Python笔记(不定期更新)
用print打印多个字符串可用逗号相连,输出中遇到逗号则自动在字符串之间添一个空格;若不想在两个字符串中间添空格,则应该加号连接字符串。不只是print里面可以进行字符串相加,字符串相加即可合并成一个字符串。
print ('1 + 2 =', '2 + 1') #是输出了两个字符串 print ('1 + 2 ='+ '2 + 1') #实际上是输出了一个字符串
input
不是把元素写在input函数后面的括号里,按下回车键之后系统展示给我们括号里的内容,等待我们输入内容。
在input函数后面使用.split()方法,可以连续输入一组数据,数据之间用空格分开,并返回一个列表。
input_str input_list1 = input('连续循环输入(元素间用空格分隔):').split() input_list2 = input('连续循环输入(元素间用逗号加空格分隔):').split(', ')
变量
变量名可以用大小写字母(敏感),或者数字,或者下划线组合而成,但不能以数字打头。Python中不用声明变量的类型,可以给变量赋类型不同的值,但后写入的可以冲掉之前的数据。这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。
_a10 = 'HAPPINESS' a_10 = ['SWEETNESS'] a_10 = 'FULFILLMENT' A_10 = 'SATISFICTION' A_10 = 1998 A_10 = True
赋值
mylist = [1, 2, 3, 4] list1 = [0, 0, 0] list2 = [0, 0, 0] num1 = num2 = num3 = 4 print(id(num1), id(num2), id(num3)) list1[0] = list2[0] = mylist[2] print(id(list1[0]), id(list2[0])) list3 = list4 = mylist[:] print(id(list3[0]), id(list4[0])) list5 = list6 = mylist print(id(list5[0]), id(list6[0])) runfile('D:/MyProjects/Python/TutorialExamples/part30.py', wdir='D:/MyProjects/Python/TutorialExamples') 1577545280 1577545280 1577545280 1577545248 1577545248 1577545184 1577545184 1577545184 1577545184
可以看出等号左右并列的变量名指向的内存地址都是相同。但是如果改变num1(给num1重新赋值如:num1= 7)不会对num2,num3产生影响。如果改变mylist[2]的话,比如mylist[2]=9,list1[0],list2[0]的值,以及list3,list4的值都不会发生改变。但list5,list6中的第三个元素会发生改变,均变为9。
如果改变给list3重新赋值,如list3[2]=3,那么list4[2]也会变为3。列表索引的特性就很类似于直接给变量名赋值!
这种奇怪的现象与python特殊的高级数据结构list(当然也有numpy中的array)内存与变量名的关系有关。

如果我们对变量名进行连等赋值:
num1 = num2 = num3 = 4
在执行上面的命令时python的解释器做了两件事:
在内存中创建了一个int型数据:4
创建了num1,num2,num3三个变量名,并把它统统指向上面创建的int型数据:4
此时我们进行如下操作:
num1 = 5 num2 Out[26]: 4 num3 Out[27]: 4
同样地,python解释器也做了两件事:
在内存中创建了一个int型数据:5
将变量名num1指向上面创建的int型数据:5,而其他两个变量名num2,num3仍然指向4
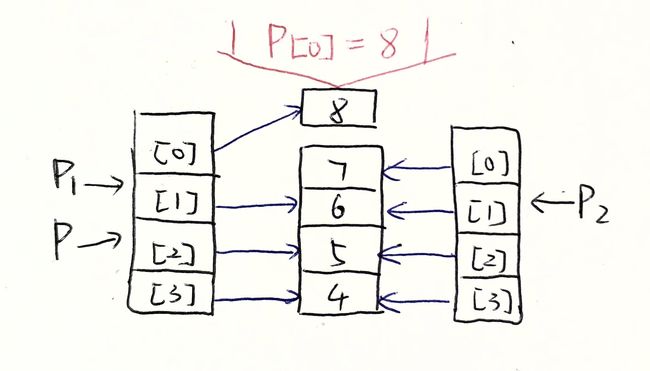
对于列表这种复杂数据结构,python存放其中元素使用了指针:
p = [7, 6, 5, 4] p1 = p p2 = p[:]
这个时候我们要将p[0],p[1],p[2],p[3],看作变量名,他们指向内存地址中的每个数据。p1直接由p这个变量名赋值得到,所以p和p1都指向一个地址,这个地址里装的是指针数组,指针数组中的每一个索引指向每个块内存。
而p2是p切片得到的,它的指针数组直接指向内存地址所对应的数据。也就是说为p2创建了新的指针数组。
那么此时更改p[0]的值,比如:
p[0] = 8 p1 Out[30]: [8, 6, 5, 4] p2 Out[31]: [7, 6, 5, 4]
可以看出,因为p1的指针数组和p的指针数组相同,所以当p[0]指向新开辟的内存,p1[0](其实就是p[0])也指向了新的内存。而p2只想最初的内存地址并没有发生改变。
那么如果对列表p重新赋一个列表,p1会怎么变化呢?
p = [1, 2, 3, 4] p1 Out[33]: [8, 6, 5, 4]
并没有发生变化!因为此时p被赋以一个新的指针数组的地址,p1仍然指向原来的指针数组!
我们只需要记住,对基本的数据结构,int,float,str连用等号赋值没有任何问题。另外list[5]=0这种列表索引类似于直接给变量名赋值。list的切片赋值等于浅拷贝!!!
运算符
下表列出了从最高优先级到最低优先级的所有运算符:
| 序号 | 运算符 | 描述 |
|---|---|---|
| 1 | ** |
指数(次幂)运算 |
| 2 | ~ + - |
补码,一元加减(最后两个的方法名称是+@和-@) |
| 3 | * / % // |
乘法,除法,模数和地板除 |
| 4 | + - |
|
| 5 | >> << |
向右和向左位移 |
| 6 | & |
按位与 |
| 7 | ^ | |
按位异或和常规的“OR” |
| 8 | <= < > >= |
比较运算符 |
| 9 | <> == != |
等于运算符 |
| 10 | = %= /= //= -= += *=``**= |
赋值运算符 |
| 11 | is is not |
身份运算符 |
| 12 | in not in |
成员运算符 |
| 13 | not or and |
逻辑运算符 |
Python中的乘法运算结果默认是整形格式;
is 比较的是两个实例对象是不是完全相同,它们是不是同一个对象,占用的内存地址是否相同。莱布尼茨说过:“世界上没有两片完全相同的叶子”,这个is正是这样的比较,比较是不是同一片叶子(即比较的id是否相同,这id类似于人的身份证标识)。
== 比较的是两个对象的内容是否相等,即内存地址可以不一样,内容一样就可以了。这里比较的并非是同一片叶子,可能叶子的种类或者脉络相同就可以了。默认会调用对象的 eq()方法。
Python中的除法运算结果默认是浮点数格式,即使是两个整数恰好整除,结果也是浮点数;
地板除//,两个整数的除法仍然是整数,但若地板除//的参数含有浮点数,结果也为浮点数。
另外Python中整数和浮点数均没有大小限制。
round(float, n)函数,用于确定精确位数。精确到小数点后n位,n<0时精确到小数点前。
print(9 / 3) print(10 / 3) print(10 // 3) print(10. // 3) print(10 % 3) round(1234.5678, -2) #输出'1200.0' round(1234.5678, 2) #输出'1234.57'
二,数据结构
数据类型与数据结构
在python中的数据类型包括:bool、int、long、float、str、set、list、tuple、dict等等。我们可以大致将这些数据类型归类为简单数据类型和复杂的数据结构。
在Python中常用的只有集合、序列和映射三种结构。
| 数据结构 | 基本数据类型 |
|---|---|
| 集合(set) | int |
| 序列(list,str,tuple) | bool |
| 映射(dict) | long |
| 层次结构 | float |
| 树形结构 | str |
| 图结构 | ... |
str字符串
str是iterable数据,可用for循环遍历。
多个字符串之间可用加号连接,得到一个字符串(这点与list相同)。
mystr = 'abcdefghijklnopqrstuvwxyz' substr= mystr[2] + mystr[0] + mystr[16] #输出单词'car' for char in mystr: print char
常用操作:
float函数,可将字符串(仅包含浮点数字,如‘ 123.456 ’)转化成浮点数。
int函数,可将字符串(仅包含数字,如‘ 123456 ’)转化成整数。
replace('former', 'later', n)函数,可以进行字符串中的字符替换。可将字符串中的'former'全部替换成 'later',并且最多只能替换n次。
float('1234.5678') int('12345678') str(round(1234.5678, -2)) #输出'1200.0' str(round(1234.5678, 2)) #输出'1234.57' data = open('io test.txt','r') for line in data.readlines(): print(line.replace('the', 'THE', 2)) data.close()
字符串格式化输出:
print ('尊敬的%s先生,您%d 月的话费是 %f 元' %('刘森', 2, 45.3)) >>>尊敬的刘森先生,您2 月的话费是 45.300000 元
格式化规则:
%% 百分号标记 #就是输出一个% %s 字符串 %d 有符号整数(十进制) %u 无符号整数(十进制) %x 无符号整数(十六进制) %e 浮点数字(科学计数法) %f 浮点数字(用小数点符号)
正则表达式
正则表达式用于匹配,替换符合一定格式的字符串。
^ 匹配输入字符串的开始位置。 $ 匹配输入字符串的结束位置。 * 匹配子表达式零次或多次。 + 匹配子表达式一次或多次。 ? 匹配子表达式零次或一次,防止贪心。 \s 匹配任何空白字符,包括空格、制表符、换页符等等。。 \S 匹配任何非空白字符。 \w 匹配包括下划线,a-z,A-Z,0-9在内的所有字符(python变量名) (pattern) 匹配pattern 并获取这一匹配。
举几个例子:
匹配中文字符的正则表达式: [\u4e00-\u9fa5] 匹配Email地址的正则表达式: \w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 匹配信用卡卡号校验,检查16位四组格式的,以空个或-分开的卡号,或者连在一起的: ^(\d{4}[- ]){3}\d{4}|\d{16}$ 匹配任何大写或小写字母组成,以逗号或空格分开的文本,空格的数量不限。 ^\s*[a-zA-Z,\s]+\s*$
split
split函数可谓是分词的好方法:
str1 = '123 ' str1.split() Out[94]: ['123'] str1.split(' ') Out[95]: ['123', '', '']
split里面不指定参数,则默认按空格分割,并且对空格是贪心的。若有多个空格,就按照尽可能多的空格切分。如果指定按一个空格切分' ',也可以按照一个空格切分。
字符串格式化:
title()函数,是将字符串型数据的首字母大写,其他的字符s变为小写。
upper()函数,是将字符串型数据的所以字母大写。
lower()函数,是将字符串中的所有字母小写。
str = list(['pUt', 'fiRSt', 'leTTers', 'iNTo', 'a', 'uPPer', 'fORm']) for i in str: print(i.title(), i.upper(), i.lower())
list列表
列表切片
欲得到第n~m个元素,range函数就要写成range(n-1,m)
L = ['白', '日', '依', '山', '尽', '黄', '河', '入', '海', '流'] print (L[5:-1]) #从索引为5的元素到倒数第二个元素 print (L[5:9]) #与上行代码等价 print (L[5:9]) #从索引为5的元素到最后一个元素 print (L[5:]) #与上行代码等价 print (L[-1]) #倒数第一个元素
增删索倒
list的元素也可以是一个list,从而构造多维列表。
通过list函数,可将range类型的序列转化为列表。
通过赋空值,来删除列表中的所有元素。
append方法,往list中追加元素(可以是list,str,dict,set等类型的数据)到末尾;
insert方法,把元素插入到指定的位置;
pop(i)方法,要删除指定位置的元素,其中i是待删除元素的索引。不指定参数,则默认删除末尾元素。
remove(Obj)方法,与pop按照索引删除相反,remove方法按照匹配来删除元素。(如果列表中有相同元素Obj,默认删除第一个Obj)pop和remove方法的相同之处是:删除元素之后,后面的元素依次向前移动补位。
del 关键字可以用来删除元素,与pop不同的是,pop只能删除单个元素。
而del list[m, n],可以删除一个区间范围内的元素(多个元素)。
index(Obj)方法,可以按匹配来获取元素所在位置。有一个返回值,表示索引。(如果列表中有相同元素Obj,默认返回第一个Obj的索引)
line.replace('the', 'THE', 2)
+加号用于合并两个列表
mylist = ['now', this', 'one', ['is']] mylist.append('list') mylist[3].insert(1, 'a') mylist.pop(2) del mylist[0:2] mylist.index(['is', 'a']) series = list(range(10, 2, -2)) mylist += ['really! ']
区分!
append方法可以向list中追加一个元素,比如:list,str,dict,set等类型的数据到末尾;
extend方法只接受一个列表作为参数,并将该参数的每个元素都追加到原有的列表中。
mylist = [3] myset = set([1, 22, 45, 22]) mylist.append(myset) mylist.extend([6, 9])
注意!
向一阶空列表中用append方法添加元素,第一个元素为第一次append进去的元素;
向高阶空列表中用append方法添加元素,第一个元素为空列表,之后的是依次append进去的元素。
l1 = [] l1.append([3]) l2 = [[]] l2.append(3)
常用函数
np.shape(list)方法,返回一个二维元组tuple:(m,n)来表示行数m和列数n;
np.size(list)方法,返回一个整型数据,表示该列表里的所有元素的总个数。
len函数,返回列表中元素的总个数。
np.tile(X, (n, m)) 函数,将列表X在行方向上重复n次,在列方向上重复m次。返回的是一个numpy数组。
students_sorted = sorted(students, key=operator.itemgetter(0,1), reverse=True) students = [[12, 6, 14], [15, 3, 6], [14, 9, 2], [56, 2, 6], [14, 2, 45], [14, 4, 4]] sh = np.shape(students) row = dataSet.shape[0] #行数 column = dataSet.shape[1] #列数 si = np.size(students) ti = np.tile([2,1],(4,3)) \>>>[[2 1 2 1 2 1] [2 1 2 1 2 1] [2 1 2 1 2 1] [2 1 2 1 2 1]] #numpy数组的与多维列表的区别是:不用逗号分隔元素
列表排序
sort方法,对列表进行原地排序,直接修改列表内容,不返回任何内容。原来列表中的次序丢失!
sorted(Obj)函数,给Iterable型数据作为参数即可排序, 返回排序后的列表。sorted函数还可以给于key,和reverse两个参数!key接受被赋给一个函数,然后将列表中的每一个元素作为该函数的参数传入,然后按该函数的返回值进行排序!reversed=True,则逆序(从大到小)排列,reversed=False,则从小到大排列。
np.argsort方法,作用对象是一个数组,返回的还是一个数组!而且argsort是numpy里的方法,不能用于列表!返回的是从小到大排列情况下,各元素在原数组中的索引值。当然,np.argsort也不能用于列表,只能作用于numpy数组!
reversed()函数,可以将列表逆序!
import operator series = [[42, 52], [.2, 56., 6], [0, 33, 2, 44], [78, 33, 74, 84, 96], [22, 33]] series.sort(key=len, reverse=False) #按照元素的长度从小到大排序 series_sorted = sorted(series, key=operator.itemgetter(1, 0), reverse=True) #先按索引为1的元素排序,再按索引为0的元素排序 #func=operator.itemgetter(1, 0)就是定义了函数func,获取该对象第1和0个值 myseries = reversed(list(range(10))) #range生成0-10的序列,列表化之后逆序
tuple元组
tuple只能用下标进行索引!下列方法它都没有:
不能向 tuple 增加元素,没有 append 、extend 、insert 等方法。
不能从 tuple 删除元素,没有 remove 或 pop 方法。
不能在 tuple 中查找元素,没有 index 方法(index是查找而不是索引)。
tpl = ('A', 'B', [1, 2]) tpl = tuple(['A', 'B', [1, 2]]) #将list转化为tuple型数据 list = list( ('A', 'B', [1, 2]) ) #将tuple转化为list型数据
tuple不可改变指的是不可以改变它的子元素,但它子元素里面的内容还是可以改变的,例如:
tpl = ('A', [1, 2, 3], {'Louis':20, 'jessie':30}) tpl[1].pop() #删除列表中的最后一个元素 tpl[2]['Louis'] = 19 #修改字典中louis对一个的value print(tpl) ('A', 'B', 'C', [1, 2]) #其中的数据的确发生了改变
我们用他们的内存地址看一下变化情况:
tpl = ('A', [1, 2, 3], {'Louis':20, 'jessie':30}) id(tpl[1]) Out[23]: 2537301699080 tpl[1].pop() id(tpl[1]) Out[25]: 2537301699080
dict字典
dict类型的数据,每对元素包括一个key和一个value,key是Integer或string类型,value 是任意类型。
生成方式:
用大括号括起来,key和value之间都加引号,而且两者用冒号相连;
dict函数,key不用加引号,而且与value之间用等号相连;
d1 = {'LAUSen':'帅比', 'WANGMingze' : '鸹貔'} d2 = dict(LAUSen = '帅比',WANGMingze = '鸹貔')
元素处理:
重新赋值以更改value;
赋给新key以值,可以添加新的键值对;
pop方法,用来删除键值对,用key作为参数;
d2['WANGMingze'] = '老公' d2['XIEXinmei'] = '老妈' d2 = dict(cc = 3) d1.pop('WANGMingze')
索引方式:
按key找value;
get(key, ‘No pair found’) 方法索引,若果没有找到则返回缺省值;
d2.get('XIEXinmei',0) d2['WANGMingze']
获取key,value:
d.keys() 返回字典的key的列表,是'dict_values'类型数据,且此类型数据不可迭代。
d.values() 返回字典的value的列表,类型同上。
d.items() 返回字典键的列表,类型同上。(每对键值组成一个tuple)
d = {'Henan' : 1, 'Zhejiang' : 2, 'Jiangxi' : 3, 'Guagdong' : 4} key_dict = d.keys() value_set = set(d.values()) item_list = list(d.items()) for items in d.items(): #虽然d.items() 的返回值不支持索引,但它支持for循环 print(items) #打印出的是n个tuple for key, value in d.items(): print('key='+key, 'value='+value)
按照value排序:
import operator id2author_sorted = sorted(id2author.items(), key=operator.itemgetter(1))
operator.itemgetter(1)是用来获取每一个字典元素中的value。
set集合
set无序,不重复,因此不能用下标来索引;对于集合可用.remove和.add方法进行处理,其中参数都是要删去的元素,而不是索引!
s = set([1, 2, 2, 2, 3, 6]) s.remove(6) s.add(7)
set的一大性质是内部储存的数据不重复,我们可以利用这一点来做到列表元素去重。
list1 = ['Jessie J', 'Donald Trump', 'Jessie J', 'Jessie J', 'Donald Trump','Lau Sen', 'Donald Trump'] list(set(list1)) Out[5]: ['Lau Sen', 'Jessie J', 'Donald Trump'] sorted(list(set(list1))) Out[6]: ['Donald Trump', 'Jessie J', 'Lau Sen']
想要有set的特性又不想被修改,可以用frozenset:
s = frozenset([1, 2, 2, 2, 3, 6]) type(s) Out[33]: <class 'frozenset'>
array数组
其实list,tuple,dict都是数组类型!list是动态数组,可以后期增删修改元素;tuple是固定数组,内容一旦确定不能修改;dict属于hash数组。
多维数组即为矩阵!多维数组可以经np.array函数,由多维列表得到。
生成数组:
np.array函数,可以用来进行列表转数组,给与一个list,或tuple作为参数即可。
np.arange函数,可以用来生成一个numpy.ndarray类型的数组(注意是arange,不是arrange!),用法和range函数类似。
exmp = [[100, 10, 1], [.1, .01, .001], [0, 0, 0]] exmp_array = np.array(exmp) myarray = numpy.arange(10, -1, -1) #生成一个从10到0的一维numpy数组
Iterable & Iterator
可迭代(Iterable):能直接用做for循环包括集合类数据类型:list, tuple, dict, set, str; 和生成器
迭代器(Iterator):可以被next函数调用并不断返回下一个值。所有的生成器都是Iterator,但list,dict,str不是;不过经过 iter 函数处理之后,就可以把list,dict,str转换成迭代器。
isinstance(C, Iterator)函数,用来判断某变量是否为Iterator。
举几个常见的例子:
for items in d.items(): print(items) for key, value in d.items(): print(key) generator_exmp1 = [i**2 for i in range(10, 16)] #生成一个列表 generator_exmp2 = (i**2 for i in range(10, 16)) #生成器 for n in generator_exmp2 print(n) for idx, value in enumerate(['A', 'B', 'C']): print(idx, value)
举一个例子,用生成器打印出杨辉三角:
def YangHuitri(): a=[1] n=1 yield(a) while n<11: a.append(1) yield(a) count=len(a)-1 for i in a: if count>0: a[count]=a[count-1]+a[count] count-=1 n+=1 s = YangHuitri() for i in s: print(i)