MySQL换成ES+filebeat的简要说明。ES的简要使用入门
背景
最近手头有个项目ESB改造,原先的ESB在系统信息统计时,例如交易异常统计,交易流水统计,交易用时统计等等统计计算时,压测时会有瓶颈,我的老师希望将该部分查询功能由MySQL改造为ES。因为也是第一次接触ES(以前只是用过日志收集系统ELK,但是环境搭起来就可以用,所以没有细究。),现将一小段时间的摸索过程记录,希望能帮到刚接触ES和有类似需求的朋友。
改造要求
原ESB将每次进件消息进行拆解和计算,将所需要统计的字段进行字段拆解存放到mysql中,配合很多视图来实现查询统计功能。
现在改造,就是要将这一块功能给换成ES的查询和filebeat的收集。
可行性分析
本来担心ES底层是lucene搜索引擎,因此其本质也是搜索引擎,或者说是NoSql。类似redis 可能读取速度快,但是没有mysql统计功能全面。经官网学习,发现ES支持聚合查询,但是没有找到加减乘除运算,也没有关联查询。最后将官网大部分英文文档翻了一遍发现:有加减乘除运算,也可以关联查询。但是关联查询(ES的版本是6.2.4。需要存储的时候就要将关联的父记录存储进去,而不能做关联查询。所以我并不想把这个功能叫做类似mysql的join查询。)
至此总结一下可行性:
1 记录增删改查没问题
2 关联查询,按照官网所说,使用关联查询,效率降低几百倍。不过可以通过filebeat收集时,全量收集避 免join查询
3 统计可以使用聚合查询和script脚本计算。
总的来说可以满足需求,聚合查询有三种实现方式,因为项目紧张,并没有仔细研究,所以到底join可不可以实现,并未详细论证,从很多人的blog来看,是的确无法做到mysql 的join on的效果。
补充说明:(本文讲解从零基础开始,为自己的学习过程体会,肤浅之处,望高手勿喷。)
ES搭建起来支持restful访问,网上有客户端 elasticsearch-head 但是可以当作navicat使用。但是发送restful请求时, 我比较喜欢postman的简洁。
ES+filebeat的使用
实战开始
1 首先是配置索引的mapping
这个mapping相当于mysql的数据类(每一个字段的类型,如 int,char ,vchar等等类型相似。)型定义。目的是将log日志中的字段进行拆分后,可以将制定字段存储为int,long等数字类型,否则默认就是String类型(ES中叫做keyword类型),将需要计算的字段名称设置为int 或者long,否则后边计算是会报错类型转换异常。下图为postman截图

(粘图片可以强制自己敲json代码)
1.1特殊情况,如果mapping已经存在,就要用重命名的方式,将其替换。附件下载中有txt文件说明(https://download.csdn.net/download/liuhua121/11540325)
2 设置filebeat的解析表达式
filebeat需要配置解析表达式,目的是为了将日志打印的字段进行拆分。
同时还需要设置日志是否支持换行,换行的标志是什么等。
在这里配置了一个pipeline 里面存放了解析表达式,这样filebeat.yml文件配置如下。

上图是filebeat的部署配置文件。
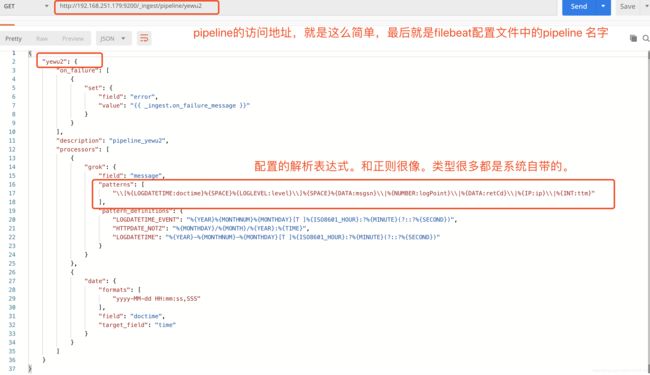
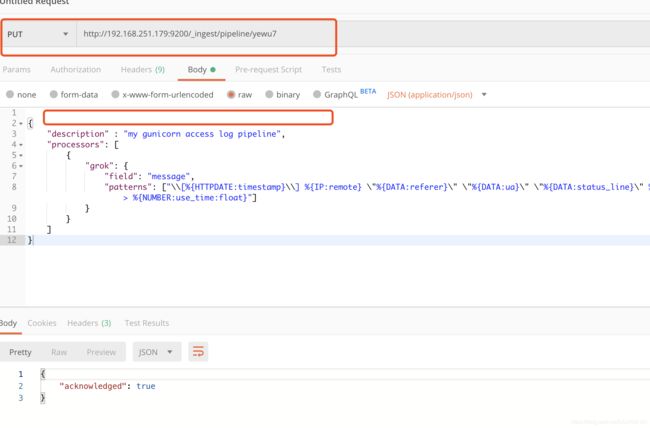
上图是我配置好pipeline后查出来的。存放的json代码如下
 3 JavaApi的统计写法如下。
3 JavaApi的统计写法如下。
这个也是很费劲的,ES版本更新速度极快,每个版本对应的JavaApi可能会有不同,而且聚合查询是比较复杂的。
package spc.esb.console.elasticsearch;
import com.alibaba.fastjson.JSONObject;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.script.Script;
import org.elasticsearch.search.Scroll;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.aggregations.Aggregation;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.ParsedStringTerms;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.sum.ParsedSum;
import org.elasticsearch.search.aggregations.metrics.sum.SumAggregationBuilder;
import org.elasticsearch.search.aggregations.pipeline.ParsedSimpleValue;
import org.elasticsearch.search.aggregations.pipeline.PipelineAggregatorBuilders;
import org.elasticsearch.search.aggregations.pipeline.bucketscript.BucketScriptPipelineAggregationBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class ESSearch
{
// @Autowired
private RestHighLevelClient restClient;
//private final Logger log = LoggerFactory.getLogger(ESSearch.class);
private static final RequestOptions COMMON_OPTIONS;
static
{
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
}
public List search(Map matchQueryMaps) throws Exception
{
List resList = null;
final Scroll scroll = new Scroll(TimeValue.timeValueMinutes(1L));
SearchRequest searchRequest = new SearchRequest("liuhua");
searchRequest.scroll(scroll);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.profile(true);
/* 1用来统计流水号的聚合器 */
TermsAggregationBuilder serviceIdAgg = AggregationBuilders.terms("service")
.field("serviceId");
SumAggregationBuilder successNmAgg = AggregationBuilders.sum("successNum")
.field("successnm");
SumAggregationBuilder errorNumAgg = AggregationBuilders.sum("errrorNum").field("errornum");
SumAggregationBuilder timeoutNumAgg = AggregationBuilders.sum("timeoutNum")
.field("timeoutnum");
// 用来计算每个bucket的和
Map bucketsPaths = new HashMap<>();
bucketsPaths.put("sucnm", "successNum");
bucketsPaths.put("errnm", "errrorNum");
bucketsPaths.put("tionm", "timeoutNum");
Script successScript = new Script("params.sucnm/(params.sucnm+params.errnm+params.tionm)");
Script errorScript = new Script("params.errnm/(params.sucnm+params.errnm+params.tionm)");
Script tionmScript = new Script("params.tionm/(params.sucnm+params.errnm+params.tionm)");
BucketScriptPipelineAggregationBuilder sucessBucketScript = PipelineAggregatorBuilders
.bucketScript("successrate", bucketsPaths, successScript);
BucketScriptPipelineAggregationBuilder errorBucketScript = PipelineAggregatorBuilders
.bucketScript("errorrate", bucketsPaths, errorScript);
BucketScriptPipelineAggregationBuilder timeoutBucketScript = PipelineAggregatorBuilders
.bucketScript("timeoutrate", bucketsPaths, tionmScript);
serviceIdAgg.subAggregation(successNmAgg).subAggregation(errorNumAgg)
.subAggregation(timeoutNumAgg).subAggregation(sucessBucketScript)
.subAggregation(errorBucketScript).subAggregation(timeoutBucketScript);
searchSourceBuilder.aggregation(serviceIdAgg);
searchRequest.source(searchSourceBuilder);
System.out.println("日志搜索查询请求:{}"+searchRequest);
SearchResponse searchResponse = restClient.search(searchRequest, COMMON_OPTIONS);
System.out.println("日志搜索查询结果,条数:{}"+searchResponse.getHits().totalHits);
if (searchResponse.getHits().totalHits == 0)
{
return null;
}
else
{
if ("OK".equals(searchResponse.status().toString()))
{
/* 第一中尝试获取groupby的方式 */
Aggregations terms = searchResponse.getAggregations();
for (Aggregation a : terms)
{
ParsedStringTerms teamSum = (ParsedStringTerms) a;
for (Terms.Bucket bucket : teamSum.getBuckets())
{
Map subaggmap = bucket.getAggregations().asMap();
double sNum = ((ParsedSum) subaggmap.get("successNum")).getValue();
double fNum = ((ParsedSum) subaggmap.get("errrorNum")).getValue();
double tNum = ((ParsedSum) subaggmap.get("timeoutNum")).getValue();
double successrate = ((ParsedSimpleValue) subaggmap.get("successrate"))
.value();
double errorrate = ((ParsedSimpleValue) subaggmap.get("errorrate")).value();
double timeoutrate = ((ParsedSimpleValue) subaggmap.get("timeoutrate"))
.value();
System.out.println(bucket.getKeyAsString() + " " + bucket.getDocCount() + " "
+ " 成功数 : " + sNum + " " + " 失败数 : " + fNum
+ " 超时数 : " + tNum + " 成功率 : " + successrate
+ " 错误率 : " + errorrate + " 超时率 : " + timeoutrate);
}
}
resList = new ArrayList<>();
SearchHit[] searchHits = searchResponse.getHits().getHits();
for (SearchHit hit : searchHits)
{
String res = hit.getSourceAsString();
if (hit.getHighlightFields() != null && hit.getHighlightFields().size() > 0)
{
JSONObject resJson = JSONObject.parseObject(res);
HighlightField highlightField = hit.getHighlightFields().get("message");
String highlighMessage = highlightField.getFragments()[0].string();
String repMessage = highlighMessage.replace("\\tat",
" ");
resJson.put("message", repMessage);
resList.add(resJson.toJSONString());
}
else
{
String repMessage = res.replace("\\tat", " ");
resList.add(repMessage);
}
}
}
else
{
System.out.println("查询失败!");
}
}
return resList;
}
// public static void main(String[] args)
// {
// try
// {
// ESConfig esConfig = new ESConfig();
// RestHighLevelClient client = esConfig.highLevelClient();
// ESSearch esSearch = new ESSearch();
// esSearch.restClient = client;
// Map matchQueryMaps = null;
// esSearch.search(matchQueryMaps);
// Thread.sleep(10000);
// }
// catch (Exception e)
// {
// System.out.println(e.getMessage());
// }
//
// }
}
以上代码实现的SQL是
SELECT
sum( successNum ),
sum( errrorNum ),
sum( timeoutNum ),
sum( successNum ) / ( sum( successNum ) + sum( errrorNum ) + sum( timeoutNum ) ) AS 正确率,
sum( errrorNum ) / ( sum( successNum ) + sum( errrorNum ) + sum( timeoutNum ) ) AS 错误率,
sum( timeoutNum ) / ( sum( successNum ) + sum( errrorNum ) + sum( timeoutNum ) ) AS 超时率
FROM
索引中的 type
GROUP BY
serviceId说明:
TermsAggregationBuilder serviceIdAgg = AggregationBuilders.terms("service").field("serviceId");JavaAPI中这个builder就是group by 的对应API,因为sql中group by是将所有的其他查询字段包在里面的,所以,可以看到Java代码中的其他的所有聚合函数都是被这个builder作为子查询的。
总结
到此为止,实战已经差不多了,剩下的就是业务代码的实现。
代码敲一遍,json敲一遍,感觉就会学到很多东西。官网整整看了一周,感谢我的老师也是领导的指导与宽容 ,让我啥也不干,看官网英文文档看了一周。得到的经验就是,静下心来打开有道边翻译边看官网,比看很多网上的其他资料有用千百倍。
最后再贴一点pipeline的配置的Java代码
算了,不贴了。