量维度为N,假设该子图包含C个实体和D个关系,那么最终的表达是一种3+C+D-hot或者4+C+D-hot的表达。

2.3 Training and Loss Function
在训练模型时,假设讯在训练集D={ (qi,ai) ,…},本文定义margin-based ranking损失函数为:
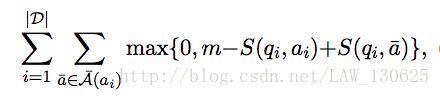
其中头顶带帽的表示负样本,负样本怎么来的呢?本文使用的是构造负样本,一半是与问题实体相连的其它路径,另一半是随机选择的,我们的目标是最小化这个损失函数。
在上面的基础上,作者在之前提到的在WikiAnswers中提取了2.2M个问题进行分类后,进行一个多任务学习(multi-task),这个目标就是让同一个类的问题得分较高,即 s(q1,q2)=f(q1)⊤⋅f(q2) ,这里的训练方式和上面的方法是一样的。
三、实验结果
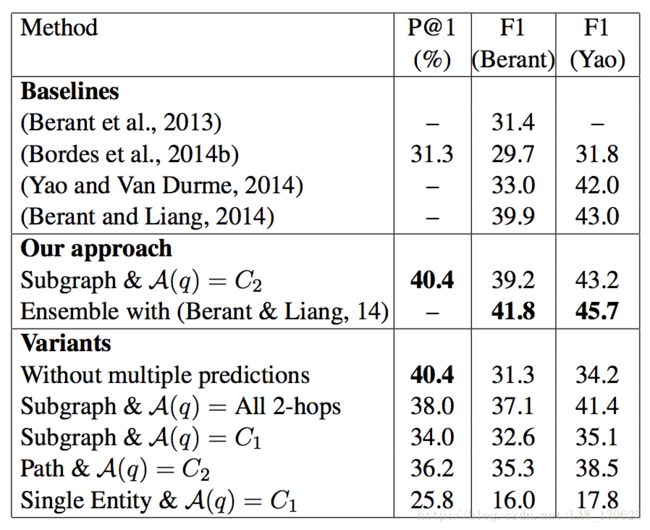
作者通过公式s(q,a)得分选择是个候选答案,然后在根据一跳还是二跳给与不同的权值,一跳为1.5,二跳为1,当然超过二跳的候选答案直接排除,最后再选出得分最高的作为最终的答案。
四、结论与思考
本文提出了embedding模型,利用训练数据中的问题答案对以及知识库进行向量建模,在几乎不需要任何手工定义的特征(hand- crafted features),也不需要借助词汇映射表,词性标注,依存树等条件下取得了当时很好的效果。
五、个人思考
①在本文的向量建模方法,在某种程度上是使用了词袋模型的思想,而词袋模型最大的弊端就是忽略的词汇的顺序性和权重,但是本文利用映射的方法解决了权重的问题,并取得效果。
参考文献
①Antoine Bordes,Sumit Chopra,Jason Weston。Question Answering with Subgraph Embeddings