opencv学习笔记(二)手写数字识别(kNN)
一、kNN(分类)
已知类别:红色(三角形)标为0,蓝色(正方形)标为1,两类点共25个
待分类点:绿色(圆形),一个
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
# Feature set containing (x,y) values of 25 known/training data
trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32)
# Labels each one either Red or Blue with numbers 0 and 1
responses = np.random.randint(0, 2, (25, 1)).astype(np.float32)
# Take Red families and plot them
red = trainData[responses.ravel() == 0]
plt.scatter(red[:, 0], red[:, 1], 80, 'r', '^')
# Take Blue families and plot them
blue = trainData[responses.ravel() == 1]
plt.scatter(blue[:, 0], blue[:, 1], 80, 'b', 's')
newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32)
plt.scatter(newcomer[:, 0], newcomer[:, 1], 80, 'g', 'o')
knn = cv.ml.KNearest_create()
knn.train(trainData, cv.ml.ROW_SAMPLE, responses)
ret, results, neighbours, dist = knn.findNearest(newcomer, 3)
print("result: {}\n".format(results))
print("neighbours: {}\n".format(neighbours))
print("distance: {}\n".format(dist))
plt.show()运行结果:
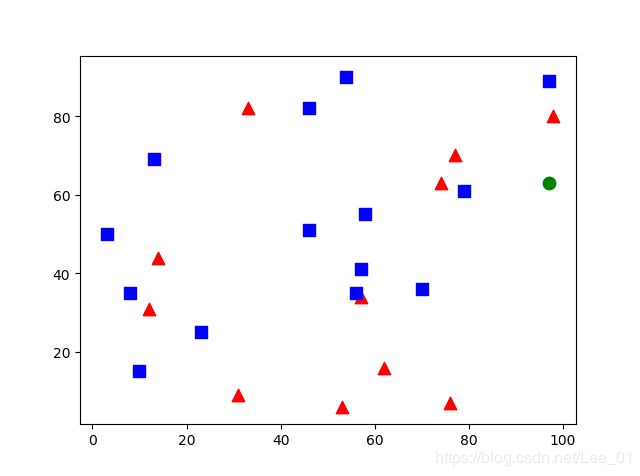
result: [[0.]]
neighbours: [[0. 1. 0.]]
distance: [[290. 328. 449.]]
2.kNN(分类)OCR of Hand-written Digits
任务:识别手写数字
数据集:10*500个手写数字构成的图像(2000x1000),每个数字图像尺寸为20x20,下载地址
训练集:数据集的一半,10*250张图像
测试集:数据集的一半,10*250张图像
训练代码:
import numpy as np
import cv2 as cv
img = cv.imread("../pic/digits.png")
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# split the image to 5000 cells,each 20x20size
cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)]
# make the cell into a numpy array with size--(50,100,20,20)
x = np.array(cells)
# prepare the train_data and test_data
# flatten each 20x20 image into a single row with 400 pixels
train = x[:, :50].reshape(-1, 400).astype(np.float32) # size=(2500,400)
test = x[:, 50:100].reshape(-1, 400).astype(np.float32) # size=(2500,400)
# create labels for train and test data
k = np.arange(10)
train_labels = np.repeat(k, 250)[:, np.newaxis]
test_labels = train_labels.copy()
# save the data
np.savez('knn_data.npz', train=train, train_labels=train_labels,
test=test, test_labels=test_labels)测试代码:
import numpy as np
import cv2 as cv
# load the data
with np.load('knn_data.npz') as data:
train = data['train']
train_labels = data['train_labels']
test = data['test']
test_labels = data['test_labels']
# initiate kNN,train and then test it with test data
knn = cv.ml.KNearest_create()
knn.train(train, cv.ml.ROW_SAMPLE, train_labels)
ret, result, neighbours, dist = knn.findNearest(test, k=5)
# check the accuracy of classification
matches = result == test_labels
correct = np.count_nonzero(matches)
accuracy = correct * 100.0 / result.size
print(accuracy,'%')准确率:91.76%
3.kNN(分类)OCR of English Alphabets
数据集:letter-recognition.data,共20000行,第一列为label,后面16列整数为特征值。想深入了解特征获取方式见链接1,链接2
T,2,8,3,5,1,8,13,0,6,6,10,8,0,8,0,8 I,5,12,3,7,2,10,5,5,4,13,3,9,2,8,4,10 D,4,11,6,8,6,10,6,2,6,10,3,7,3,7,3,9 N,7,11,6,6,3,5,9,4,6,4,4,10,6,10,2,8 G,2,1,3,1,1,8,6,6,6,6,5,9,1,7,5,10 S,4,11,5,8,3,8,8,6,9,5,6,6,0,8,9,7 B,4,2,5,4,4,8,7,6,6,7,6,6,2,8,7,10
代码:
import numpy as np
import cv2 as cv
# load the data,converters convert the letter to a number
data = np.loadtxt('letter-recognition.data', dtype='float32', delimiter=',',
converters={0: lambda ch: ord(ch) - ord('A')})
# split the data to two, 10000 each for train and test
train, test = np.vsplit(data, 2)
# split trainData and testData to features and responses
responses, trainData = np.hsplit(train, [1])
labels, testData = np.hsplit(test, [1])
# initiate the kNN
knn = cv.ml.KNearest_create()
knn.train(trainData, cv.ml.ROW_SAMPLE, responses)
ret, result, neighbors, dist = knn.findNearest(testData, k=5)
correct = np.count_nonzero(result == labels)
accuracy = correct * 100.0 / 10000
print(accuracy, '%')准确率:93.06 %
参考文章:
https://docs.opencv.org/master/d5/d26/tutorial_py_knn_understanding.html
https://docs.opencv.org/master/d8/d4b/tutorial_py_knn_opencv.html