python图形验证码识别
文章目录
- 开发环境
- 思路
- 实践
- 图像预处理 - 灰度、二值化
- 图像预处理 - 8临域法降噪
- 图像切割
- 步骤一:连通域法获取字符图像
- 步骤二:根据连通域数量判断是否降噪过度或有字符粘连
- 步骤三:完成切割
- 机器学习
- 识别测试
开发环境
- Python2.7
- Pillow4.1.1
- numpy1.15.2
- sklearn0.20.0
思路
- 对图像进行灰度化、二值化处理
- 根据图像特征进行切割,提取单个字符内容
- 针对单个字符进行机器学习
- 识别
实践
演示用的原始图片如下

图像预处理 - 灰度、二值化
首先用PIL内置的convert方法进行灰度处理,经过灰度后,每个像素点的颜色值从RGB的3维变成了1维,值的范围为0-255,值越大,颜色越倾向于白,或者说颜色更淡。
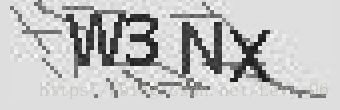
观察灰度后的图片,可以发现字符的颜色更深,背景、干扰线的颜色更浅,这一特征是后续二值化操作的关键。
二值化是在灰度图的基础上将所有像素点的颜色二值化,也就是非黑即白,这里遍历像素点,简单地根据一个预设的灰度阈值,将大于阈值的灰度值设为0,即白色,小于阈值的灰度值设为255,即黑色。(这里阈值需要经过多次试验,确定一个合适的值,如果验证码比较复杂,背景、干扰线不能很好地和字符区分,需要一些特殊处理和计算来获得合适的阈值,这点以后有机会再做深入研究)
二值化效果如下:

from PIL import Image
def remove_color(img, threshold=105):
"""
灰度、二值化
:param img: Image实例
:param threshold: 灰度阈值
:return:
"""
img_greyed = img.convert('L') # 灰度化
table = img_greyed.load()
width, height = img_greyed.size
for x in range(width):
for y in range(height):
if table[x, y] < threshold:
table[x, y] = 0
else:
table[x, y] = 255
return img_greyed
图像预处理 - 8临域法降噪
经过灰度、二值化的图片,可以看到干扰线被去得比较干净,但还剩余了零散的噪点,接下来根据8临域法来去除噪点。
8临域指的是一个像素点周围的8个点,如果一个点的周围都是白色背景,那么这个点就一定是噪点。反之,遍历各像素点,统计其8个临近点的值,如果值为255即黑色的数量大于某个阈值,则该点不是噪点,这里阈值取的是6,效果如下:

效果拔群!
def remove_noise(img, threshold=6):
"""8临域法降噪"""
table = img.load()
width, height = img.size
for x in range(1, width-1):
for y in range(1, height-1):
count = 0
if table[x, y-1] == 255:
count += 1
if table[x, y+1] == 255:
count += 1
if table[x-1, y] == 255:
count += 1
if table[x+1, y] == 255:
count += 1
if table[x-1, y-1] == 255:
count += 1
if table[x-1, y+1] == 255:
count += 1
if table[x+1, y+1] == 255:
count += 1
if table[x+1, y-1] == 255:
count += 1
if count > threshold:
table[x, y] = 255
注意x与y的遍历范围在[1, width-1]与[1, height-1]之间,这是为了避免取8临域的时候发生下标越界。
图像切割
步骤一:连通域法获取字符图像
对于连通域法的讲解,https://www.cnblogs.com/fireae/p/3723785.html 这篇文章挺不错的。
以下python代码实现了对图像的两次扫描,第一次扫描将相邻像素点进行标号,并记录标号等价关系;第二次扫描将标号替换成最小等价标号,并将像素点分组,用于后续切割。最后根据传入阈值,将面积小于阈值的连通域作为噪点剔除。
def get_domains(img_denoised, threshold=10):
"""
获取连通域
"""
table = img_denoised.load()
width, height = img_denoised.size
tab_img = Image.new('L', (width, height), 255)
tab_table = tab_img.load()
equals = [] # 存储标号等价关系,e.g. [[1, 2, 3], [4, 6], [5]]
tab = 1 # 下一个标号
# 第一次扫描
for y in range(height):
for x in range(width):
if table[x, y] == 0:
tab = set_temp_tab(tab_table, x, y, tab, equals)
# 第二次扫描
domains = {}
for y in range(height):
for x in range(width):
if tab_table[x, y] != 255:
min_tab = get_min_tab(tab_table[x, y], equals)
if min_tab in domains:
domains[min_tab].append((x, y))
else:
domains[min_tab] = [(x, y)]
real_domains = [domains[i] for i in domains if len(domains[i]) >= threshold] # 根据连通域面积筛除可能噪点
return real_domains
def get_min_tab(tab, equals):
"""获取最小等价标号"""
for a_equal in equals:
if tab in a_equal:
return min(a_equal)
def set_temp_tab(tab_table, x, y, tab, equals):
"""设置临时标号,存储等价关系"""
tabs = []
for near_point in [(x-1, y-1), (x, y-1), (x+1, y-1), (x-1, y)]: # 遍历左上、上、右上、左4个临近点
try:
near_point_tab = tab_table[near_point[0], near_point[1]] # 临近点的标记
if near_point_tab != 255 and near_point_tab not in tabs:
tabs.append(near_point_tab)
except IndexError: # 当标号点扫描至最后一个时,遍历其右上点就会抛出IndexError
pass
if not tabs: # 4个临近点都无标号,则产生新标号
tab_table[x, y] = tab
equals.append([tab])
return tab + 1
elif len(tabs) == 1: # 4个临近点只存在一个标号
tab_table[x, y] = tabs[0]
return tab
else: # 4个临近点存在多个标号,取最小标号,并更新等价关系
min_tab = min(tabs)
tab_table[x, y] = min_tab
appended_equal = []
for a_tab in tabs: # 合并等价关系
if a_tab == min_tab:
continue
for a_equal in equals:
if min_tab in a_equal:
if appended_equal:
a_equal += appended_equal
appended_equal = a_equal
elif a_tab in a_equal:
appended_equal += a_equal
equals.remove(a_equal)
return tab
步骤二:根据连通域数量判断是否降噪过度或有字符粘连
n表示字符实际数量,可能的情况如下:
若连通域数量刚好等于n,则直接完成切割;
若连通域数量大于n,则降噪过度,导致单个字符被分割成多个连通域,则选择更高的灰度阈值进行二值化,重复上述步骤;
若连通域数量刚好等于n-1,则存在粘连情况,取面积最大的连通域,通过K-means算法根据坐标与RGB值对像素点进行聚类,进一步切割成2个连通域;(使用K-means聚类的依据在于测试用的图形验证码不同字符之间颜色不同)
若连通域数量小于n-1,则切割失败。(可能存在3个字符粘连的情况,相对比较复杂,没有做响应处理,但实际操作的原理应该是一样的)
很明显,示例的验证码中存在两个字符粘连的情况,同时不同字符之间的颜色明显不同,我们可以定义每个像素点具有5个特征:x坐标,y坐标,R值,G值,B值。根据这5个特征,进行k-means聚类,可以得到分离的两组像素点。
为了有更好的聚类效果,让单个字符的RGB值趋向一致,首先以一个小滑块的范围扫描图片,将小滑块范围内的像素点颜色设为均值。由于图形验证码是长方形的图形,这里的小滑块块按照图片的长、宽的最小除数来取。
def average_img_color(img, img_denoised):
"""将原始图片按照每小块颜色均值化"""
table = img.load()
table_denoised = img_denoised.load()
width, height = img.size
step_width = min_div(width)
step_height = min_div(height)
for start_x in range(0, width, step_width):
for start_y in range(0, height, step_height):
points = [(x, y)
for x in range(start_x, start_x + step_width)
for y in range(start_y, start_y + step_height)]
color_points = []
sum_r = 0
sum_g = 0
sum_b = 0
for x, y in points:
if table_denoised[x, y] == 255:
table[x, y] = (255, 255, 255)
else:
color_points.append((x, y))
sum_r += table[x, y][0]
sum_g += table[x, y][1]
sum_b += table[x, y][2]
if color_points:
avg_color = (sum_r / len(color_points), sum_g / len(color_points), sum_b / len(color_points))
for x, y in color_points:
table[x, y] = avg_color
def min_div(num):
"""获取num的除1外的最小除数"""
assert num > 1
assert isinstance(num, int)
for i in range(2, num+1):
if num % i == 0:
return i
接下来可以进行k-means聚类了:
def k_means_split(img, img_denoised, domain, k_means_times=5):
"""K-means算法切割粘连字符"""
def _get_x(p):
return p[0]
average_img_color(img, img_denoised)
table = img.load()
points = [(x, y, table[x, y]) for x, y in domain]
points.sort(key=_get_x) # 根据x从小到大排序
core_points = [points[0], points[-1]] # 取最左侧点和最右侧点作为初始中心点
temp_core_points = []
times = 0
groups = []
while not equal_points(core_points, temp_core_points) or times < k_means_times:
groups = k_means_groups(points, core_points)
temp_core_points = core_points
core_points = get_core_points(groups)
times += 1
for group in groups:
for index, point in enumerate(group):
group[index] = (point[0], point[1])
return groups
def k_means_groups(points, core_points):
"""
根据已知中心点对所有点进行聚类
:param points:
:param core_points:
:return:
"""
groups = [[] for _ in range(len(core_points))]
for p in points:
distances = [(p[0] - cp[0]) ** 2 + (p[1] - cp[1]) ** 2 +
(p[2][0] - cp[2][0]) ** 2 + (p[2][1] - cp[2][1]) ** 2 + (p[2][2] - cp[2][2]) ** 2
for cp in core_points]
index = distances.index(min(distances))
groups[index].append(p)
return groups
def get_core_points(knn_groups):
"""计算中心点"""
core_points = []
for group in knn_groups:
num = len(group)
core_x = sum([p[0] for p in group]) / num
core_y = sum([p[1] for p in group]) / num
core_r = sum([p[2][0] for p in group]) / num
core_g = sum([p[2][1] for p in group]) / num
core_b = sum([p[2][2] for p in group]) / num
core_points.append((core_x, core_y, (core_r, core_g, core_b)))
return core_points
def equal_points(points_a, points_b):
"""比较两组点是否完全相同"""
if len(points_a) != len(points_b):
return False
if all([p in points_b for p in points_a]):
return True
else:
return False
将经过连通域和k-means聚类得到的字符区域进行标色,得到下图,对粘连字符的区分效果还是不错的。

由于示例的W和3原始颜色还是有点接近,有个别几个像素点被分错了簇,观察发现这些像素点一般是分散在簇中的,可以用投影法进行处理。
此处投影法就是将图像向x轴进行投影,可以得到多个连续的片段,以W为例,最长的片段显然是W本体,而其他小片段是属于3簇,被错误分入W簇的像素点,那么把这些像素点重新分回3簇即可。同理,再将3簇中错误的像素点重新分回W簇。
def remove_wrong_point_by_shadow(group_a, group_b):
"""通过投影法消除相近颜色像素点对k-means聚类的干扰"""
def _get_x(p):
return p[0]
group_a.sort(key=_get_x)
slice_list = []
shadow_slice = []
last_x = group_a[0][0]
for x, y in group_a:
if x == last_x or x == last_x + 1:
shadow_slice.append((x, y))
last_x = x
else:
last_x = x
if shadow_slice:
slice_list.append(shadow_slice)
shadow_slice = [(x, y)]
else:
if shadow_slice:
slice_list.append(shadow_slice)
slice_list.sort(key=len, reverse=True)
real_points = slice_list[0]
removed_points = set(group_a) - set(real_points)
for x, y in removed_points:
group_a.remove((x, y))
group_b.append((x, y))
步骤三:完成切割
实际上不是在原图片上进行切割,为了让不同图片上切割出来的字符特征更加接近,根据上述步骤得到的4组像素点,依次新建一个合适大小的空白图片,将像素点经过位移后放入新建的空白图片。
def do_split(img, num):
"""
切割图形验证码
:param img: Image实例
:param num: 切割数量
:return:
"""
gray_threshold = 105
retry = 3 # 降噪重试次数
while retry > 0:
retry -= 1
img_denoised = de_noise(img, gray_threshold)
gray_threshold += 5
domains = get_domains(img_denoised)
if len(domains) == num: # 连通域数量等于num,完成切割
pass
elif len(domains) > num: # 降噪过度,重新降噪
continue
elif len(domains) == num - 1: # 切割粘连字符
size = 0
pop_index = 0
for index, domain in enumerate(domains):
if len(domain) > size:
pop_index = index
size = len(domain)
domain_to_split = domains.pop(pop_index) # 待切割的连通域
groups = k_means_split(img, img_denoised, domain_to_split)
remove_wrong_point_by_shadow(groups[0], groups[1])
remove_wrong_point_by_shadow(groups[1], groups[0])
for group in groups:
domains.insert(pop_index, group)
pop_index += 1
else:
raise RuntimeError('The img can not be splited.')
return split_by_groups(domains)
else:
raise RuntimeError('The img can not be denoised.')
def split_by_groups(groups):
"""根据分组进行切割"""
def _get_min_x(g):
return min([p[0] for p in g])
img_list = []
groups.sort(key=_get_min_x)
for group in groups:
img = Image.new('L', (18, 18), 255) # 将图片处理成统一18*18大小,即18*18个特征
table = img.load()
move_y = min([point[1] for point in group])
move_x = min([point[0] for point in group])
for point in group:
try:
table[point[0] - move_x, point[1] - move_y] = 0
except IndexError:
raise RuntimeError('Split failed.')
img_list.append(img)
return img_list
效果如下:



机器学习
测试取了1100个验证码,人工进行识别并命名后,通过程序进行切割,得到从0-9,从A到Z(示例的图形验证码不存在字母O),分别存储在不同文件夹下:


接着用sklearn进行学习,并用交叉验证的方式进行打分
import pickle
from PIL import Image
import numpy
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
def set_database():
x = []
y = []
for i in '1234567890ABCDEFGHIJKLMNPQRSTUVWXYZ':
target_path = dir_path + os.sep + 'splited_img' + os.sep + i
for img_name in os.listdir(target_path):
if img_name == '.DS_Store':
continue
pix = numpy.asarray(Image.open(target_path + os.sep + img_name).convert('L'))
rows, cols = pix.shape
pix.flags['WRITEABLE'] = True
for row_value in range(rows):
for col_value in range(cols):
pix[row_value, col_value] = 0 if pix[row_value, col_value] < 100 else 1
pix = numpy.ravel(pix)
x.append(pix)
y.append(i)
x = numpy.asarray(x)
y = numpy.asarray(y)
numpy.save(dir_path + os.sep + 'database_x', x)
numpy.save(dir_path + os.sep + 'database_y', y)
def get_database():
x = numpy.load(dir_path + os.sep + 'database_x.npy')
y = numpy.load(dir_path + os.sep + 'database_y.npy')
return x, y
def cross_validation(validate=False):
"""交叉验证"""
X, y = get_database()
clf = SVC(kernel='rbf', C=20, class_weight='balanced')
model = clf.fit(X, y)
with open(MODEL_DIR + os.sep + '_svc.model', 'wb') as model_file:
pickle.dump(model, model_file)
if validate:
scores = cross_val_score(clf, X, y, cv=5)
print "Accuracy: %0.2f (+- %0.2f)" % (scores.mean(), scores.std())
return clf
打分结果可以得到99%
Accuracy: 0.99 (+- 0.00)
识别测试
def predict(img_name):
"""
识别图形验证码
:param img_name: 图片文件名
:return:
"""
model = _get_model()
img = Image.open(IMG_DIR + os.sep + img_name)
try:
img_list = do_split(img, 4)
result = []
for img in img_list:
img.show()
pix = numpy.asarray(img)
rows, cols = pix.shape
pix.flags['WRITEABLE'] = True
for x, y in [(x, y) for x in range(rows) for y in range(cols)]:
pix[x, y] = 1 if pix[x, y] == 255 else 0
pix = numpy.ravel(pix)
result.append(model.predict(pix.reshape(1, -1))[0])
return ''.join(result)
except RuntimeError:
return ''
def _get_model():
with open(MODEL_DIR + os.sep + 'svc.model') as model_file:
model = pickle.load(model_file)
return model
对300个图形验证码进行了测试,切割成功率为100%,识别成功率为95%,平均每秒切割、识别13个码。
