初识HttpRunner
一、简介
1、什么是HttpRunner
一款面向http/https的通用自动化测试框架
2、HttpRunner的功能
自动化测试
性能测试
线上监控
持续集成
二、安装
既然HttpRunner这么多好处,当然要迫不及待地试试啦~
1、安装环境
centOS 6.5
python 3.6
说明:如何安装centOS 6.5,请老铁们参见VMware虚拟机下安装centOS系统
如何在linux下安装python 3.6,请老铁们参见Linux下安装配置python3.6
温馨提示:安装python 3.6时尽量兼容centOS 6.5内置的python2.6版本
2、安装HttpRunner
如果你已经安装好了centOS 6.5并配置好了python环境,那么就可以使用pip安装HttpRunner了,命令如下
pip install httprunner如果你需要更新到最新版本,只需要 -U 参数就可以了,命令如下
pip install -U HttpRunner常见问题:如果没有安装成功,则很有可能是你没有安装pip,如何安装pip,请老铁们自行参见Python安装pip
3、安装校验
输入hrun -V如果显示0.9.9则说明安装成功
4、三个命令
安装HttpRunner成功之后,系统中会有3个命令可供我们使用,分别是:
hrun:核心命令
locusts:基于Locust实现性能测试
har2case:辅助工具,将har格式地文档转换为yml/json格式的测试用例
简单说明:
使用hrun -h可以查看hrun命令的所有命令参数
使用har2case -h可以查看har2case的所有命令参数
三、运行
1、准备工作
如果你安装之后,跟我一样,不知从何入手,则可以参见作者为我们准备好的案例,运行案例之前,需要进入开发者模式,如何进入开发者模式,请老铁们移步至开发者模式
2、案例
如何使用HttpRunner,请参见作者为读者们准备好的案例,相信按照案例中的步骤,大家都能够很快上手,案例详情请参见典型案例
基于案例的HttpRunner的使用情况,大家可参见上一行中的“典型案例”链接,也可参见下文3、尝试
第一步:借用案例中抓取到的HAR格式的数据包demo-quickstart.har
第二步:使用har2case命令将HAR格式的数据包转化为json格式的测试用例
![]()
json格式的测试用例文件格式如图:一个json文件就是一个测试用例集
[
{
//config是全局配置项
//作用域为整个测试用例集,一个测试用例集中只有一个config
"config": {
"name": "testset description",
"variables": [],
"headers": {
"User-Agent": "python-requests/2.18.4"
}
}
},
{
//test对应单个接口的测试用例,包含单个请求、响应、校验过程
//作用域仅限于单个接口,一个测试用例集中可以有多个test
"test": {
"name": "/api/get-token",
"request": {
"url": "http://127.0.0.1:5000/api/get-token",
"headers": {
"device_sn": "FwgRiO7CNA50DSU",
"user_agent": "iOS/10.3",
"os_platform": "ios",
"app_version": "2.8.6",
"Content-Type": "application/json"
},
"method": "POST",
"json": {
"sign": "958a05393efef0ac7c0fb80a7eac45e24fd40c27"
}
},
"validate": [
{
"eq": [
"status_code",
200
]
},
{
"eq": [
"headers.Content-Type",
"application/json"
]
},
{
"eq": [
"content.success",
true
]
},
{
"eq": [
"content.token",
"baNLX1zhFYP11Seb"
]
}
]
}
},
{
"test": {
"name": "/api/users/1000",
"request": {
"url": "http://127.0.0.1:5000/api/users/1000",
"headers": {
"device_sn": "FwgRiO7CNA50DSU",
"token": "baNLX1zhFYP11Seb",
"Content-Type": "application/json"
},
"method": "POST",
"json": {
"name": "user1",
"password": "123456"
"validate": [
{
"eq": [
"status_code",
201
]
},
{
"eq": [
"headers.Content-Type",
"application/json"
]
},
{
"eq": [
"content.success",
true
]
},
{
"eq": [
"content.msg",
"user created successfully."
]
}
]
}
}
]
对测试用例文件的几点说明:
- 测试用例集:单个测试用例或多个测试用例的集合,表现形式为一个json文件
- 测试用例:单次http请求和响应过程,表现形式为json文件中的一个test
- config:全局配置项,作用于整个测试用例集
- test:作用于单个测试用例
- 如果一个变量在config中定义了,在test中没有定义,则test会继承该变量
- 如果一个变量在config和test中都定义了,则test会使用自己定义的变量值
- 各个test的空间相互独立,互不影响
- 如果在多个test之前传递参数值,则需要使用extract关键字,并且只能从前向后传递
第三步:运行测试用例demo-quickstart0.json

很可惜,运行出现错误,错误信息如下
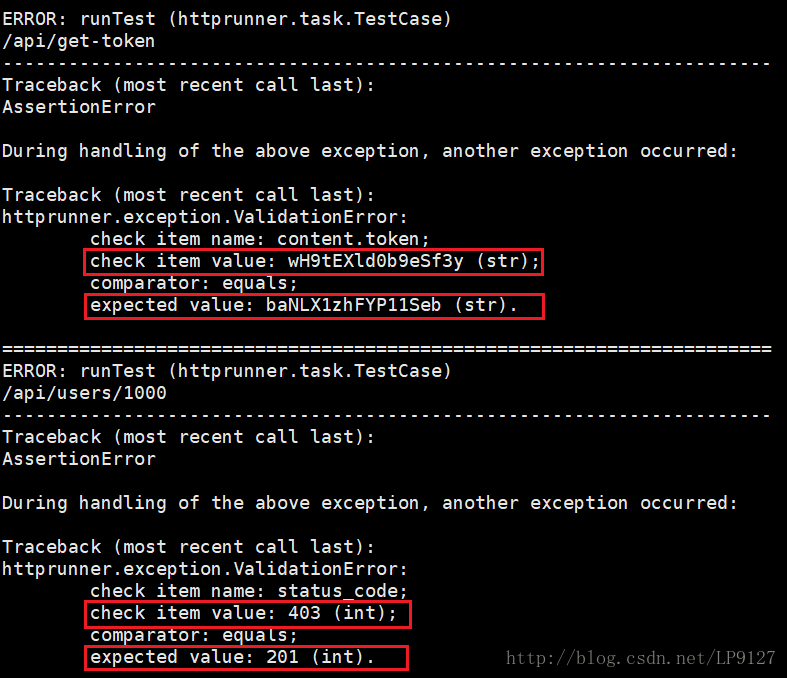
如何分析错误呢?主要看check item value和expected value两个字段,通过对比这两个字段的值,可以发现第一个错误是因为获取的token值与预期不一致;第二个错误的状态是403,该状态码表明对请求资源的访问被服务器拒绝了,应该是访问权限出现某些问题,导致权限检验失败。
第一个错误:原因是har2case生成json格式的测试用例时,会将第一层级中的key-value转化成validator。
- 小疑问1:什么是第一层级?原来json中是分很多层级的,详情请移步JSON数据解析
- 小疑问2:validator就是检查项,即验证的意思
- 解决方法:在测试用例的validate中去掉动态变化的值,即去掉

第二个错误:token权限检验的问题,即第二个test获取到的token仍是抓包时获取的token值,但是当运行测试用例的时候,之前获取的token已经失效了,因此会出现权限检验失败的问题
- 解决方法:先动态获取到第一个test中的token,后续的test的token使用前面获取到的token
- 小疑问1:如何动态获取到第一个test中的token呢?这就要用到HttpRunner中的参数提取功能了,需要用到的关键字是extract,具体写法如下

- 小疑问2:后续的test如何使用前面获取到的token呢?HttpRunner支持参数引用功能
$var,使用这个功能,后续的test就可以使用前面获取到的token啦,具体写法如下
目前为止,我们已经将两个错误进行分析并改正,将改正之后的文件另存为demo-quickstart1.json,再次运行一下,运行结果如下

不错不错,很显然已经运行成功,但是HttpRunner的作者并没有局限于此,后续给出了三个优化点,在介绍这三个优化点之前,请读者们先自行思考,看看自己能不能找到需要优化的方面都有哪些呢?如果找到了,请为自己打call,如果没找到,请为HttpRunner的作者打call,打call完毕之后我们接着来看优化的点有哪些?
4、优化
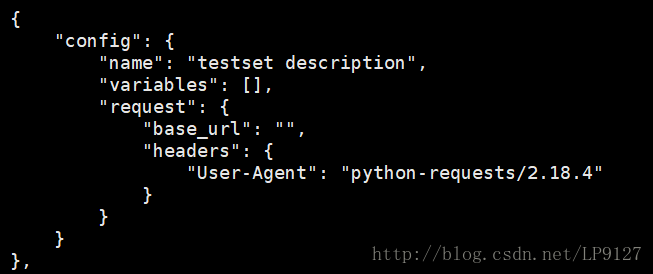
第一点:公共配置全局化
将各个test中公共的部分(device_sn、Content-Type、host)提取出来,放到config中
调整之前的config如下
调整后的config如下

第二点:变量的声明和引用
如果同一个参数在测试用例中出现多次,较好的做法是将该参数定义为变量,然后在需要参数的地方进行引用
- 变量的声明:在config或test中可通过 variables 关键字定义变量
- 变量的引用:在config或test中可通过
$+变量名称的方式引用变量
将测试用例中的硬编码参数(onfig 模块中的 device_sn,第一条测试用例中的 user_agent、os_platform、app_version)等参数进行声明和引用
- 改动之前
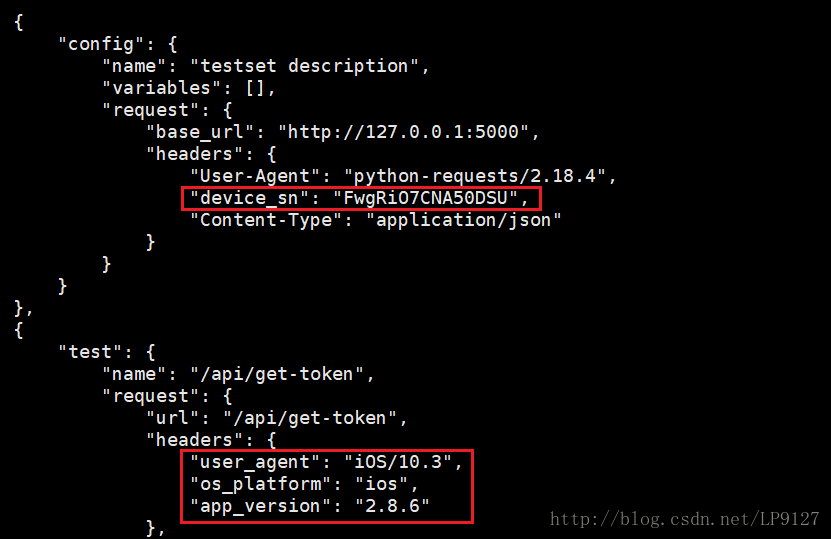
- 改动之后

第三点:数据参数化
在上述用例集中,参数 device_sn 采用的是硬编码方式,这好像与真实场景不大相符啊,显然这个参数是要进行变化的,同时sign字段也是要随着device_sn 的变化而变化的,可是,怎么才能让device_sn 和sign每次运行测试用例后都产生变化呢?那必然是要用函数来实现的,可是怎样才能在JSON格式的测试用例集中调用函数呢?没错,HttpRunner是支持热加载的插件机制的,也就是说,可以在 YAML/JSON 中可以调用 Python 函数。
- 小疑问:JSON格式的文件中只能调用python函数吗?
具体做法
- 首先在测试用例的同级或者父级目录创建一个.py文件,然后在文件中定义测试用例集中需要用到的函数或变量。
- 在JSON文件中对.py文件中定义的函数进行调用,格式为
${fun($var)} 在JSON文件中对.py文件中定义的函数进行引用,格式为
$+变量名方法就介绍到这里,针对案例中的情况,如何实现device_sn 的随机字符串生成功能和sign的签名算法,请读者们自行思考。
温馨提示:懒得动脑的宝宝请参见HttpRunner作者的做法数据参数化
至此,已经对demo-quickstart1.json进行了三点优化了,将优化后的文件存为demo-quickstart2.json,然后在运行一下测试用例,结果毫无疑问是成功的,不信请看
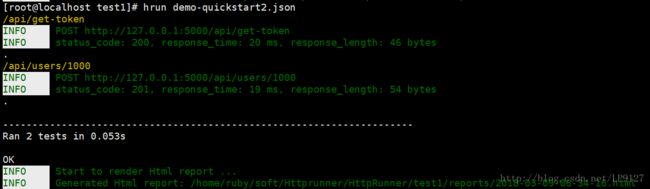
第四点:数据驱动
再继续往下看,作者的测试用例集中有两个测试用例,一个是获取权限,另一个就是创建用户,在提出问题之前我们再回顾一下测试用例
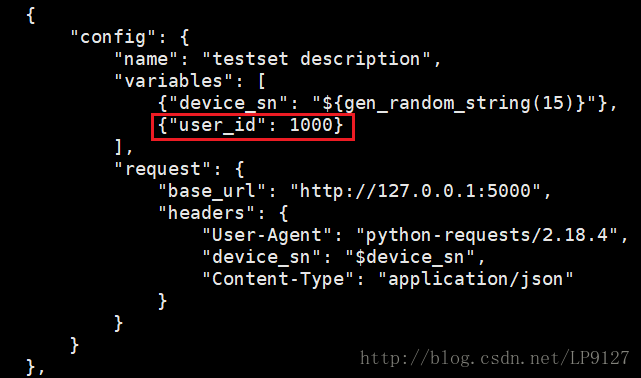
咦?这个user_id是固定值的!如果我们要创建user_id为1001~2000等1000个用户,那就要修改1000次user_id,然后再运行1000次测试用例吗?
显然这是很不自动的,这个时候就要请“参数化数据驱动功能”闪亮登场了,大家欢迎~~~
不过在体验这个功能之前,大家先要做好准备工作
准备工作一:使用parameters关键字进行参数定义,使用Sequential关键字定义参数的取值方式,具体格式如下

同时,我们将测试用例文件修改为demo-quickstart3.json准备工作二:在测试用例文件的同级目录中创建
.csv文件来存储参数列表,一定要注意文件名称和参数名称保持一致,同时约定.csv文件中第一行为参数名称,第二行开始为参数值,此后每个值占一行,具体格式如下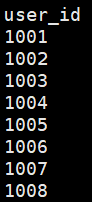
那么问题又来了,如果我要一次性创建user_id为1001~2000等2000个用户呢?难不成要手动在user_id.csv文件中手动敲入1001~2000,这个好像有点挫,还好.csv文件支持python写入,这就好办多了,写一个python脚本,将1001~2000写入user_id.csv文件中,以下是我自己写的writer.py
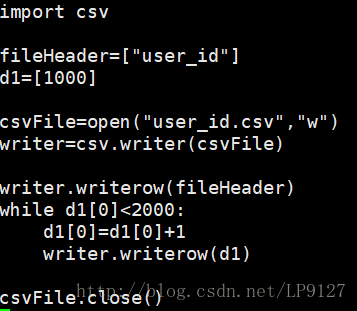
做完这一系列准备之后,我们来试一下测试用例能否成功创建2000个用户呢?,毫无疑问,运行成功了,但是全部截图好像有点困难,就截最后一部分一小丢丢给大家展示一下
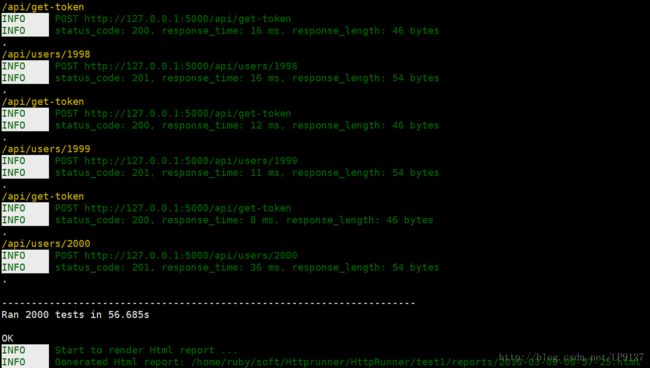
文章写到这里,我想大家已经可以简单的使用HttpRunner了,下面是我自己针对用户进行的创建、修改、查询、删除等操作,读者们可自行略过
四、简单操作
对于以下4个用例,只需要一个测试用例集hruntest.json即可
目标:创建user_id1001~2000,等1000个用户,并对每一个用户实现查询、修改密码、删除。
准备一:在同级目录下创建user_id-password-newpassword.csv文件,用来存放数据;
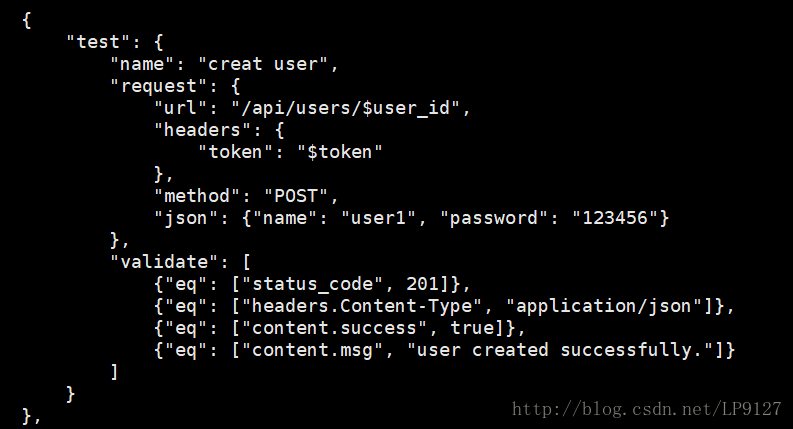
准备二:创建write.py文件,用来向user_id-password-newpassword.csv文件写入数据1、创建用户
测试用例如下
2、查询用户
测试用例如下

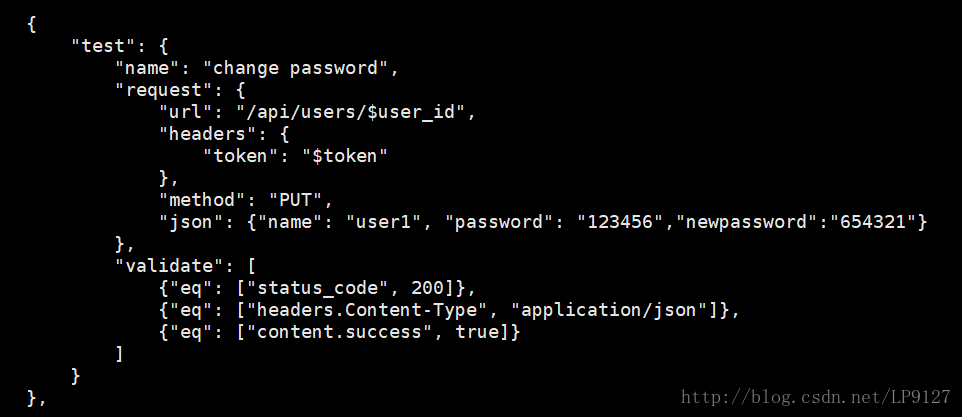
3、修改用户密码
测试用例如下
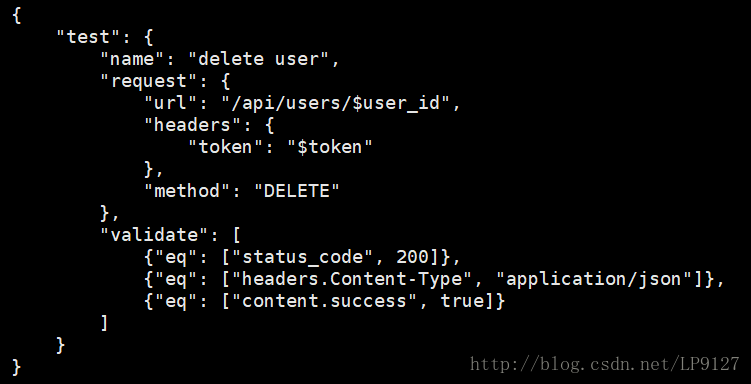
4、删除用户
测试用例如下
一起来看一下运行结果吧

执行成功~~~
致谢
感谢HttpRunner的作者开发的这款自动化测试工具,由于本人是第一次接触自动化测试工具,暂时提不出什么建设性的建议,各位路过的大佬如果有什么建议,欢迎留言。
最后附上作者的HttpRunner中文使用手册:HttpRunner中文使用手册