python之时间序列
不管在哪个领域中(如金融学、经济学、生态学、神经科学、物理学等),时间序列(time series)数据都是一种重要的结构化数据形式。在多个时间点观察或测量到的任何事物都可以形成一段时间序列。很多时间序列都是固定频率的,也就是说,数据点是根据某种规律定期出现的(比如每15秒、每5分钟、每个月出现一次)。时间序列也可以是不定期的。时间序列数据的意义取决于具体的应用场景,主要有以下几种:
- 时间戳(timestamp),特定的时刻。
- 固定时期(period),如2018年4月或2017全年。可以看做时间间隔的特例。
- 时间间隔,由起始和结束时间戳表示。
- 实验或过程时间,每个时间点都是相对于特定起始时间的一个度量。
日期和时间数据类型及工具
python标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。主要用到的模块:datetime、time以及calendar模块。

代码示例:
from datetime import datetime
from datetime import timedelta
#毫秒形式存储日期和时间
#datetime(year, month, day, hour, minute, second, microsecond)
now = datetime.now() #now=datetime.datetime(2018, 4, 10, 16, 56, 29, 739397)
#datetime.timedelta表示两个datetime对象之间的时间差
#timedelta(days,seconds)
delta = datetime(2018, 4, 10) - datetime(2017, 7, 1, 1, 20)
#delta= datetime.timedelta(282, 81600)
#给datetime对象加/减上timedelta
start = datetime(2018, 1, 1)
start + timedelta(12) #result:datetime.datetime(2018, 1, 13, 0, 0)
start - 2 * timedelta(12) #result:datetime.datetime(2017, 12, 8, 0, 0)字符串与datatime之间的相互转换
- 利用str或strftime方法,可以将datetime对象和pandas的Timestamp对象被格式化为字符串;
- datetime.strptime也可以用这些格式化编码将字符串转换为日期;
- dateutil包中parser.parse方法进行日期解析,可以解析几乎所有日期表现形式。
- pandas.to_datetime可以解析多种不同的日期表现形式
datetime中格式定义(英语系统下):


代码示例:
from dateutil.parser import parse
import pandas as pd
#字符串与datetime对象的转换
#datetime对象转换为字符串
stamp = datetime(2018, 1, 1)
#第一种str方法
str(stamp) #'2018-01-01 00:00:00'
#第二中strftime
stamp.strftime('%Y-%m-%d')
#字符串对象转换为datetime,利用strptime
#strptime通过已知格式进行日期解析的最佳方法
value = '2018-01-01' #'2018-01-01'
datetime.strptime(value, '%Y-%m-%d')
#parser.parse方法进行日期解析,可以解析几乎所有日期表现形式。
parse('2018-01-01') #datetime.datetime(2018, 1, 1, 0, 0)
parse('Jan 01, 2018 6:45 PM') #datetime.datetime(2018, 1, 1, 18, 45)
#parse解析字符串时,默认月在前,日在后
parse('6/12/2011') # datetime.datetime(2011, 6, 12, 0, 0)
#因此,对于日在前,月在后的,可以设置 dayfirst=True
parse('6/12/2011', dayfirst=True) #datetime.datetime(2011, 12, 6, 0, 0)
#to_datetime可以解析多种不同的日期表现形式
datestrs = ['2018-01-01 12:00:00', '2018-02-22 00:00:00']
pd.to_datetime(datestrs)
#DatetimeIndex(['2018-01-01 12:00:00', '2018-02-22 00:00:00'], dtype='datetime64[ns]', freq=None)
#还可以处理缺省值(空字符串或None)
idx = pd.to_datetime(datestrs + [None])
#idx=DatetimeIndex(['2018-01-01 12:00:00', '2018-02-22 00:00:00', 'NaT'], dtype='datetime64[ns]', freq=None)
#注意:日期中的缺省值是NaT(Not a Time)
pd.isnull(idx) #array([False, False, True], dtype=bool)二、世界序列基础
pandas最基础的时间序列类型就是以时间戳(通常以python字符串或datetime对象表示)为索引的Series。
主要两部分:
- 索引、选取、子集构造;
- 带重复索引的时间序列。
#索引、选取、子集构造
#索引
#方法1,传入一个Timestamp对象
stamp = ts.index[0] #stamp=Timestamp('2018-01-02 00:00:00')
ts[stamp] # -0.10607355595045509
#传入一个可以被解释为日期的字符串
ts['1/10/2018'] #-1.5461476964186704
ts['20180110'] #-1.5461476964186704
#切片
#对于较长的时间序列,通过传入“年”、“年月”即可轻松选取数据切片
longer_ts = pd.Series(np.random.randn(1000),
index=pd.date_range('1/1/2018', periods=1000))
longer_ts['2018']
longer_ts['2018-03']
#通过日期进行切片的方式只对规则的Series有效
ts[datetime(2018, 1, 10):]
"""ts: ts[datetime(2018, 1, 10):]:
2018-01-02 -0.106074 2018-01-10 -1.546148
2018-01-03 0.100822 2018-01-13 0.141358
2018-01-06 -0.894717 dtype: float64
2018-01-08 -0.498678
2018-01-10 -1.546148
2018-01-13 0.141358
dtype: float64
"""
#时间序列大部分按时间先后顺序排列,可以使用不存在该时间序列的时间戳来进行切片(即:查询范围)
ts['1/5/2018':'1/15/2018']
"""
2018-01-06 -0.894717
2018-01-08 -0.498678
2018-01-10 -1.546148
2018-01-13 0.141358
dtype: float64
"""
#截取两个日期之间的TimeSeries
#截取2018-1-9之前的徐磊
ts.truncate(after='1/9/2018')
"""
2018-01-02 -0.106074
2018-01-03 0.100822
2018-01-06 -0.894717
2018-01-08 -0.498678
dtype: float64
"""
#对于DataFrame对象同样有用,时间点只取周三(freq='W-WED')
dates = pd.date_range('1/1/2018', periods=100, freq='W-WED')
long_df = pd.DataFrame(np.random.randn(100, 4),
index=dates,
columns=['Colorado', 'Texas',
'New York', 'Ohio'])
long_df.loc['3-2018']
"""
Colorado Texas New York Ohio
2018-03-07 0.903078 -0.931066 0.213840 0.169752
2018-03-14 1.874872 -0.682288 -0.820822 -0.451576
2018-03-21 0.381608 -0.493432 0.284216 0.353538
2018-03-28 -0.412199 0.102380 -0.363941 -1.693375
"""
#带重复索引的时间序列
dates = pd.DatetimeIndex(['1/1/2018', '1/2/2018', '1/2/2018',
'1/2/2018', '1/3/2018'])
dup_ts = pd.Series(np.arange(5), index=dates)
"""dup_ts=
2018-01-01 0
2018-01-02 1
2018-01-02 2
2018-01-02 3
2018-01-03 4
dtype: int32
"""
#利用is_unique属性查询是否唯一
dup_ts.index.is_unique # False
#索引时,如果索引重复,则产生标量值,反之,则产生切片
dup_ts['1/3/2018'] # 索引不重复,4
dup_ts['1/2/2018'] # 索引重复的
"""
2018-01-02 1
2018-01-02 2
2018-01-02 3
dtype: int32
"""
#对非唯一时间戳进行聚合,并传入level=0(索引的唯一一层!)
grouped = dup_ts.groupby(level=0)
grouped.mean()
grouped.count()
"""
grouped.mean(): grouped.count():
2018-01-01 0 2018-01-01 1
2018-01-02 2 2018-01-02 3
2018-01-03 4 2018-01-03 1
"""
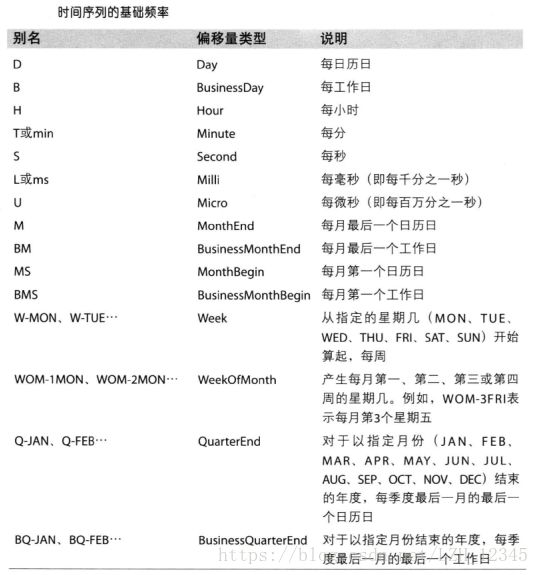
附:时间序列的基础频率一览表: