用双向lstm+CRF做命名实体识别(附tensorflow代码)——NER
转自:https://www.lookfor404.com/%E7%94%A8%E5%8F%8C%E5%90%91lstmcrf%E5%81%9A%E5%91%BD%E5%90%8D%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB%E9%99%84tensorflow%E4%BB%A3%E7%A0%81-ner%E7%B3%BB%E5%88%97%EF%BC%88%E5%9B%9B/
这一篇文章,主要讲一下用深度学习(神经网络)的方法来做命名实体识别。现在最主流最有效的方法基本上就是lstm+CRF了。其中CRF部分,只是把转移矩阵加进来了而已,而其它特征的提取则是交由神经网络来完成。当然了,特征提取这一部分我们也可以使用CNN,或者加入一些attention机制。
接下来,我将参考国外的一篇博客《Sequence Tagging with Tensorflow》,结合tensorflow的代码,讲一下用双向lstm+CRF做命名实体识别。
1.命名实体识别简述
命名实体识别任务本质上就是序列标注任务。来一个例子:
John lives in New York and works for the European Union
B-PER O O B-LOC I-LOC O O O O B-ORG I-ORG在CoNLL2003任务中,实体为LOC,PER,ORG和MISC,分别代表着地名,人名,机构名以及其他实体,其它词语会被标记为O。由于有一些实体(比如New York)由多个词组成,所以我们使用用一种简单的标签体系:
B-来标记实体的开始部分,I-来标记实体的其它部分。
我们最终只是想对句子里面的每一个词,分配一个标签。
2.模型
整个模型的主要组成部分就是RNN。我们将模型的讲解分为以下三个部分:
- 词向量表示
- 词的上下文信息表示
- 解码
2.1 词向量表示
对于每一个单词,我们用词向量来表示,用来捕获词本身的信息。这个词向量由两部分concat起来,一部分是用GloVe训练出来的词向量,另一部分,是字符级别的向量。
在以往,我们会手工提取并表示一些特征,比如用1,0来表示某个单词是否是大写开头,而在这个模型里面,我们不需要人工提取特征,只需要字符级别上面使用双向LSTM,就可以提取到一些拼写层面的特征了。当然了,CNN或者其他的RNN也可以干类似的事情。
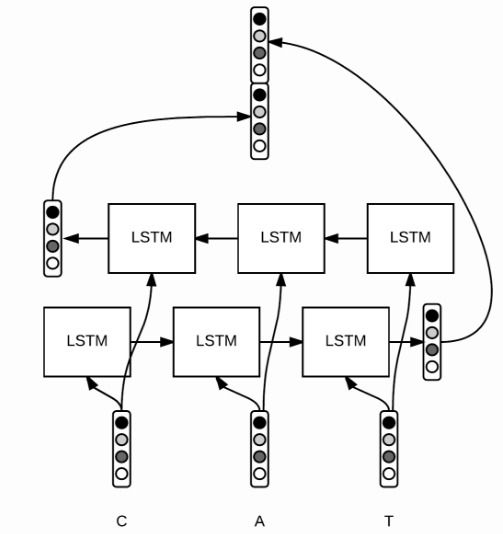
对于每一个单词里面的每一个字母(区分大小写),我们用这个向量来表示,对字母级别的embedding跑一个bi-LSTM,然后将最后的隐状态输出拼接起来(因为是双向,所以有两个最后隐状态,如上图),得到一个固定长度的表达,直觉上,我们可以认为这个向量提取了字母级别的特征,比如大小写、拼写规律等等。然后,我们将这个向量和Glove训练好的w_{glove}拼接起来,得到某个词最终的词向量表达:,其中。
看一下tensorflow对应的实现代码。
| 1 2 3 4 5 |
|
好了,让我们用tensorflow的内置函数来读取word embeddings。假设这个embeddings是一个由GloVe训练出来的numpy数组,那么embeddings[i]表示第i个词的向量表示。
| 1 2 3 |
|
在这里,应该使用tf.Variable并且参数设置trainable=False,而不是用tf.constant,否则可能会面临内存问题。
好,接下来,让我们来对字母建立向量。
| 1 2 3 4 5 |
|
为什么这里用这么多None呢?
其实这取决于我们。在我们的代码实现中,我们的padding是动态的,也就是和batch的最大长度对齐。因此,句子长度和单词长度取决于batch。
好了,继续。在这里,我们没有任何预训练的字母向量,所以我们调用tf.get_variable来初始化它们。我们也要reshape一下四维的tensor,以符合bidirectional_dynamic_rnn的所需要的输入。代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
|
注意
sequence_length这个参数的用法,它让我们可以得到最后一个有效的state,对于无效的time steps,dynamic_rnn直接穿过这个state,返回零向量。
2.2 词的上下文信息表示
当有了词向量之后,就可以对一个句子里的每一个词跑LSTM或者双向LSTM了,然后得到另一个向量表示:,如下图: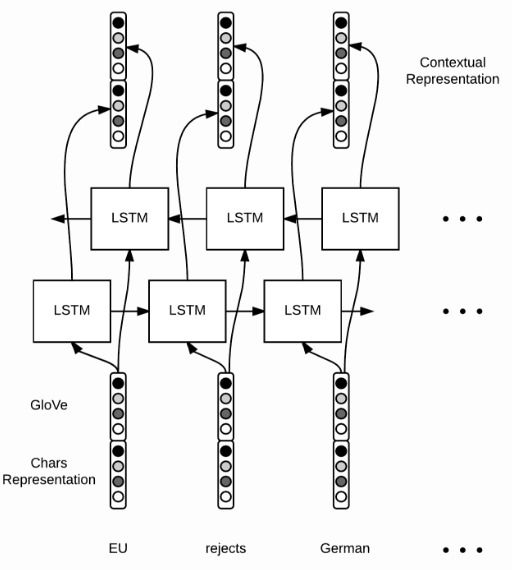
对应的tensorflow代码很直观,这次我们用每一个隐藏层的输出,而不是最后一个单元的输出。因此,我们输入一个句子,有m个单词:,得到m个输出:。现在的输出,是包含上下文信息的:
| 1 2 3 4 5 6 7 8 |
|
2.3 解码
最后,我们要对每一个词分配一个tag。用一个全连接层就可以搞定。
假如,一共有9种tag,那么我们可以得到权重矩阵和偏置矩阵,最后计算某个词的得分向量,可以解释为,某个词标记成第个tag的得分,tensorflow的实现是这样的:
| 1 2 3 4 5 6 7 8 9 10 |
|
在这里,我们用
zero_initializer来初始化偏置。
有了分数之后,我们有两种方案用来计算最后的tag:
- softmax:将得分归一化为概率。
- 线性CRF:第一种方案softmax,只做了局部的考虑,也就是说,当前词的tag,是不受其它的tag的影响的。而事实上,当前词tag是受相邻词tag的影响的。定义一系列词,一系列的得分向量,还有一系列标签,线性CRF的计算公式是这样的:
在上面的式子里,是转移矩阵,尺寸为,用来刻画相邻tag的依赖、转移关系;是结束、开始tag的代价向量。下面是一个计算例子:
了解了CRF得分式子,接下来要做两件事:
- 找到得分最高的tag序列。
- 计算句子的tag概率分布。
“仔细想想,计算量是不是太大了?”
没错,计算量相当大。就上面的例子而言,有9种tag,一个句子有m个单词,一共有种可能,代价太大了。
幸运的是,由于式子有递归的特性,所以我们可以用动态规划的思想来解决这个问题。假设是时间步的解(每个时间步都是有9种可能的),那么,继续往前推,时间步的解,可以由下式表示:
每一个递归步骤的复杂度为,由于我们进行了步,所以总的复杂度是。
最后,我们需要在CRF层应用softmax,将得分概率分布计算出来。我们得计算出所有的可能,如下式子:
上面提到的递归思想在这里也可以应用。先定义,表示从时间步开始、以为tag开始的序列,计算公式如下:
最后,序列概率计算式子如下:
2.4 训练
最后,就是训练部分了。训练的损失函数采用的是cross-entropy(交叉熵),计算公式如下:
其中,为正确的标注序列,它的概率计算公式如下:
- CRF:
- local softmax:
“额..CRF层的损失很难计算吧..?”
没错,但是大神早就帮你做好了。在tensorflow里面,一行就能调用。下面的代码会帮我们计算CRF的loss,同时返回矩阵T,以助我们做预测:
| 1 2 3 4 5 6 7 |
|
local softmax的loss计算过程很经典,但我们需要用tf.sequence_mask将sequence转化为bool向量:
| 1 2 3 4 5 6 7 |
|
最后,定义train op:
| 1 2 |
|
2.5 使用模型
最后的预测步骤很直观:
| 1 |
|
至于CRF层,仍然用到上面提到过的动态规划思想。
| 1 2 3 4 |
|
最终通过这份代码,F1值能跑到90%到91%之间。
3.后记
神经网络做NER,大部分套路都是这样:用基本的RNN、CNN模型做特征提取,最后加上一层CRF,再加点attention机制能稍微提升一下效果,基本上就到瓶颈了。
在2017年6月份,谷歌团队出品这篇论文《Attention Is All You Need》还是给我们带来不少震撼的,不用RNN,CNN,只用attention机制,就刷新了翻译任务的最好效果。所以,我们是不是可以想,把这种结构用到命名实体识别里面呢?
果然,已经有人开始做相关研究。《Deep Semantic Role Labeling with Self-Attention》这篇论文发表于2017年12月,实现了一个类似刚才说到的谷歌的模型,做的是SRL任务,也取得了不错的效果,同时他们也有放出实现代码:https://github.com/XMUNLP/Tagger
值得学习一下。
另外,用多模态来做实体识别也是一个方向,特别是对于一些类似微博的语料(有图片),这样做效果更佳。
代码和语料:
https://www.lookfor404.com/命名实体识别的语料和代码/