Construct a Seq2Seq Model with Attention Mechanism
Construct a Seq2Seq Model with Attention Mechanism
1. 创建一个seq2seq类
class Seq2seq(object):
def __init__(self, config):
self.attribute = config["attribute"]
pass
对于seq2seq模型,此处的主要参数有:
- size of vocabulary
- size of embedding matrix (for decoder, a random matrix)
- number of neurons in hidden layer
- number of layers
- learning rate
- beam size
- batch size
class Seq2seq(object):
def __init__(self, config):
pass
# set placeholders
self.x = tf.placeholder(tf.int32, [None, article_max_len])
pass
此处需要设置的placeholder主要有:
- encoder端的输入序列x
- decoder端的输入序列decoder_x
- decoder端的目标序列decoder_y
- global_step计数器
2. 构建计算图:encoder
self.cell = tf.nn.rnn_cell.BasicLSTMCell
with tf.name_scope("encoder"):
# forward cell
fw_cells = [self.cell(self.num_hidden) for _ in range(self.num_layers)]
fw_cells = [rnn.DropoutWrapper(cell) for cell in fw_cells]
# backward cell
bw_cells = [self.cell(self.num_hidden) for _ in range(self.num_layers)]
bw_cells = [rnn.DropoutWrapper(cell) for cell in bw_cells]
encoder_outputs, encoder_state_fw, encoder_state_bw = tf.contrib.rnn.stack_bidirectional_dynamic_rnn(
fw_cells,
bw_cells,
self.encoder_embedded_input, # encoder端经过embedding的input sequence
sequence_length,
time_major=True,
dtype=tf.float32)
self.encoder_output = tf.concat(encoder_outputs, 2)
encoder_state_c = tf.concat((encoder_state_fw[0].c, encoder_state_bw[0].c), 1)
encoder_state_h = tf.concat((encoder_state_fw[0].h, encoder_state_bw[0].h), 1)
self.encoder_state = rnn.LSTMStateTuple(c=encoder_state_c, h=encoder_state_h)
程序中对前向和后向都设置了cells组成的layers,并且用rnn.DropWrapper设置dropout。其中rnn.DropoutWrapper是一个class,父类是RNNCell。使用Dropout防止过拟合。
函数tf.contrib.rnn.stack_bidirectional_dynamic_rnn的参数,cell_fw,cell_bw都需要是RNNCell类的实例。构建前向反向cell的时候用的是tf.nn.rnn_cell.BasicLSTMCell传入number of hidden layer作为参数。
关于函数的参数:
help(tf.contib.rnn.stack_bidirectional_dynamic_rnn)
...
inputs: The RNN inputs. this must be a tensor of shape: `[batch_size, max_time, ...]`, or a nested tuple of such elements.
...
time_major: The shape format of the inputs and outputs Tensors. If true, these Tensors must be shaped [max_time, batch_size, depth]. If false, these Tensors must be shaped [batch_size, max_time, depth].
time_major参数主要是保证输入输出tensor的形状相同。此处time_major设置为true,则对于输入的embedded inputs要进行前两个维度的转置(利用tf.transpose函数),转变为:[max_time, batch_size, layers_output]。
inputs的axis1的维度即为max_time,此处inputs即为进行了embedding的序列。
函数的返回值如下:
Returns:
A tuple (outputs, output_state_fw, output_state_bw) where:
outputs: Output `Tensor` shaped: `[batch_size, max_time, layers_output]`. Where layers_output are depth-concatenated forward and backward outputs.
output_states_fw is the final states, one tensor per layer, of the forward rnn.
output_states_bw is the final states, one tensor per layer, of the backward rnn.
着重看outputs,是一个三维的tensor,前两个维度取决于inputs的形状,第三个维度是前向和反向输出的concatenation。后两个结果分别是前向rnn和反向rnn的最终状态,每一层对应一个tensor。
此处取output_state_fw[0].c即是获取前向rnn最后一层的的最终状态对应的cell state,output_state_bw[0].h获取反向rnn最后一层的最终状态对应的hiddent state。
将前向、反向rnn最后一层的cell state和hidden state分别进行concatenation,传入函数rnn.LSTMStateTuple得到encoder_state。
如下图所示,图中是双向RNN,每一层包含睡了前向和反向传播的节点(cell),总层数是2层。最后将forward cell和backward cell的状态进行concatenate,得到输出y。利用tf.contrib.rnn.stack_bidirectional_dynamic_rnn得到如下实现:
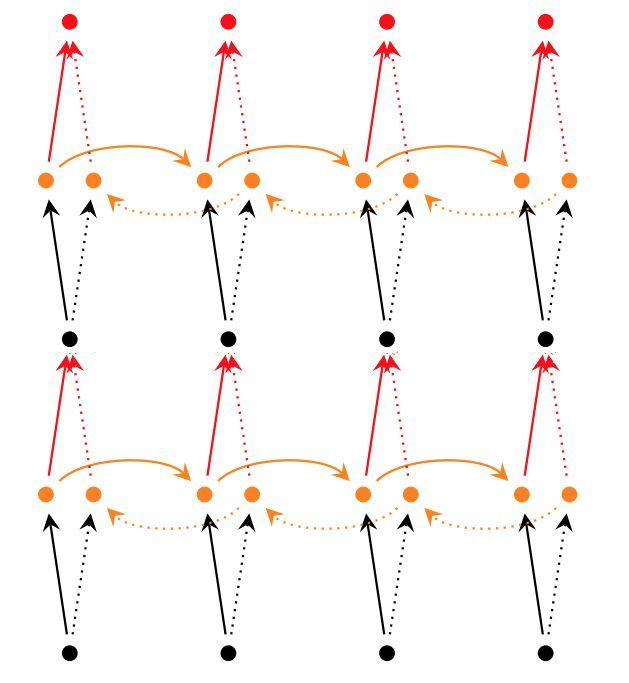
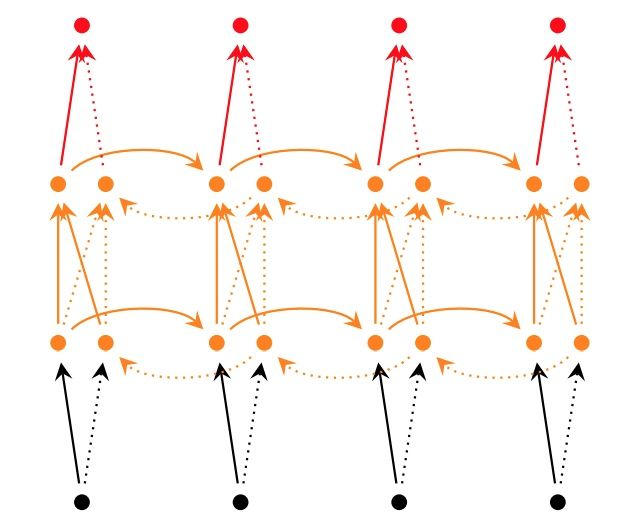
除此之外,双向RNN还可以用tf.nn.bidirectional_dynamic_rnn来进行如下实现:
3. 构建计算图:decoder
with tf.name_scope("decoder"), tf.variable_scope("decoder") as decoder_scope:
# 因为encoder是双向rnn,输出是forward,backward outputs的concatenation。所以decoder每层神经元的个数要是encoder端的两倍
self.cell = tf.nn.rnn_cell.BasicLSTMCell
decoder_cell = self.cell(self.num_hidden * 2)
# 训练过程要设置超参数forward_only为False
if not forward_only:
# shape of encoder output: [batch_size, max_time, layers_output]
# turn it into: [max_time, batch_size, layers_output]
attention_states = tf.transpose(self.encoder_output, [1, 0, 2])
# apply attention mechanism in decoding process
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(
self.num_hidden * 2,
attention_states,
memory_sequence_length=self.X_len,
normalize=True)
# attach attention to decoder cells
decoder_cell = tf.contrib.seq2seq.AttentionWrapper(
decoder_cell,
attention_mechanism,
attention_layer_size=self.num_hidden * 2)
# initialize decoder cell state
initial_state = decoder_cell.zero_state(dtype=tf.float32, batch_size=self.batch_size)
initial_state = initial_state.clone(cell_state=self.encoder_state)
# process the input of decoder in every decode time step
helper = tf.contrib.seq2seq.TrainingHelper(self.decoder_emb_inp, self.decoder_len, time_major=True)
# construct/ define the decoder
decoder = tf.contrib.seq2seq.BasicDecoder(decoder_cell, helper, initial_state)
# execute the decoder and generate the decoder outputs
outputs, _, _ = tf.contrib.seq2seq.dynamic_decode(
decoder,
output_time_major=True,
scope=decoder_scope
)
self.decoder_output = outputs.rnn_output # this outputs should be a instance of a specific class
# projection
self.logits = tf.transpose(
self.projection_layer(self.decoder_output),
perm=[1, 0, 2]
)
# padding with zeros
self.logits_reshape = tf.concat(
[self.logits, tf.zeros([self.batch_size, summary_max_len - tf.shape(self.logits)[1], self.vocabulary_size])], axis=1)
else:
pass
在decoder端加入了attention机制,用的是BahdanauAttention。BahdanauAttention(_BaseAttentionMechanism)是一个类,其init函数如下:
__init__(self, num_units, memory, memory_sequence_length=None, normalize=False, probability_fn=None, score_mask_value=None, dtype=None, name='BahdanauAttention')
要传入的参数包括:
- decoder每层神经元的个数
- attention states: 此处应该传入RNN encoder的outputs,形状应为[batch_size, max_time, …]
- 输入序列的长度:因为是Bahdanau Attention,所以此处需要计算current decode time step对于输入序列所赋予的attention
- 正则化:一个布尔值
其次,AttentionWrapper也是一个类,参考一下其init函数:
__init__(self, cell, attention_mechanism, attention_layer_size=None, alignment_history=False, cell_input_fn=None, output_attention=True, initial_cell_state=None, name=None, attention_layer=None)
需要传入的参数:
- cell: 是RNNCell的实例,此处就是decoder cells
- attention_mechanism: 是类AttentionMechanism的一个实例,或实例列表;此处attention_mechanism是BahdanauAttention的一个实例
- attention_layer_size:是针对于encoder output来说的,双向rnn则取encoder一层神经元个数的二倍,即size of concatenated encoder output
函数tf.nn.rnn_cell.BasicLSTMCell.zero_state用于cell状态的初始化,返回的是一个形状为[batch_size, state_size]的全0 tenosr。接下来的initial_state.clone(cell_state=self.encoder_state) 则是对于decoder_cell用emcoder final state(as a LSTMTuple)进行初始化。
类似地,TrainingHelper也是一个类,对于训练过程起辅助作用,只读取inputs,返回的sampled ids是RNN output logits经过argmax的采样结果。init函数如下所示:
help(tf.contrib.seq2seq.TrainingHelper)
__init__(self, inputs, sequence_length, time_major=False, name=None)
需要传入的参数:
- inputs:输入的tensor,此处是decoder的embedded input
- sequence_length: decoder要产生的序列长度(即decoder的长度是一定的,但decoder产生的摘要从第一个处截断可以保证摘要的长度多样),此处并非decoder cells的个数
- time_major:为True,输入tensor的形状是max_time为先;为False,输入tensor的形状是batch_size为先,即batch_major
利用tf.contrib.seq2seq.dynamic_decode得到decoder的输出之后,进行了projection,其作用是将decoder outputs从向量空间投影到词项空间,此处projection layer的定义就是一个没有偏置项的dense layer全连接层:projection_layer = tf.layers.Dense(self.vocabulary_size, use_bias=False),只包含一个投影矩阵。
最后用0为projection的logits进行padding。
4. 解码输出:beam search
...
# 如果forward_only==True;则进行beam search
else:
# tile the outputs, final states and the sequence length of hte encoder
tiled_encoder_output = tf.contrib.seq2seq.tile_batch(
tf.transpose(self.encoder_output,
perm=[1, 0, 2]),
multiplier=self.beam_width)
tiled_encoder_final_state = tf.contrib.seq2seq.tile_batch(
self.encoder_state,
multiplier=self.beam_width
)
tiled_seq_len = tf.contrib.seq2seq.tile_batch(
self.X_len,
multiplier=self.beam_width
)
# apply the bahdanau attention in beam search in decoding process
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(
self.num_hidden * 2,
tiled_encoder_output,
memory_sequence_length=tiled_seq_len,
normalize=True
)
decoder_cell = tf.contrib.seq2seq.AttentionWrapper(
decoder_cell,
attention_mechanism,
attention_layer_size=self.num_hidden * 2
)
# initialize the decoder cells with tiled encoder final states
initial_state = decoder_cell.zero_state(
dtype=tf.float32,
batch_size=self.batch_size * self.beam_width
)
initial_state = initial_state.clone(
cell_state=tiled_encoder_final_state)
# 此处用已经集成好的接口:BeamSearchDecoder
decoder = tf.contrib.seq2seq.BeamSearchDecoder(
cell=decoder_cell,
embedding=self.embeddings,
start_tokens=tf.fill([self.batch_size], tf.constant(2)),
end_token=tf.constant(3),
initial_state=initial_state,
beam_width=self.beam_width,
output_layer=self.projection_layer
)
outputs, _, _ = tf.contrib.seq2seq.dynamic_decode(
decoder, output_time_major=True,
maximum_iterations=summary_max_len,
scope=decoder_scope
)
self.prediction = tf.transpose(
outputs.predicted_ids,
perm=[1, 2, 0]
)
这一个else 语句进行的是beam search。第一个函数tf.cntrib.seq2seq.tile_batch(tensor, multiplier)第一个参数是batch major的tensor,第二个参数multiplier是一个int scalar,此处应为beam_width。作用是将encoder outputs复制beam_width份,进行beam search。
将encoder端的outputs, final states进行tile之后,再将bahdanau attention应用到decoder端;并以此构建beam search decoder。此处实例化decoder应用到的是类tf.contrib.seq2seq.BeamSearchDecoder。help得到下面帮助信息:
__init__(self, cell, embedding, start_tokens, end_token, initial_state, beam_width, output_layer=None, length_penalty_weight=0.0, coverage_penalty_weight=0.0, reorder_tensor_arrays=True)
| Initialize the BeamSearchDecoder.
|
| ...
| An example:
|
| tiled_encoder_outputs = tf.contrib.seq2seq.tile_batch(
| encoder_outputs, multiplier=beam_width)
| tiled_encoder_final_state = tf.contrib.seq2seq.tile_batch(
| encoder_final_state, multiplier=beam_width)
| tiled_sequence_length = tf.contrib.seq2seq.tile_batch(
| sequence_length, multiplier=beam_width)
| attention_mechanism = MyFavoriteAttentionMechanism(
| num_units=attention_depth,
| memory=tiled_inputs,
| memory_sequence_length=tiled_sequence_length)
| attention_cell = AttentionWrapper(cell, attention_mechanism, ...)
| decoder_initial_state = attention_cell.zero_state(
| dtype, batch_size=true_batch_size * beam_width)
| decoder_initial_state = decoder_initial_state.clone(
| cell_state=tiled_encoder_final_state)
|
...
这也是一个比较重要的类,看init函数分析需要传入的参数:
- cell:当然是decoder cells
- embedding:forward_only=False时用的是glove embedding;但此处forward_only=True,用的是服从均匀分布的random embedding matrix
- strat_token:形状为[batch_size]的vector,标志着decoding process开始的token
- end_token:一个scalar,对应着为解码结束的标志位在vocabulary中对应的id
- initial_state:此处使用tiled encoder final states
- beam_with
- output_layer:tf.layers.Layer类的一个实例,比如可选用tf.layer.Dense,此处是projection layer
- length_penalty_weight:a float scalar,来惩罚过长的摘要句
参考官方给出的例子:
先对encoder outputs,encoder final states,sequence leangth进行tile;设置attention mechanism,并且用attention wrapper函数将attention mechanism应用到decoder cell上 ;然后利用tiled encoder final state对decoder cell进行初始化。
最后利用tf.contrib,seq2seq.dynamic_decode函数在构建好的beam search decoder上执行beam search,看一下函数的输入输出:
dynamic_decode(decoder, output_time_major=False, impute_finished=False, maximum_iterations=None, parallel_iterations=32, swap_memory=False, scope=None)
需要传入的参数:
- decoder:一个Decoder类的实例,此处为BeamSearchDecoder的一个实例
- output_time_major:输出结果的维度第一维对应max_time;默认为False,即batch_major
- maximum_iterations:int32 scalar,允许的最大decoding steps,默认为None,即不设限制,解码直至end token出现,终止解码过程;用来限制summary长度
返回的结果:final_outputs,final_state,final_sequence_lengths。
5. 构造计算图:loss function和prediction
with tf.name_scope("loss"):
# 只有在forward_only=False的条件下实例化seq2seq model才能够计算loss
if not forward_only:
# calculate thecross entropy loss, and mask it -- only need summaries shorter than the summaries maximal
crossent = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=self.logits_reshape,
labels=self.decoder_target
)
weights = tf.sequence_mask(
self.decoder_len,
summary_max_len,
dtype=tf.float32)
self.loss = tf.reduce_sum(crossent * weights / tf.to_float(self.batch_size))
# apply gradients to trainable variables, and incorporate the gradient clipping
params = tf.trainable_variables()
gradients = tf.gradients(self.loss, params)
clipped_gradients, _ = tf.clip_by_global_norm(gradients, 5.0)
# set optimizer
optimizer = tf.train.AdamOptimizer(self.learning_rate)
# the training operation
self.update = optimizer.apply_gradients(
zip(clipped_gradients, params),
global_step=self.global_step)
此处用的是交叉熵作为目标函数:tf.nn.sparse_softmax_cross_entropy_with_logits,它与tf.nn.softmax_cross_entropy_with_logits的不同之处在于,前者输入的label是代表样本所在类别的scalar列表,而后者必须输入labels的one-hot稀疏表示。
为了只取前summary_max_len个元素进行交叉熵损失的计算,需要对其他位置进行mask;此处利用函数tf.sequence_mask与交叉熵结果进行点乘*,再除以batch_size,对结果进行求和,得到最终的loss。
利用loss获得gradients,设置optimizer,并利用函数tf.train.AdamOptimizer.apply_gradients对可训练变量进行优化,并为global step进行计数。
参考资料:
- https://applenob.github.io/tf_dynamic_seq2seq.html
- https://zhuanlan.zhihu.com/p/27769667
- https://blog.csdn.net/u012436149/article/details/52976413
- https://blog.csdn.net/u010960155/article/details/82853632