ALS算法(推荐系统)
测试数据
用户ID,物品ID,评分
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0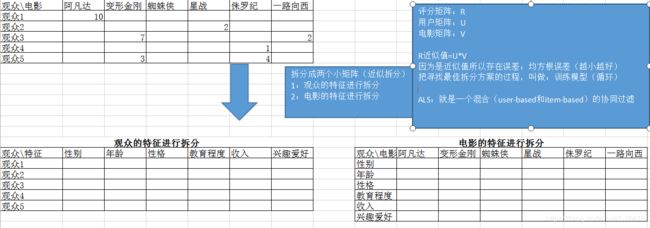
代码实现:
package ml
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.io.Source
/**
* 交替最小二乘
*/
object ALSDemo {
/**
* 加载评分数据
* @param str
*/
def loadRatingData(str: String) :Seq[Rating] = {
val lines = Source.fromFile(str).getLines()
val ratings = lines.map{
line =>
val fields =line.split(",")
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)
}.filter{x => x.rating >0.0 }
if (ratings.isEmpty){
sys.error("NO ratings provided")
}else{
ratings.toSeq
}
}
/**
* 计算RMSE
* @param model
* @param data
* @param n
*/
def computeRMSE(model: MatrixFactorizationModel, data: RDD[Rating], n: Long): Double = {
val predictions: RDD[Rating] = model.predict((data.map(x => (x.user, x.product))))
val predictionsAndRating = predictions.map {
x => ((x.user, x.product), x.rating)
}.join(data.map(x=>((x.user, x.product), x.rating))).values
math.sqrt(predictionsAndRating.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ + _) / n)
}
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
val sc = new SparkContext(conf)
//读取打分数据,并转成RDD
//(调用评分数据方法)
val productRatings = loadRatingData(args(0))
val productRatingRDD: RDD[Rating] = sc.parallelize(productRatings,1)
//计算:打分的个数,用户的个数,物品的个数
val numRatings = productRatingRDD.count()
val numUsers = productRatingRDD.map(x => x.user).distinct().count()
val numProducts = productRatingRDD.map(x => x.product).distinct().count()
println("评分数:"+numRatings+" 用户总数:"+numUsers+" 物品总数:"+numProducts)
/**
* ALS.train(productRatingRDD, rank, numit, lambda)
* productRatingRDD:评分矩阵
* rank :小矩阵中,特征向量的个数,推荐的经验值 建议:10-200之间
* rank值越大:表示:拆分的数据越准确
* rank值越小:表示:速度越快
* iteration:运行时的迭代(循环)次数,经验值:10左右
* lambda:控制正则化的过程,值越大:表示正则化过程越厉害,值越小,越准确,建议使用0.01
*/
val ranks = List(2, 4)
val lambdas = List(0.1, 1)
val iters = List(2, 5)
var bestModel: Option[MatrixFactorizationModel] = None
var bestRMSE = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumit = -1
//训练模型,以得到最佳的Model
for (rank <- ranks; lambda <-lambdas; numit <- iters) {
val model: MatrixFactorizationModel = ALS.train(productRatingRDD,rank,numit,lambda)
//计算RMSE
val rmse =computeRMSE(model,productRatingRDD,numRatings)
if (rmse < bestRMSE) {
bestModel = Some(model)
bestRMSE = rmse
bestLambda = lambda
bestNumit = numit
}
}
println("最佳模型:" + bestModel)
println("最佳的RMSE:"+bestRMSE)
println("最佳的Lambda:"+bestLambda)
println("最佳的迭代次数Numit:"+bestNumit)
//根据得到的最佳模型给用户1,推荐两个商品
val recomm = bestModel.get.recommendProducts(2, 2)
recomm.foreach { r =>{
println("用户:" + r.user.toString() + " 物品:" + r.product.toString() + " 评分:" + r.rating.toString())
}
}
}
}