Eclipse本地开发环境搭建与本地运行wordcount实例
1.window下载Hadoop源码
下载的版本和你linux安装时的版本一样即可,我的是hadoop-2.7.2
下载地址:http://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
解压文件:
2、安装hadoop-eclipse-plugin-2.7.2.jar(具体版本视你的hadoop版本而定)
下载地址:http://download.csdn.net/detail/tondayong1981/9432425
把hadoop-eclipse-plugin-2.7.2.jar(具体版本视你的hadoop版本而定)放到eclipse安装目录的plugins文件夹中,如果重新打开eclipse后看到有如下视图,则说明你的hadoop插件已经安装成功了:
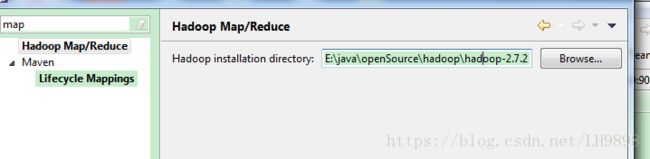
然后配置eclipse的hadoop路径,就是指向你解压后的hadoop文件,如图所示
3、Maven引入jar包
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>axc-hadoopgroupId>
<artifactId>axcartifactId>
<packaging>warpackaging>
<version>0.0.1-SNAPSHOTversion>
<name>axc Maven Webappname>
<url>http://maven.apache.orgurl>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-1.2-apiartifactId>
<version>2.7version>
dependency>
<dependency>
<groupId>commons-logginggroupId>
<artifactId>commons-loggingartifactId>
<version>1.2version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>3.8.1version>
<scope>testscope>
dependency>
<dependency>
<groupId>jdk.toolsgroupId>
<artifactId>jdk.toolsartifactId>
<version>1.7version>
<scope>systemscope>
<systemPath>${JAVA_HOME}/lib/tools.jarsystemPath>
dependency>
dependencies>
<build>
<finalName>axcfinalName>
build>
project>
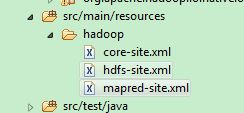
4.拷贝hadoop配置文件到项目路径下
将hadoop安装在linux上的etc/hadoop下的三个核心配置文件放入到工程中,分别是:core-site.xml、hdfs-site.xml、mapred-site.xml
我本地的配置如下:
(1)core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/home/liaohui/tools/hadoop/hadoop-2.7.2/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://liaomaster:9000value>
property>
configuration>
(2)hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/liaohui/tools/hadoop/hadoop-2.7.2/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/liaohui/tools/hadoop/hadoop-2.7.2/tmp/dfs/datavalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>
3.mapred-site.xml
<configuration>
<property>
<name>mapred.job.trackername>
<value>liaomaster:9001value>
property>
configuration>
我的本地项目路径是:
4.编写WordCount程序
package com.liaohui;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class WordCountMapper extends MapReduceBase implements Mapper {
private final static IntWritable one =new IntWritable(1);
private Text word =new Text();
public void map(Object key,Text value,OutputCollector output, Reporter reporter) throws IOException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word,one);//字符解析成key-value,然后再发给reducer
}
}
}
public static class WordCountReducer extends MapReduceBase implements Reducer {
private IntWritable result =new IntWritable();
public void reduce(Text key, Iteratorvalues, OutputCollector output, Reporter reporter)throws IOException {
int sum = 0;
while (values.hasNext()){//key相同的map会被发送到同一个reducer,所以通过循环来累加
sum +=values.next().get();
}
result.set(sum);
output.collect(key, result);//结果写到hdfs
}
}
public static void main(String[] args)throws Exception {
System.setProperty("hadoop.home.dir", "E:\\java\\openSource\\hadoop\\hadoop-2.7.2");
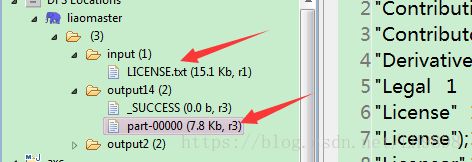
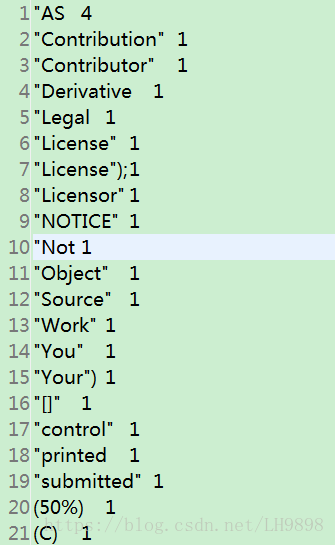
String input = "hdfs://liaomaster:9000/input/LICENSE.txt";//要确保linux上这个文件存在
String output = "hdfs://liaomaster:9000/output14/";
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("WordCount");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.setOutputKeyClass(Text.class);//设置输出key格式
conf.setOutputValueClass(IntWritable.class);//设置输出value格式
conf.setMapperClass(WordCountMapper.class);//设置map算子
conf.setCombinerClass(WordCountReducer.class);//设置combiner算子
conf.setReducerClass(WordCountReducer.class);//设置reducer算子
conf.setInputFormat(TextInputFormat.class);//设置输入格式
conf.setOutputFormat(TextOutputFormat.class);//设置输出格式
FileInputFormat.setInputPaths(conf,new Path(input));//设置输入路径
FileOutputFormat.setOutputPath(conf,new Path(output));//设置输出路径
JobClient.runJob(conf);
System.exit(0);
}
}
5.运行这个程序时可能会报一些错误需要做一些处理
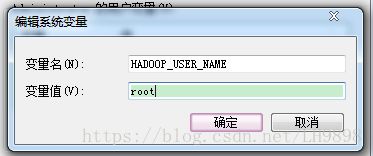
(1)配置两个本地电脑系统环境变量
%HADOOP_HOME%\bin
E:\java\openSource\hadoop\hadoop-2.7.7

HADOOP_USER_NAME
root
(2)问题Exception in thread “main”java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
分析:C:\Windows\System32下缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面即可。
解决:hadoop-common-2.2.0-bin-master下的bin的hadoop.dll放到C:\Windows\System32下,然后重启电脑,也许还没那么简单,还是出现这样的问题。
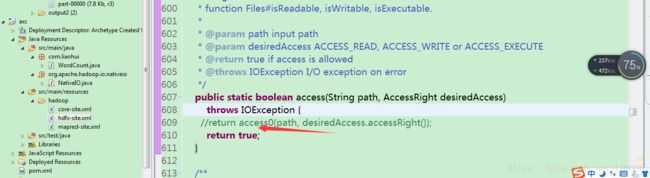
我们在继续分析:我们在出现错误的的atorg.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:557)
Windows的唯一方法用于检查当前进程的请求,在给定的路径的访问权限,所以我们先给以能进行访问,我们自己先修改源代码,return true 时允许访问。我们下载对应hadoop源代码,hadoop-2.6.0-src.tar.gz解压,hadoop-2.6.0-src\hadoop- common-project\hadoop-common\src\main\java\org\apache\hadoop\io\nativeio 下NativeIO.java 复制到对应的Eclipse的project,然后修改557行为return true如图所示:
(3)问题四:org.apache.hadoop.security.AccessControlException: Permissiondenied: user=zhengcy, access=WRITE,inode=”/user/root/output”:root:supergroup:drwxr-xr-x
分析:我们没权限访问output目录。
解决:我们 在设置hdfs配置的目录是在hdfs-site.xml配置hdfs文件存放的地方,我们在这个etc/hadoop下的hdfs-site.xml添加
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>6.运行程序和输出结果
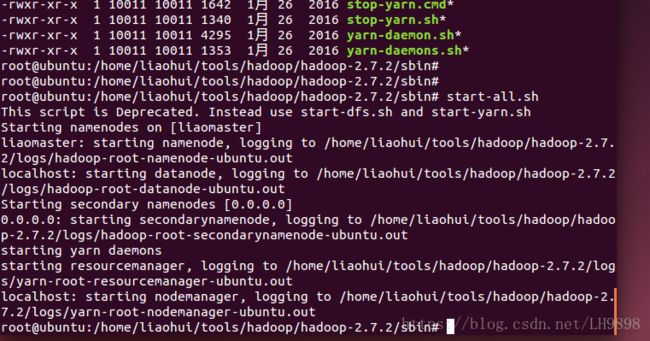
(1)运行程序前eclipse配置hadoop环境
先启动Linux下Hadoop程序,如图所示
配置eclipse仓库路径,鼠标右击新建一个Hadoop路径

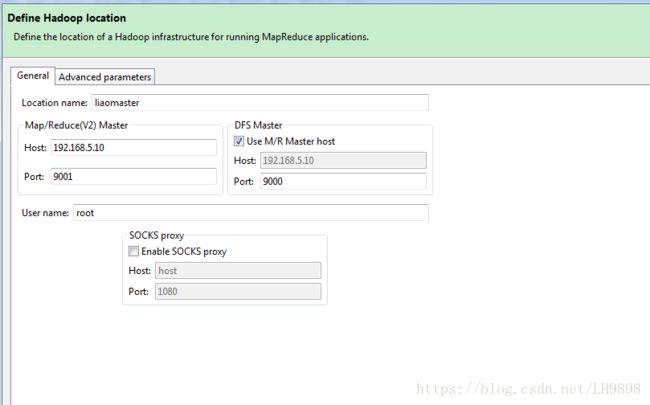
(2)成功输出统计结果