关联规则,Apriori算法及python实现
1 关联规则
关联分析一个典型的例子是购物篮分析,广泛应用于零售业,通过查看那些商品经常在一起购买,可以帮助商店了解用户的购买行为。一个最有名的例子是“尿布与啤酒”,据报道,美国中西部的一家连锁店发现,男人们会在周四购买尿布和啤酒,这样商家实际上就可以将尿布和啤酒放在一块,并确保在周四全价销售从中获利。
关联分析(关联规则学习):从大规模数据集中寻找物品间的隐含关系
但是一般销售数据库巨大,如何快速找到数据库中物品之间的联系成为主要的难题,Apriori算法在1996年应运而生,改算法可以高效的找出频繁项集,并从频繁项集中抽取除关联规则。当然,该算法不仅应用在零售业,在特征关联等领域也有广泛应用。
关联分析中所需的两个度量公式:
1. 频繁项集度量支持度(support):
support(x,y)=numberofbuy(x,y)allofbuy
2. 关联规则度量可信度(confidence):
confidence(x−>y)=numberofbuy(x,y)numberofbuy(x)=support(x,y)support(x)
可信度的值应接近于1,且显著大于人们购买Y的支持度,即如果购买X,Y的顾客很少,那么该条还是没有价值的,支持度展示了关联规则的统计显著性,可信度展示关联规则的强度。
2 Apriori算法
1. Apriori算法原理
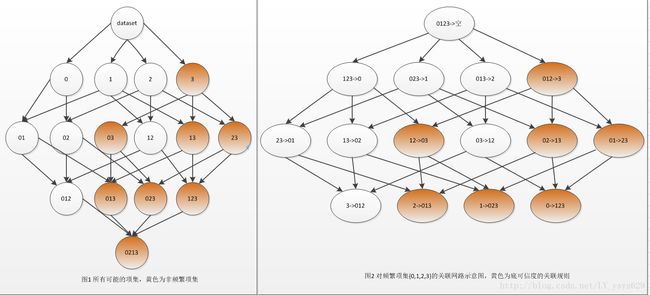
频繁项集:如果某个项集是频繁的,那么他的子集也是频繁的。例如,有四种商品,0,1,2,3,其中{0,1}是频繁项集,即同时购买商品0和1的购买行为数量在总的购买行为占比较大(一般会有认为给定的最小支持度的阈值来区分是否是频繁项集),那么,{0}和{1}也是频繁项集。反之,如果如果项集不是频繁项集,那么他的超集也不是频繁项集,例如,如果{0}不是频繁项集,那么{0,1},{0,1,2}…也不是频繁项集。
关联规则:从某一频繁项集中挖掘关联规则,我们关注的是,某一频繁项集中是否存在由某个元素或元素集合可能会推导出另一个或几个元素,若该关联关系用”->”表示,则箭头左侧称为前件,箭头右侧称为后件,Apriori算法挖掘关联规则的做法是,首先从一个频繁项集出发,穿件一个规则列表,其中右部(后件)只包含一个元素,然后从该组规则中找出可信度大于最小可信度的规则集合,并用该组具有较高可信度的规则合并成新的规则列表,其中右部(后件集合中)包含两个元素,递推进行此过程。
Apriori算法生成频繁项集及关联规则挖掘示意图
3 python实现Apriori算法
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 03 09:42:41 2017
Apriori
@author: jipingliu
"""
def loadDataSet():
'''
输入:无
功能:产生简单的数据集
输出:dataset
'''
return [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]
def createC1(dataset):
'''
输入:数据集
功能:产生类似[[1], [2], [3], [4], [5]],C1中包含的元素为数据集中出现的元素
输出:C1
'''
C1 = []
for transction in dataset:
#print transction
for item in transction:
if not [item] in C1:
C1.append([item])#使用列表作为C1元素是因为后续需要使用集合操作
C1.sort()
return map(frozenset,C1)
def scanDataSet(DataSet,Ck,minSupport):
'''
输入:DataSet应为每条记录是set类型数据(被用于判断是否是其子集操作),Ck中的每个项集为frozenset型数据(被用于字典关键字)
Ck为候选频繁项集,minSupport为判断是否为频繁项集的最小支持度(认为给定)
功能:从候选项集中找出支持度support大于minSupport的频繁项集
输出:频繁项集集合returnList,以及频繁项集对应的支持度support
'''
subSetCount = {}
for transction in DataSet:#取出数据集dataset中的每行记录
for subset in Ck:#取出候选频繁项集Ck中的每个项集
if subset.issubset(transction):#判断Ck中项集是否是数据集每条记录数据集合中的子集
if not subSetCount.has_key(subset):subSetCount[subset] = 1
else:
subSetCount[subset] += 1
numItem = float(len(DataSet))
returnList =[]
returnSupportData = {}
for key in subSetCount:
support = subSetCount[key]/numItem
if support >= minSupport:
returnList.insert(0,key)
returnSupportData[key] = support
return returnList,returnSupportData
def createCk(Lk,k):
returnList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1,lenLk):
L1 = list(Lk[i])[:k-2];L2 = list(Lk[j])[:k-2]
L1.sort();L2.sort()
if L1 == L2:#只需取前k-2个元素相等的候选频繁项集即可组成元素个数为k+1的候选频繁项集!!
returnList.append(Lk[i] | Lk[j])
return returnList
def apriori(dataset,minSupport = 0.5):
C1 = createC1(dataset)
DataSet = map(set,dataset)
L1,returnSupportData = scanDataSet(DataSet,C1,minSupport)
L = [L1]
k = 2
while (len(L[k-2]) > 0):
#由上一时刻的频繁项集Lk-1,两两组合形成下一时刻没有重复的频繁项集,下一时刻候选频繁项集中元素个数会比上一时刻的多1
Ck = createCk(L[k-2],k)
#从候选频繁项集中选出支持度大于minsupport的频繁项集Lk
Lk,supportLk = scanDataSet(DataSet,Ck,minSupport)
#将该频繁项集及其支持度添加到returnSupportData字典中记录,其中频繁项集为关键字,支持度为关键字所对应的项
returnSupportData.update(supportLk)
#将频繁项集添加到列表L中记录
L.append(Lk)
#逐一增加频繁项集中的元素个数
k += 1
return L, returnSupportData
#------------------关联规则生成函数--------------#
def generateRules(L,supportData,minConference = 0.7):
bigRuleList = []
for i in range(1,len(L)):
for subSet in L[i]:
H1 = [frozenset([item]) for item in subSet]
if (i > 1):
rulesFromConseq(subSet, H1, supportData, bigRuleList, minConference)
else:
calculationConf(subSet, H1, supportData,bigRuleList,minConference)
return bigRuleList
def calculationConf(subSet, H, supportData,brl,minConference=0.7):
prunedH = []
for conseq in H:
conf = supportData[subSet]/supportData[subSet - conseq]
if conf >= minConference:
print subSet-conseq,'-->',conseq,'conf:',conf
brl.append((subSet-conseq,conseq,conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(subSet, H, supportData, brl, minConference):
m = len(H[0])
#如果频繁项集中每项元素个数大于买m+1,即,可以分出m+1个元素在规则等式右边则执行
if (len(subSet) > (m+1)):
#利用函数createCk生成包含m+1个元素的候选频繁项集后件
Hm = createCk(H, (m+1))
#计算前件(subSet - Hm)--> 后件(Hm)的可信度,并返回可信度大于minConference的后件
Hm = calculationConf(subSet,Hm,supportData,brl,minConference)
#当候选后件集合中只有一个后件的可信度大于最小可信度,则结束递归创建规则
if (len(Hm) > 1):
rulesFromConseq(subSet, Hm, supportData, brl, minConference)
#------------------关联规则生成函数end--------------#
if __name__ =='__main__':
dataset = loadDataSet()
L,returnSupportData = apriori(dataset,minSupport=0.5)
rule = generateRules(L, returnSupportData, minConference =0.5)