大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2)
大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2)
上一节中我们讲解了随机森林的基本概念,本节的话我们讲解随机森林的随机方式,以及一些代码。
目录
1-随机森林随机方式
2-out of baf data
3-代码
1-随机森林随机方式
我们先来回顾下随机森林中都有哪些随机?
第一:用Bagging生成用来训练小树的样本时,进行有放回的随机抽样。
第二:抽样数据之后,对feature也进行随机的抽样。
第三:这个东西虽然没有实现,在树模型中,如果随机的将feature进行一些线性组合,作为新的feature,是对它有帮助的。
假如数据集如下
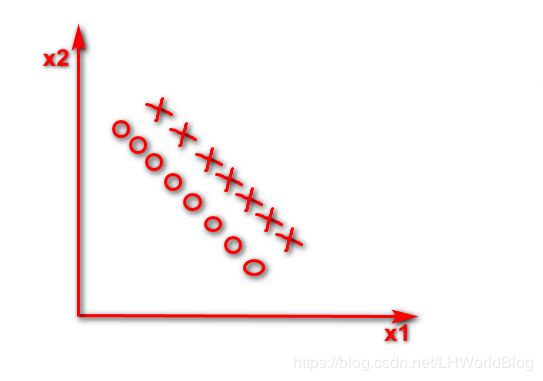
这个情况下它是一个线性的可分的问题,逻辑回归很简单,画这么一条线,它肯定能找到这组w把这两个东西完美的分开。对于决策树它当然能分开,它非线性能够处理好,线性自然也能处理。但是在只有x1和x2的时候,那么此时你要是这棵决策树的话,你只能按照x1或者x2维度切一刀,你的分列条件要挑一个X1要么挑一个X2,小于多少或者大于多少,反映在图形上,第一刀判断所有x2小于横虚线是X这个数,

第二刀判断小于竖虚线是O这个数,
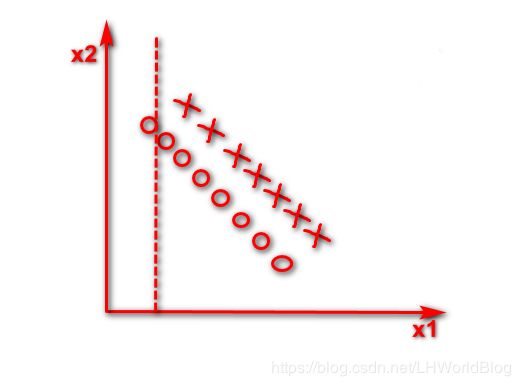
剩下一堆还乱着,同样的方法,会得到这么一个边界。

这个树有多深?每一条虚线就代表它一次分裂,非常深,明明是一个线性可分的问题,但是因为它只能针对x1或x2独立的去做切割的情况下,会导致树分的很深,效率低下。
但是如果我们得到了一个x1+x2,构造了一个新的维度,也就是说这棵树在判断的时候,能拿x1+x2等于多少去做分配条件的话,就可以直接画出一条斜线了。 假如x1+x2<5是下面条直线
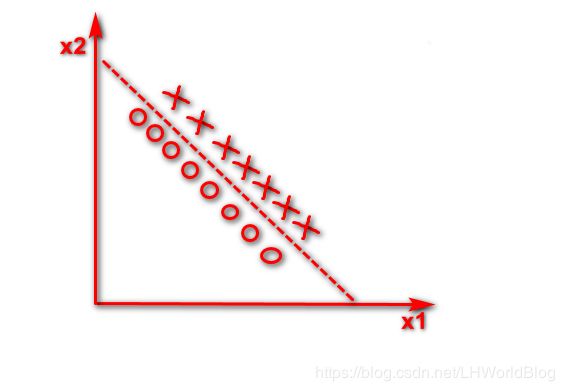
仅仅通过一次分裂,就可以把这种在空间中坐标轴不垂直的这种线性可分的问题解决掉了。
对于刚才这种问题,只要通过对原有的维度进行一系列线性组合,就赋予了决策树画斜线能力,能让它用更少的分裂次数,就能够把原来纯度怎么分都分不太高的那些数据集,一步就给分好了。但是这个东西在随机森林里面并没有实现,这只是一个思路,它的问题就是当维度足够多的时候,你用谁去做线性组合,这个东西不好确定,又维度爆炸了,所以它只是一个思路。
2-out of baf data
随机森林会衍生出另外一个福利,就是out of baf data,随机森林在构造若干弱分类器的时候会进行又放回的均匀抽样,因为是有放回的,所以在进行抽样的时候, 有很多条数据并没有被选到。那能不能利用这些没有抽到的数据,反正训练的时候也没用到这些数据,利用它们去做test set,然后用来调参?直观上应该是可以的,但是有一个问题是,因为我们调的是整个随机森林的参数,随机森林里面每棵小树你没用到的数据,有可能另一个用到了,它能用到的有可能另一个也用到。所以不可以直接找到谁都没用到的数据,用来做测试,需要给它做一个小的变化。
原来是每一个弱分类器有若干没用到的数据点,我们换一个角度考虑,以一个数据点去观察。比如(x1,y1)它被1,3,T号弱分类器用到了,而2号没有用到它,那么单独评估2号的时候可以用它来看(x1,y1)表现的怎么样,x1,y1就相当于2号弱分类器的测试集。这是1个弱分类器没有用到(x1,y1)数据集的,假如(x1,y1)在2号弱分类器和4号弱分类器上没有用到,可不可以把第一条数据交给2号和4号分别预测出来一个结果?这会2号和4号给出的结果是有验证意义的,因为2号4号在训练的时候没用到它。
那么假如树足够多,我们管所有没有用到第一条数据的叫![]() ,代表所有的没有用到第一条数据的弱分类器的投票结果。原来是一片大森林,有好多棵树,现在从里边挑上几棵没有碰到第一条数据进行训练的这些树,让它们组成一个小森林,能够评测一下小森林预测的是正确,还是错误。那么对于2号数据点来说,也有一个小森林完全没有用到过,也可以用它扔到没有用到它的
,代表所有的没有用到第一条数据的弱分类器的投票结果。原来是一片大森林,有好多棵树,现在从里边挑上几棵没有碰到第一条数据进行训练的这些树,让它们组成一个小森林,能够评测一下小森林预测的是正确,还是错误。那么对于2号数据点来说,也有一个小森林完全没有用到过,也可以用它扔到没有用到它的![]() 小森林里边,得到一个预测结果。总共有N条数据,就会整出N个小森林,每一个是预测对了还是预测错了,可以统计出来一个ACC正确率。
小森林里边,得到一个预测结果。总共有N条数据,就会整出N个小森林,每一个是预测对了还是预测错了,可以统计出来一个ACC正确率。
这种验证数据集的方式称为out of bag data。在袋子之外,什么意思呢?Bagging更像一个装袋的意思,原来有这么一个训练集,准备了一百个袋子,你每个袋子都从训练集里边有放回的随机抽样,给它装成一个小袋子,在每一个袋子上面生成出一棵树。但是对于每一个bag都有一些数据没有装到这个里面,我们就叫它out of bag,在袋外的这些数据。它的问题主要是 不是每一个弱分类器,它的out of bag data都是一样的,甚至可以说每一个弱分类器out of bag(简称oob)数据都不一样。于是就切换到了以数据为维度,哪些弱分类器没有用到,就去验证一下这些弱分类器是否正确。
通过上面oob数据统计出来的ACC正确率越高越好,它也是随机森林中帮助我们调参的参数,叫oob_score,当训练好了一个随机森林之后,它的对象里面就带了一个属性叫oob_score。每次调参数输出一下oob_score,看一下是高了还是低了,如果变高了说明调的方向正确,如果变低了说明调的方向不对。
3-代码
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
if __name__ == '__main__':
iris = load_iris()
X = iris.data[:, :2] # 花萼长度和宽度
y = iris.target
# X, y = make_moons()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1)
rnd_clf.fit(X_train, y_train)
bag_clf = BaggingClassifier(
DecisionTreeClassifier(splitter="random", max_leaf_nodes=16),
n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1
)
bag_clf.fit(X_train, y_train)
gbdt_clf = GradientBoostingClassifier(n_estimators=500)
gbdt_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
y_pred_bag = bag_clf.predict(X_test)
y_pred_gbdt = gbdt_clf.predict(X_test)
print(accuracy_score(y_test, y_pred_rf))
print(accuracy_score(y_test, y_pred_bag))
print(accuracy_score(y_test,y_pred_gbdt))
# Feature Importance
iris = load_iris()
rnd_clf = RandomForestClassifier(n_estimators=500, n_jobs=-1)
rnd_clf.fit(iris["data"], iris['target'])
for name, score in zip(iris['feature_names'], rnd_clf.feature_importances_):
print(name, score)
iris = load_iris()
解释下上面代码:因为随机森林最原始的定义是若干个DecisionTree通过Bagging的形式组合在一起,所以我们可以通过两种API的形式产生一个随机森林的对象,分别是RandomForestClassifier,和BaggingClassifier(DecisionTreeClassifier)。我们来看下RandomForestClassifier都有哪些参数:

n_estimators,估计器,意思是需要多少个弱分类器。bootstrap是否又放回的抽象,n_jobs因为咱们的决策树可以支持并行操作,所以这里代表多少个线程去跑,-1代表使用所有的线程。
我们总结下随机森林的优点: 1. 表现良好 2. 可以处理高维度数据(维度随机选择)3. 辅助进行特征选择4. 得益于bagging, 可以进行并行训练 缺点:对于噪声过大的数据容易过拟合。