机器学习实现原理分析(一) —— SOM简述版
代码参考:https://github.com/apachecn/AiLearning/blob/master/blog/ml/6.支持向量机.md
其他内容主要参考李航《统计学习方法》
以下是函数的输入输出,也就是算法通过迭代最后得出 b b b和 α \alpha α
smoSimple
Args:
dataMatIn 数据集
classLabels 类别标签
C 松弛变量(常量值),允许有些数据点可以处于分隔面的错误一侧。
控制最大化间隔和保证大部分的函数间隔小于1.0这两个目标的权重。
可以通过调节该参数达到不同的结果。
toler 容错率(是指在某个体系中能减小一些因素或选择对某个系统产生不稳定的概率。)
maxIter 退出前最大的循环次数
Returns:
b 模型的常量值
alphas 拉格朗日乘子
SOM中一个 α i \alpha_i αi对应一个样本点 ( x i , y i ) (x_i,y_i) (xi,yi),变量的总数等于训练样本容量N。
所以,一共要迭代N次:
for i in rang(shape(dataMatrix)[0]):
先随机选取一个 α i \alpha_i αi并带入其中求出 y i y_i yi:已知 y = ω . T ∗ x [ i ] + b y=\omega.T * x[i]+b y=ω.T∗x[i]+b,其中 ω = Σ i = 1 n α i ∗ y i ∗ x i \omega=\Sigma_{i=1}^n\alpha_i *y_i *x_i ω=Σi=1nαi∗yi∗xi,由此可以求出 y i y_i yi和误差 E i E_i Ei:
fXi = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b
Ei = fXi - float(labelMat[i])
SMO是选择其中的两个 α i \alpha_i αi和 α j \alpha_j αj进行优化,其他值保持不变。
对于不符合KKT约束条件和发生错误的概率超过容忍值时需要进行优化,其中KKT约束条件为 0 < = a l p h a s [ i ] < = C 0<=alphas[i]<=C 0<=alphas[i]<=C,我们用 l a b e l M a t [ i ] ∗ E [ i ] labelMat[i] *E[i] labelMat[i]∗E[i]表示错误发生的概率:
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i, m)
#随机选择非i的一点alphas[j]进行优化
# 预测j的结果
fXj = float(multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[j, :].T)) + b
Ej = fXj - float(labelMat[j])
假设初始可行解为 α i o l d \alpha_i^{old} αiold和 α j o l d \alpha_j^{old} αjold,最优解分别为 α i n e w \alpha_i^{new} αinew和 α j n e w \alpha_j^{new} αjnew, L L L和 H H H分别是 α j n e w \alpha_j^{new} αjnew所在对角线段端点的界:
L < = α j n e w < = H L<=\alpha_j^{new}<=H L<=αjnew<=H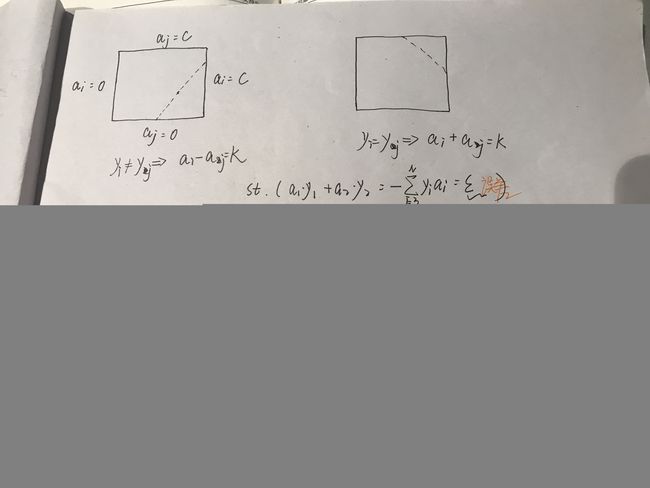
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
# 如果相同,就没发优化了
if L == H:
print("L==H")
continue
先考虑沿着约束方向未考虑 0 < = α i < = C 0<=\alpha_i<=C 0<=αi<=C的解(即未经剪辑): g ( x ) = Σ i = N N a i ∗ y i ∗ k ( x i , x ) + b g(x) =\Sigma_{i=N}^{N}a_i*y_i*k(x_i,x)+ b g(x)=Σi=NNai∗yi∗k(xi,x)+b
令: E i = g ( x i ) − y i E_i =g(x_i)-y_i Ei=g(xi)−yi当 i = 1 , 2 i=1,2 i=1,2时, E i E_i Ei为函数对输入 x i x_i xi的预测值和真实输出 y i y_i yi之差
定理:最优化问题未经剪辑的解 a 2 n e w , u n c = a 2 o l d + y 2 ( E 1 − E 2 ) η a_2^{new,unc}=a_2^{old} + \frac{y_2(E_1-E_2)}{\eta} a2new,unc=a2old+ηy2(E1−E2)其中, η = K 11 − 2 K 12 + K 22 = ∣ ∣ Φ ( x 1 ) − Φ ( x 2 ) ∣ ∣ 2 \eta=K_{11}-2K_{12}+K_{22}=||\Phi(x_1)-\Phi(x_2)||^2 η=K11−2K12+K22=∣∣Φ(x1)−Φ(x2)∣∣2
eta = 2.0 * dataMatrix[i, :]*dataMatrix[j, :].T - dataMatrix[i, :]*dataMatrix[i, :].T - dataMatrix[j, :]*dataMatrix[j, :].T
if eta >= 0:
print("eta>=0")
continue
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
然后对 a j n e w , u n c a_j^{new,unc} ajnew,unc进行剪辑:
a j n e w = H , a j n e w , u n c > H a_j^{new}=H,a_j^{new,unc} \ > H\\ ajnew=H,ajnew,unc >H
a j n e w = a j n e w , u n c , L < = a j n e w , u n c < = H a_j^{new}=a_j^{new,unc}, L<=a_j^{new,unc} \ <= H\\ ajnew=ajnew,unc,L<=ajnew,unc <=H
a j n e w = L , a j n e w , u n c < L a_j^{new}=L,a_j^{new,unc} \ < L\\ ajnew=L,ajnew,unc <L
最后可由 a j n e w a_j^{new} ajnew求得 a i n e w a_i^{new} ainew: a i n e w = a 1 o l d + y i ∗ y j ( a j o l d − a j n e w ) a_i^{new}=a_1^{old}+y_i*y_j(a_j^{old}-a_j^{new}) ainew=a1old+yi∗yj(ajold−ajnew)
alphas[j] = clipAlpha(alphas[j], H, L)
def clipAlpha(aj, H, L):
"""clipAlpha(调整aj的值,使aj处于 L<=aj<=H)
Args:
aj 目标值
H 最大值
L 最小值
Returns:
aj 目标值
"""
if aj > H:
aj = H
if L > aj:
aj = L
return aj
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
在每次完成两个变量的优化后,都要重新计算阈值 b b b,当 0 < a 1 n e w < C 0<a_1^{new}<C 0<a1new<C时,由KKT条件可知: Σ i N a i ∗ y i ∗ K i 1 + b = y 1 \Sigma_i^Na_i*y_i*K_{i1}+b=y1 ΣiNai∗yi∗Ki1+b=y1于是, b 1 n e w = y 1 − Σ i = 3 N a i ∗ y i ∗ K i 1 − a 1 n e w ∗ y 1 ∗ k 11 − a 2 n e w ∗ y 2 ∗ K 21 b_1^{new}=y_1-\Sigma_{i=3}^Na_i*y_i*K_{i1}-a_1^{new}*y_1*k_{11}-a_2^{new}*y_2*K_{21} b1new=y1−Σi=3Nai∗yi∗Ki1−a1new∗y1∗k11−a2new∗y2∗K21由 E i E_i Ei的定义有 E 1 = Σ i = 3 N ∗ a i ∗ y i ∗ k i 1 + a 1 o l d ∗ y 1 ∗ K 11 + a 2 o l d ∗ y 2 ∗ K 21 + b o l d − y 1 E_1=\Sigma_{i=3}^N*a_i*yi*k_{i1}+a_1^{old}*y1*K_{11}+a_2^{old}*y_2*K_{21}+b^{old}-y1 E1=Σi=3N∗ai∗yi∗ki1+a1old∗y1∗K11+a2old∗y2∗K21+bold−y1整理可得: b 1 n e w = − E 1 − ( a 2 n e w − a 2 o l d ) ∗ y 1 ∗ K 12 − ( a 2 n e w − a 2 o l d ) ∗ y 2 ∗ k 21 + b o l d b_1^{new}=-E_1-(a_2^{new}-a_2^{old})*y_1*K_{12}-(a_2^{new}-a_2^{old})*y_2*k_{21}+b_{old} b1new=−E1−(a2new−a2old)∗y1∗K12−(a2new−a2old)∗y2∗k21+bold,同理,可得 b 2 b_2 b2
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[i, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i, :]*dataMatrix[j, :].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[j, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j, :]*dataMatrix[j, :].T
如果 a j n e w a_j^{new} ajnew和 a i n e w a_i^{new} ainew同时满足条件 0 < a i n e w < C , i = 1 , 2 0<a_i^{new}<C,i=1,2 0<ainew<C,i=1,2,那么 b i n e w = b j n e m b_i^{new}=b_j^{nem} binew=bjnem,如果他们的值是 0 0 0或者 C C C,那么 b i n e w b_i^{new} binew和 b j n e w b_j^{new} bjnew都是符合KKT条件的阈值,此时选择他们的中点作为 b n e w b^{new} bnew。
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2)/2.0