Trie树词频统计实例
Trie树简介
Trie树,也叫前缀字典树,是一种较常用的数据结构。常用于词频统计,
字符串的快速查找,最长前缀匹配等问题以及相关变种问题。
数据结构表现形式如下图所示:
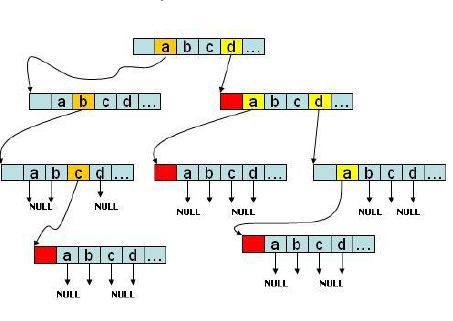
Trie树的根为空节点,不存放数据。每个节点包含了一个指针数组,数组大小通常为26,即保存26个英文字母(如果要区分大小则数组大小为52,如果要包括数字,则要加上0-9,数组大小为62)。
可以想象它是一棵分支很庞大的树,会占用不少内存空间;不过它的树高不会唱过最长的字符串长度,所以查找十分快捷。典型的用空间换取时间。
全英圣经词频统计
全英圣经TXT文件大小有4m,若要对它进行词频统计等相关操作,可以有许多方法解决。
我觉得可以用如下方式:
- pthon字典数据结构解决
- 在linux下利用sed & awk 文本处理程序解决
- C++ STL map解决
- Trie树解决
前三种实现比较简单快捷,不过通过自己封装Trie树可以练习一下数据结构!感受一下数据结构带来的效率提升,何乐而不为。
下面则是我的具体实现,如有纰漏,敬请指正!
1)自定义头文件
WordHash用来记录不重复的单词及其出现次数
TrieTree类封装得不太好,偷懒把很多属性如行数,单词总数等都放在public域
#ifndef _WORD_COUNT_H
#define _WORD_COUNT_H
#include具体类成员函数cpp文件
1)字典树构造函数
#include2)读取文本中的单词,逐个插入到字典树中,创建字典树。
(仅实现了能够处理全为小写字母的文本,本人先将圣经文件做了一些简单处理)
//建立字典树,将单词插入字典树
void TrieTree::insert(const char *word) {
TrieNode *location = root; //遍历字典树的指针
const char *pword = word;
//插入单词
while( *word ) {
if ( location->next_char[ *word - 'a' ] == NULL ) {
TrieNode *temp = new TrieNode();
location->next_char[ *word - 'a' ] = temp;
}
location = location->next_char[ *word - 'a' ];
word++;
}
location->count++;
location->is_word = true; //到达单词末尾
if ( location->count ==1 ) {
strcpy(this->words_count_table[word_index++].word,pword);
distinct_words_count++;
}
}3)按单词查找字典树,获取其出现次数
//查找字典树中的某个单词
bool TrieTree::search(const char *word) {
TrieNode *location = root;
//将要查找的单词没到末尾字母,且字典树遍历指针非空
while ( *word && location ) {
location = location->next_char[ *word - 'a' ];
word++;
}
this->words_count_table[word_index++].show_times = location->count;
//在字典树中找到单词,并将其词频记录到词频统计表中
return (location != NULL && location->is_word);
}4)删除字典树
//删除字典树,递归法删除每个节点
void TrieTree::deleteTrieTree(TrieNode *root) {
int i;
for( i=0;iif ( root->next_char[i] != NULL ) {
deleteTrieTree(root->next_char[i]);
}
}
delete root;
} 5)WordStatics类相关成员函数定义
void WordStatics::set_open_filename(string input_path) {
this->open_filename = input_path;
}
string& WordStatics::get_open_filename() {
return this->open_filename;
}
void WordStatics::open_file(string filename) {
set_open_filename(filename);
cout<<"文件词频统计中...请稍后"<const char *pstr;
while (!fout.eof() ) { //将文件单词读取到vector中
string line,word;
getline(fout,line);
dictionary_tree.lines_count++;
istringstream is(line);
while ( is >> word ) {
pstr = word.c_str();
dictionary_tree.all_words_count++;
words.push_back(word);
}
}
//建立字典树
vector<string>::iterator it;
for ( it=words.begin();it != words.end();it++ ) {
if ( isalpha(it[0][0]) ) {
dictionary_tree.insert( (*it).c_str() );
}
}
} void WordStatics::getResult() {
cout<<"文本总行数:"<.lines_count<;
cout<<"所有单词的总数 : "<.all_words_count-1<;
cout<<"不重复单词的总数 : "<.distinct_words_count<;
//在树中查询不重复单词的出现次数
dictionary_tree.setZero_wordindex();
for(int i=0;i
dictionary_tree.search(dictionary_tree.words_count_table[i].word);
result_table.push_back(dictionary_tree.words_count_table[i]);
}
} 6)对统计结果进行排序,依照用户输入输出前N词频的单词
bool compare(const WordHash& lhs,const WordHash& rhs) {
return lhs.show_times > rhs.show_times ;
}
void WordStatics::getTopX(int x) {
sort(result_table.begin(),result_table.end(),compare);
cout<<"文本中出现频率最高的前5个单词:"<for( int i = 0; icout<": "< 运行结果:
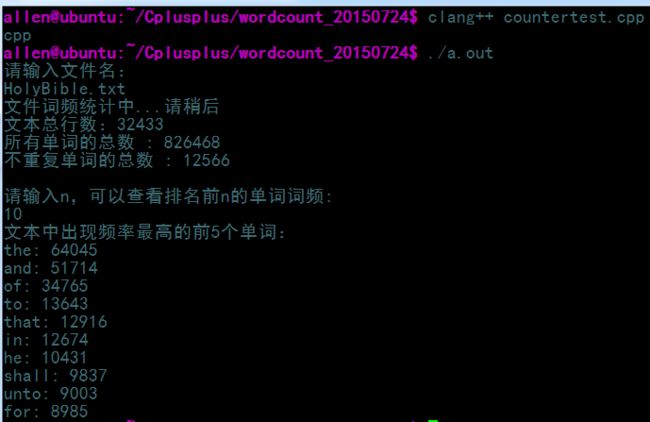
仅供参考,记录自己的学习历程。
还有许多地方不太合理,需要改进,慢慢提升自己的编程能力!