Python数据分析与可视化的基础知识(带例子)

一、数据分析库
在数据分析中,有许多常用的数据分析库可以帮助我们进行数据处理、探索和可视化。以下是几个常见的数据分析库和它们的功能:
1.NumPy
NumPy是一个功能强大的科学计算库,提供了多维数组对象和各种计算功能,用于高效地处理大规模数据集。它还提供了许多数学函数和线性代数操作。
2.pandas
pandas是基于NumPy的数据处理和分析库,提供了高效的数据结构和数据分析工具,如Series和DataFrame,可用于数据清洗、预处理和分析。pandas还具有强大的数据索引和数据合并功能。
3.Matplotlib
Matplotlib是一个用于数据可视化的常用库,提供了绘制各种类型图表的函数。它可以绘制折线图、柱状图、散点图、饼图等,并支持自定义图表样式。
4.Seaborn
Seaborn是建立在Matplotlib之上的高级数据可视化库,提供了更漂亮、更统一的图表样式,并提供了一些高级的统计图表,如热图、分类散点图等。
5.SciPy
SciPy是一个用于科学计算和数据分析的库,提供了许多数值计算和优化算法,以及统计分析和信号处理等功能。它还包含了一些常用的概率分布和统计检验的函数。
6.Scikit-learn
Scikit-learn是一个用于机器学习和数据挖掘的库,包含了各种常见的机器学习算法和工具,如分类、回归、聚类、降维等。它还提供了模型选择、特征选择和模型评估等功能。
更多的理论知识我就不列举了,大家可以去看这位博主的:
Python数据分析与可视化概述(内容全面 附PPT)_python数据可视化概述-CSDN博客
二、数据处理和分析
1.数据清洗
在进行数据分析之前,通常需要对数据进行清洗。这包括处理缺失值、重复值和异常值。常用的方法包括填充缺失值、删除重复值和通过统计方法或可视化方法识别和处理异常值。
# 填充缺失值
data.fillna(0, inplace=True)
# 删除重复值
data.drop_duplicates(inplace=True)
# 转换数据类型
data['Age'] = data['Age'].astype(int)2.数据转换
有时需要将数据从一种格式转换为另一种格式,或者将数据类型转换为适合分析的类型。例如,将字符串类型转换为数字类型,或者将日期转换为特定的时间格式。
import pandas as pd
# 数据类型转换
data['column_name'] = data['column_name'].astype(float) # 将字符串类型转换为数字类型
data['column_name'] = data['column_name'].astype(str) # 将数字类型转换为字符串类型
data['column_name'] = pd.to_datetime(data['column_name']) # 将日期字符串转换为日期类型
# 数据格式转换
data = pd.melt(data, id_vars=['id'], value_vars=['var1', 'var2'], var_name='variable', value_name='value') # 将数据从宽格式转换为长格式
data = data.pivot(index='id', columns='variable', values='value') # 将数据从长格式转换为宽格式
# 数据缺失值填充
data['column_name'].fillna(data['column_name'].mean(), inplace=True) # 使用均值填充缺失值
data['column_name'].fillna(data['column_name'].median(), inplace=True) # 使用中位数填充缺失值
data['column_name'].fillna(data['column_name'].mode()[0], inplace=True) # 使用众数填充缺失值3.数据聚合和分组
在数据分析中,经常需要对数据进行聚合和分组操作。这涉及到计算均值、中位数、总和等统计指标,以及按照某个列或多个列进行分组并进行相应的计算。
import pandas as pd
# 创建示例数据
data = pd.DataFrame({'category': ['A', 'B', 'C', 'A', 'B'],
'numeric': [10, 20, 30, 40, 50]})
# 分组操作
grouped = data.groupby('category')
# 对分组后的数据进行求和
sum_result = grouped.sum()
# 对分组后的数据进行均值计算
mean_result = grouped.mean()
# 对分组后的数据进行计数
count_result = grouped.count()
# 对分组后的数据进行多个聚合计算
agg_result = grouped.agg({'numeric': ['sum', 'mean'], 'category': 'count'})
# 自定义聚合函数
def custom_agg_func(x):
return x.max() - x.min()
# 对分组后的数据应用自定义聚合函数
custom_agg_result = grouped.agg(custom_agg_func)
# 对分组后的数据进行转换
transform_result = grouped.transform(lambda x: x - x.mean())三、数据可视化matplotlib库
数据可视化是一种有效的方式,可以通过图表、图形和图像等形式将数据直观地呈现出来。以下是一些常见的数据可视化方法和相应的代码示例:
python的数据可视化库有很多个,matplotlib是其中最基础、最常用的。
1.折线图
折线图适合用于展示随时间变化的数据趋势。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df=pd.read_excel("航空公司数据.xlsx")
df['入会时间']
df['入会年份']=df['入会时间'].dt.year
yu2=df.groupby('入会年份').size()
x=yu2.index
y=yu2.values
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.plot(
x,
y,'--'
)
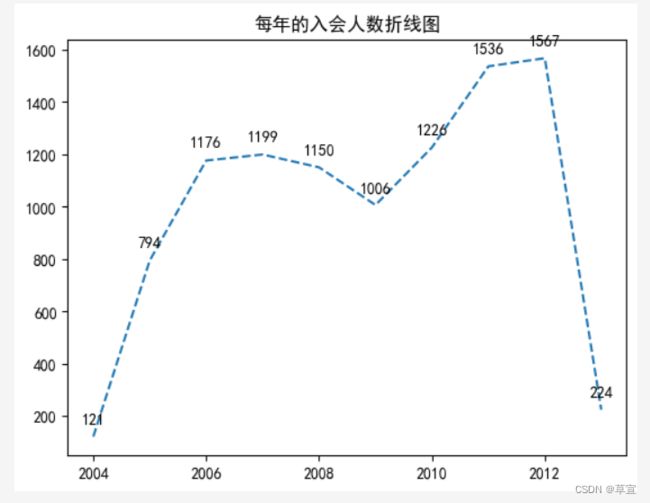
plt.title("每年的入会人数折线图")
for a,b in zip(x,y):
plt.text(a,b+50,f'{b}',ha='center')
plt.show()可以得出:
2.柱状图
柱状图适合用于比较不同类别之间的数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df=pd.read_excel("航空公司数据.xlsx")
yu=df.groupby('工作地所在省份').size().sort_values(ascending=False)[:30]
plt.rcParams['font.sans-serif'] = 'SimHei'#解决乱码
plt.figure(figsize=(12, 6))
yu.plot(kind='bar')
plt.title("用户所在省份分布图(前30名)")
plt.xlabel("省份")
plt.ylabel("数量")
plt.xticks(rotation=45)
plt.show()
3.散点图
散点图适合用于展示两个变量之间的关系。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
df=pd.read_excel("航空公司数据.xlsx")
average_discount_coefficient =df["平均折扣系数"]
flight_mileage =df["飞行里程数"]
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.figure(figsize=(10, 5))
plt.scatter(average_discount_coefficient, flight_mileage)
plt.title("用户“平均折扣系数”和“飞行里程数”数据的散点图")
plt.xlabel("平均折扣系数")
plt.ylabel("飞行里程数")
plt.show()
4.饼图
饼图适合用于展示不同类别占比的情况。
import pandas as pd
import matplotlib.pyplot as plt
#查看是否为字符串序列
join_dates=df['入会时间']
#创建表示今天的时间对象
today = datetime.now()
#计算时间差序列,只要年
df['飞龄'] = (today - join_dates).dt.days//365
# 将飞龄数据进行分组,并统计各组人数
grouped_data = pd.cut(df['飞龄'], bins=list(range(9,24,3)), right=False)#for in
#分组统计各个区间的频数
grouped_data1=df.groupby(grouped_data).size()
# 绘制饼图
plt.pie(x=grouped_data1.values, labels=grouped_data1.index, autopct='%1.1f%%',explode=[0,0,0,0.2],startangle=90)
plt.axis('equal') # 使饼图为圆形
plt.title('用户飞龄分布饼图')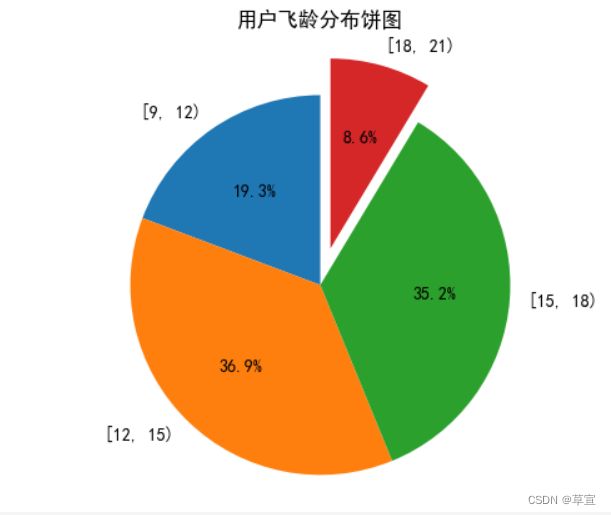
四、数据可视化pyecharts库
Pyecharts是一个基于Echarts的Python数据可视化库,它提供了丰富的图表类型和交互功能,相较于matplotlib而言,pyecharts库绘制的图形种类更多,样式更精美、丰富。
1.柱状图(Bar)
from pyecharts import options as opts
from pyecharts.charts import Bar
data = [("A", 10), ("B", 20), ("C", 30), ("D", 40)]
bar = (
Bar()
.add_xaxis([x[0] for x in data])
.add_yaxis("Value", [x[1] for x in data])
.set_global_opts(title_opts=opts.TitleOpts(title="Bar Chart"))
)
bar.render("bar_chart.html")2.折线图(Line)
from pyecharts import options as opts
from pyecharts.charts import Line
data = [("A", 10), ("B", 20), ("C", 30), ("D", 40)]
line = (
Line()
.add_xaxis([x[0] for x in data])
.add_yaxis("Value", [x[1] for x in data])
.set_global_opts(title_opts=opts.TitleOpts(title="Line Chart"))
)
line.render("line_chart.html")3.散点图(Scatter)
from pyecharts import options as opts
from pyecharts.charts import Scatter
data = [(1, 10), (2, 20), (3, 30), (4, 40)]
scatter = (
Scatter()
.add_xaxis([x[0] for x in data])
.add_yaxis("Value", [x[1] for x in data])
.set_global_opts(title_opts=opts.TitleOpts(title="Scatter Chart"))
)
scatter.render("scatter_chart.html")4.饼图(Pie)
from pyecharts import options as opts
from pyecharts.charts import Pie
data = [("A", 10), ("B", 20), ("C", 30), ("D", 40)]
pie = (
Pie()
.add("", data)
.set_global_opts(title_opts=opts.TitleOpts(title="Pie Chart"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
pie.render("pie_chart.html")五、结束
在这篇博客中,我介绍了Python数据分析与可视化的基础知识,包括数据清洗、处理、分析和可视化等方面的内容。我们学习了如何使用pandas、numpy和matplotlib等库来处理和展示数据,以及如何绘制柱状图、散点图和折线图等常见的可视化图表。希望这些知识对你入门数据分析与可视化有所帮助,同时也鼓励你继续深入学习和探索更高级的数据处理和可视化技术。