分类模型与算法--决策树
本文主要介绍决策树的原理、划分属性选择、决策树的种类、剪枝方式,以及用三种R包实现决策树。
一、概述
决策树(Decision Tree)是一种常见的机器学习方法,它基于人类在面临决策问题时一种很自然的处理机制,即树结构来进行决策。如下图所示:

其中:一棵决策树包含一个根结点、若干内部节点和若干叶结点;根结点包含样本全集;每一个内部结点对应于一个属性测试;叶结点则对应于决策结果;从根节点到叶结点的路径对应了一个判定测试序列。
显然,决策树的生成是一个递归的过程。有三种情形会导致递归返回:
(1)当前结点包含的样本全属于同一类别,无需划分,此时把当前结点标记为叶结点,并将其类别设定为该结点;
(2)当前属性集为空,或所有样本在所有属性上取值相同,无法划分,此时把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别;
(3)当前结点包含的样本集合为空,不能划分,此时同样把当前结点标记为叶结点,并将其类别设定为其父结点所含样本最多的类别。
二、划分选择
从决策树原理可以看出,如何选择最优划分属性是决策树学习的关键。那么如何衡量属性划分的优劣呢?一般来讲,随着划分过程的不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”越来越高。由此,产生了三种比较流行的衡量划分属性的方法,分别是:信息增益、信息增益率和基尼指数,分别对应于三种决策树:ID3(Iterative Dichotomiser,迭代二分器)、C4.5和CART(Classification and Regression Tree)。
1.信息增益
在了解信息增益之前,首先要理解信息熵(information entropy)。熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度,无序程度越高,不确定性越大,熵也就越大。将熵引申到信息论中,信息熵表达对不确定性的度量,是度量样本集合纯度最常用的一种指标。
假定当前样本集合D中第k类样本所占的比例为pk(k=1,2,…,|y|),则D的信息熵定义为:![]()
Ent(D)的值越小,则D的纯度越高。
假定离散属性a有V个可能的取值{a1,a2,…,aV},若使用a来对样本集D进行划分,则会产生V个分支节点,其中第v个节点包含了D中所有在属性a上取值为av的样本,记为Dv,我们可以计算出Dv的信息熵,在考虑到不同的分支节点包含的样本数的不同,给分支节点赋予权重|Dv|/|D|,即样本数越多的分支结点的影响越大,于是用属性a对样本集D进行划分所获得的“信息增益”为:
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度”提升越大。ID3决策树学习算法就是以信息增益来进行决策树的划分属性选择的。
2.信息增益率
实际上,信息增益准则对可取值数目较多的属性有所偏好,因为属性值越多,在划分样本时产生分支结点越多,每个分支结点包含的样本量越少,其纯度往往会更高。但是,这样的决策树泛化能力比较弱,无法对新样本进行有效预测。
为了减少信息增益准则的这种偏好带来的不利影响,著名的C4.5决策树算法不直接使用信息增益,而是使用信息增益率来选择最优划分属性。
增益率的定义为:![]()
其中:
当然,与信息增益准则相反,增益率准则对取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
3.基尼指数
上述两种决策树都是建立在以信息熵作为度量样本纯度的指标基础之上的,与之不同的是CART决策树使用基尼指数(Gini index)来选择划分属性。
数据集D的纯度可用基尼值来度量:
Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此Gini(D)越小,则数据集D的纯度越高。
属性a的基尼指数定义为: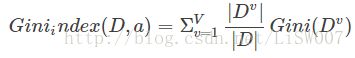
于是,我们在候选属性选择时,选择那个使得划分后基尼指数最小的属性最为最优划分属性。
三、剪枝处理
在决策树建立的过程中,若不加任何限制,最后生成的树必然能完全拟合原始数据,这样的树在实际应用中毫无意义,因为树的枝节太多,而不能反映数据内在大规律,这便是过拟合。
决策树很容易出现过拟合的现象。决策树的过拟合现象可以通过剪枝进行一定的修复。剪枝分为预先剪枝和后剪枝两种。
预先剪枝指在决策树生长过程中,使用一定条件加以限制,使得产生完全拟合的决策树之前就停止生长。预先剪枝的判断方法也有很多,比如信息增益小于一定阀值的时候通过剪枝使决策树停止生长。但如何确定一个合适的阀值也需要一定的依据,阀值太高导致模型拟合不足,阀值太低又导致模型过拟合。
后剪枝是在决策树生长完成之后,按照自底向上的方式修剪决策树。后剪枝有两种方式,一种用新的叶子节点替换子树,该节点的预测类由子树数据集中的多数类决定。另一种用子树中最常使用的分支代替子树。
预先剪枝可能过早的终止决策树的生长,后剪枝一般能够产生更好的效果。但后剪枝在子树被剪掉后,决策树生长的一部分计算就被浪费了。
四、实例
1.R语言函数介绍
在R语言中,主要有三个函数可以实现决策树算法,分别是rpart包中的rpart函数(实现CART决策树,剪枝prune())、party包中的ctree函数(实现CART决策树)和RWeka包中的J48函数(实现C4.5决策树),具体如下:
(1)rpart包
rpart(formula,data,weights,subset,na.action=na.rpart,method,model=FALSE,x=FALSE,y=TRUE,parms,control,cost,...)
主要参数说明:
fomula 回归方程形式:例如 y~x1+x2+x3 。
data 数据:包含前面方程中变量的数据框(dataframe)。
na.action 缺失数据的处理办法:默认办法是删除因变量缺失的观测而保留自变量缺失的观测。
method 根据树末端的数据类型选择相应变量分割方法,本参数有四种取值:连续型“anova”;离散型“class”;计数型(泊松过程)”poisson”;生存分析型“exp”。程序会根据因变量的类型自动选择方法,但一般情况下最好还是指明本参数,以便让程序清楚做哪一种树模型。
parms 用来设置三个参数:先验概率、损失矩阵、分类纯度的度量方法。
control 控制每个节点上的最小样本量、交叉验证的次数、复杂性参量:即CP(complexity parameter),这个参数意味着对每一步拆分,模型的拟合优度必须提高的程度,等等。
剪枝:
prune(tree,cp)
主要参数说明:
tree 一个回归树对象:常是rpart()的结果对象。
cp 复杂性参量:指定剪枝采用的阈值。
(2)party包
ctree(formula,data,weights,subset,na.action=na.pass,control=ctree_control(…),ytrafo=NULL,scores=NULL,…)
剪枝:control参数
(3)RWeka包
J48(formula,data,subset,na.action,control=Wekacontrol(),options=NULL)
剪枝:control参数
2.R语言实战
本次实例使用iris数据集,该数据集为R内置数据集,相信大家都比较熟悉了,此处不做详细介绍。
(1)使用rpart包
#下载并加载所需要的包
install.packages("rpart")
library("rpart")
#了解数据
str(iris)
summary(iris)
#抽样
set.seed(12)
index <- sample(1:nrow(iris), size = 0.75 * nrow(iris))
train <- iris[index, ]
test <- iris[-index, ]
#查看抽样的合理性
prop.table(table(iris$Species))
prop.table(table(train$Species))
prop.table(table(test$Species))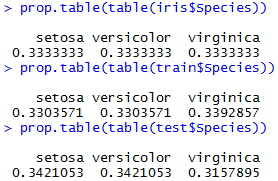
训练集与测试集中的分布基本一致,可以进一步建模。
#建模
irismodel <- rpart(Species ~ ., method = "class", data = train )
#查看结果并画出决策树
irismodel
plot(irismodel, uniform = T, branch = 0, margin = 0.2)
text(irismodel, use.n = T, fancy = T,all = T)建模结果及规则如下:
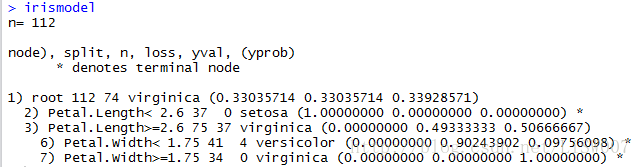
所画决策树如下:
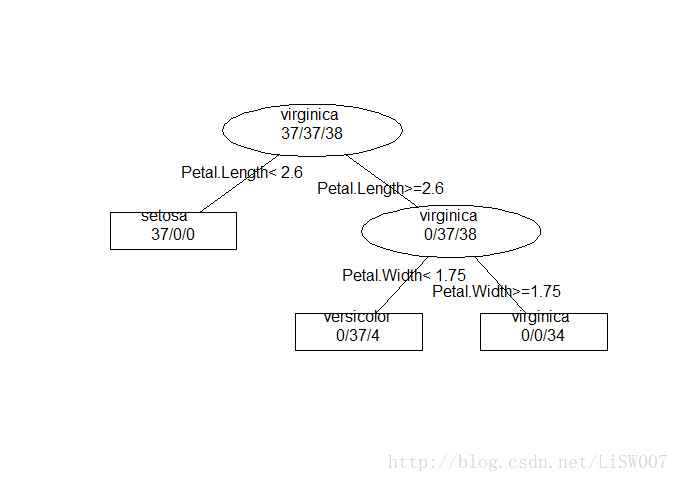
可以看出训练集中有4个样本被判错,正确率为108/112=96.4%。
#预测
prediris <- predict(irismodel, newdata = test)
prediris用predict函数做完预测后是这样的:

虽然能看出来分类,但是不够直观。因此,进一步构建混淆矩阵:
#将结果直观展现
prediris1 <- data.frame(prediris)
prediris1$Species <- ' ' #在预测结果后面加上种属列,并赋予空值
prediris1[prediris1$setosa > prediris1$versicolor & prediris1$setosa > prediris1$virginica,][ ,"Species"] <- 'setosa'
prediris1[prediris1$versicolor > prediris1$setosa & prediris1$versicolor > prediris1$virginica,][ ,"Species"] <- 'versicolor'
prediris1[prediris1$virginica > prediris1$setosa & prediris1$virginica > prediris1$versicolor,][ ,"Species"] <- 'virginica'
table(prediris1$Species,test$Species)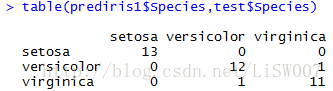
从上述结果可以看出,测试集判定错误的点有两个,正确率为36/38=94.7%,还是不错的。
(2)使用party包
install.packages("party")
library("party")
set.seed(12)
index <- sample(1:nrow(iris), 0.75*nrow(iris))
train <- iris[index,]
test <- iris[-index,]
iris_tree <- ctree(Species ~ ., data = train)
iris_tree
table(predict(iris_tree), train$Species)
plot(iris_tree)
pred <- predict(iris_tree, newdata = test)
table(pred, test$Species)构建的决策树如下:

画出决策树:

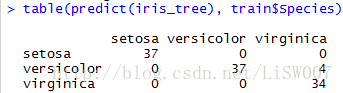
从上述结果中可以看出训练集中依旧有4个样本被判错,正确率为108/112=96.4%。

测试集判定错误的点有两个,正确率为36/38=94.7%。
(3)使用RWeka包
install.packages("RWeka")
install.packages("partykit") #用来画决策树,会比较好看噢
library(RWeka)
library(partykit)
set.seed(12)
index <- sample(1:nrow(iris), 0.75*nrow(iris))
train <- iris[index,]
test <- iris[-index,]
iris_j48 <- J48(Species ~ ., data = train)
summary(iris_j48)
plot(iris_j48)
pred <- predict(iris_j48, newdata = test)
table(pred, test$Species)建模结果如下:

训练集共112个样本,其中正确的有110个,正确率高达98.2%。
构建的决策树如下:
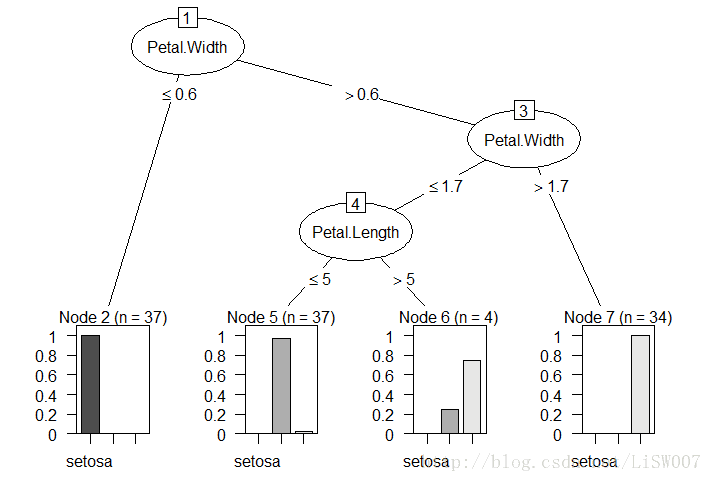
可以看出用partykit包画出来的决策树会比较好看噢,而且命令也非常简单。
测试集的混淆矩阵如下:

—————决策树总结——————-
1、决策树的重点在于最优划分属性的选择和剪枝处理。
2、三种包的比较:R中实现决策树的包有三种rpart包、party包和RWeka包,前两者实现CART决策树,后者实现C4.5决策树。其中party和RWeka使用起来比较方便,且就实例iris数据集来讲,RWeka包的精度最高,且画图简单美观;party包中的ctree()函数不能很好地处理缺失值,含有缺失值的观测有时被划分到左子树,有时划到右子树,这是由缺失值的替代规则决定的。
3、决策树易于理解,可操作性强,对业务的解释性较强。
参考资料:
【1】r语言做决策树代码实现
【2】周志华.机器学习[M].北京:清华大学出版社,2016.
【3】R talks to Weka about Data Mining
【4】决策树