kafka1.0完全分布式搭建。
kafka是一个分布式的消息系统,可以用来作为消息分发使用,也可以配合storm和flume使用,将其作为这两二者之间的一个缓冲区域。在这里记录一下搭建的过程,前提时机器上装有java环境和zookeeper环境,这两个配置起来都比较简单,不再累述,在这里主要介绍如何配置安装kafka。
实验环境。
搭建环境:ubuntu16.04.
节点:node1、node2、node3。
下载文件及server.properties参数含义。
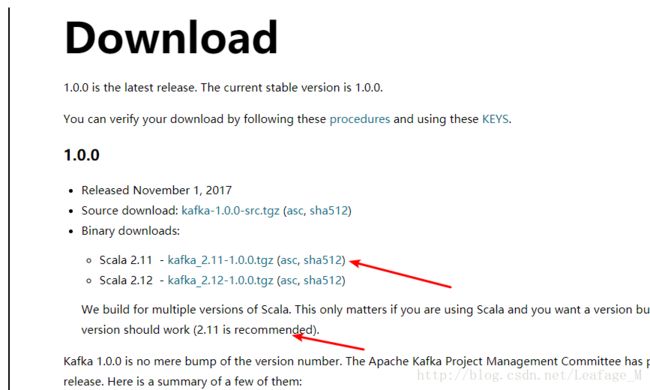
首先从官网下载kafka,http://kafka.apache.org/downloads,官网当前建议使用2.11的scala版本,那么就下载这个版本就好了。
下载完成之后将其上传到linux中,并将其解压。我们仅需要几个简单的配置即可搭建成功,主要配置的内容是congf目录下的server.properties。
下面是这文件中的参数含义:
############################# Server Basics #############################
broker.id=0:一个唯一的id标识,从0开始设置即可(node1设置为0,node2为1,node3为2)。
############################# Socket Server Settings #############################
listeners=PLAINTEXT://node1:9092:套接字监听的服务,主要用于消费者和生产者使用。
- num.network.threads=3:服务器用于接收来自网络的请求并向网络发送响应的线程数,也就是broker处理网络的线程数目。
- num.io.threads=8:服务器用于处理请求的线程数,可能包括磁盘I / O,也就是broker处理IO的线程数目。
- socket.send.buffer.bytes=102400:kafka发送数据缓冲区的大小,达到该值才会发送。
- socket.receive.buffer.bytes=102400:kafka接受数据缓冲区的小大,达到该值才会处理。
socket.request.max.bytes=104857600:kafka所能接受的数据最大值(小于java heap,java heap一般为内存的1/4)。
############################# Log Basics #############################
log.dirs=/tmp/kafka-logs:用来存储日志文件,用逗号隔开。
- num.partitions=1:每个主题的默认日志分区数量。更多的分区允许更多的消费,但也会导致更多的文件。
num.recovery.threads.per.data.dir=1:每个数据目录的线程数,用于启动时的日志恢复和关闭时的刷新。对于位于RAID阵列中的数据目录的安装,建议增加此值。
############################# Internal Topic Settings #############################
offsets.topic.replication.factor=1,transaction.state.log.replication.factor=1,transaction.state.log.min.isr=1:组元数据内部主题“__consumer_offsets”和“__transaction_state”的复制因子,对于除开发测试以外的任何其他内容,建议使用大于1的值以确保可用性,例如3。
############################# Log Flush Policy #############################
log.flush.interval.messages=10000:当消息大小10000条时就会强制刷新一次数据到磁盘中。
log.flush.interval.ms=1000:每1秒就会强制刷新数据到磁盘。
############################# Log Retention Policy #############################
log.retention.hours=168:消息最大持久化时间,按照hours计算,也就是七天。
- log.retention.bytes=1073741824:一种基于大小的保留策略,针对日志使用。当剩余段文件不小于这个值的时候,当前段就会从日志消息中删除。
- log.segment.bytes=1073741824:一个段文件的最大值,当达到这个指的时候会重新创建一个新的日志段。
log.retention.check.interval.ms=300000:每隔300秒检查一下段文件是否能被删除。
############################# Zookeeper #############################
zookeeper.connect=localhost:2181:设置zookeeper的ip和端口。
zookeeper.connection.timeout.ms=6000:连接zookeeper的超时时间。
###################### Group Coordinator Settings ######################
group.initial.rebalance.delay.ms=0:以下配置指定GroupCoordinator将延迟初始消费者重新平衡的时间(以毫秒为单位)。当新成员加入组时,rebalance将进一步延迟group.initial.rebalance.delay.ms的值,最大值为max.poll.interval.ms。这个的默认值是3秒。我们在此将其重写为0,因为它为开发和测试提供了更好的开箱即用体验。但是,在生产环境中,3秒的默认值更合适,因为这有助于避免在应用程序启动过程中出现不必要的且可能很昂贵的重新平衡。
修改配置。
知道了这个文件的参数含义之后,我们就可以进行配置了。只需要改动broker.id的指,第一个机器(node1)设置为0,其余的以此增加即可。
同时使用的时单独的zookeeper,所以需要修改zookeeper.connect,将其修改为zookeeper的集群地址。

修改完成之后将其保存,并分发到node2和node3的机器上,使用scp 命令即可。
scp -r kafka_2.11-1.0.0 node2:/opt/ # 使用scp将kafka拷贝到其余节点。
然后需要修改node2和node3中的broker.id即可,在这里将node2中的修改为1,node3修改为2。
然后修改用于监听消费者和生产者的端口,比如node1节点的修改为(node2节点就填写node2,node3填写node3即可):

启动kafka。
- 启动zookeeper。
首先将zookeeper打开,这是一个leader,其余两个为follower:

- 前台启动kafka。
然后将kafka全部启动(三个节点均需要单独启动):
使用kafka中的bin目录下的kafka-server-start.sh命令,然后添加config/server.properties作为参数,比如已经进入了bin目录中,可以使用如下命令进行启动:
kafka-server-start.sh ../config/server.properties # 前台启动命令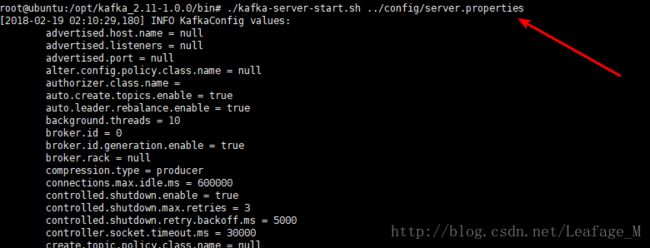
- 后台启动kafka。
但是上面这种方法是前台启动,启动完成之后就会停止而无法使用其他操作,所以我们需要后台启动,使用如下命令:
./kafka-server-start.sh ../config/server.properties 1>/dev/null 2>&1 & # 后台去启动命令
其他三台同样的启动即可。
测试kafka。
- 创建topic。
然后使用kafka创建一个topic,取名为kafkatest,分区为5,2个副本,在任意kafka节点创建均可(这里在node1中创建):
./kafka-topics.sh -zookeeper node1:2181,node2:2181,node3:2181 -topic kafkatest -replication-factor 2 -partitions 5 --create![]()
查看topic。
在任意节点中都可以进行查看(这里在node2中查看):
./kafka-topics.sh -zookeeper node1:2181,node2:2181,node3:2181 -list
启动消费者。
在任意节点均可启动一个消费者,从kafka中取消息,由于这里没有消息,所以会进入等待状态。
这里在node1中启动一个消费者,使用的是kafkatest这个topic:
./kafka-console-consumer.sh --bootstrap-server node1:9092 --topic kafkatest此时进入等待状态:
![]()
- 启动生产者。
在node2和node3中分别启动生产者:
./kafka-console-producer.sh --broker-list node2:9092 --topic kafkatest然后在其中输入内容并按下回车发送:

在node1的消费者中能够接收到消息:

- 消费者–from-beginning参数。
将node3生产者关闭,在node3中打开消费者并且添加–from-beginning 参数,该参数是直接从当前topic读取消息,而不是最新的消息,也就是说如果topic中又消息了直接将其读取。
./kafka-console-consumer.sh --bootstrap-server node3:9092 --from-beginning --topic kafkatest
可以从图中看到区别,如果不添加–from-beginning参数,则不会读取之前的内容,如果添加了则会直接读取之前的消息。
- 消费者和生产者的使用的服务器地址问题。
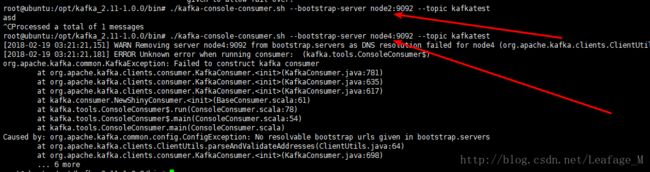
其中9092端口之前的ip并不一定是自身的ip地址,比如node1节点,在启动消费者的时候指定的是node1:9092,这只是要连接的服务器,使用node2或者node3均可,但是使用不存在的服务器则会出现如下错误:
比如在node1节点中,使用node2也可以,但是使用node4就不行了,因为node4不存在: