面试题答案
1.HashMap的源码,实现原理,JDK8中对HashMap做了怎样的优化
实现原理就是通过哈希表来实现,数组+链表来存储数据,默认是16的数组,通过hash(key)&(length-1)来定位数据应该存在数组哪个元素里去,如果key冲突,就将数据放在该元素的链表里去.在取数据时,先定位到数组元素,再遍历链表
jdk8为了防止单个数组元素里的链表过长,采用了平衡树的形式来存放数据
2.HaspMap扩容是怎样扩容的,为什么都是2的N次幂的大小。
综上所述 2的n次方-1得到的二进制每个位上的值都为1,而非2的n次方-1得到的二进制每个位上的值有可能为0,为0的后果就是造成有些位置永远不会被存放元素,因为0与任何数&的结果都是0,这就造成那些数为1的位置永远都不会有元素存进去.即浪费空间又增加碰撞的几率,所以基于这个原因,在扩容时才都是长度*2
3.HashMap,HashTable,ConcurrentHashMap的区别
HashMap线程不安全,HashTable跟ConcurrentHashMap都是线程安全的,但是HashTable是锁住全表,ConcurrentHashMap是锁部分
4.高并发下,HashTable跟ConcurrentHashMap哪个性能更好?为什么,怎么实现的
ConcurrentHashMap性能更好,因为它采用了分段锁的设计,JDK7还是用segment,到了JDK8就用了CAS+Synchronized的设计,它就是先利用hash(key)&(lengt-1)定位到数组某个元素,如果那个元素还是空的,就用CAS进行赋值,如果元素不为空,就用Syncronized把对应元素的链表给锁起来
5.HashMap在高并发下如果没有处理线程安全会有怎样的安全隐患,具体表现是什么
当多个线程同时执行addEntry(hash,key ,value,i)时,如果产生哈希碰撞,导致两个线程得到同样的bucketIndex去存储,就可能会发生元素覆盖丢失的情况
6.动态代理的两种方式,区别是什么
jdk和cglib代理,jdk需要实现接口,而且动态代理调用的方法需要是接口有的才能动态代理
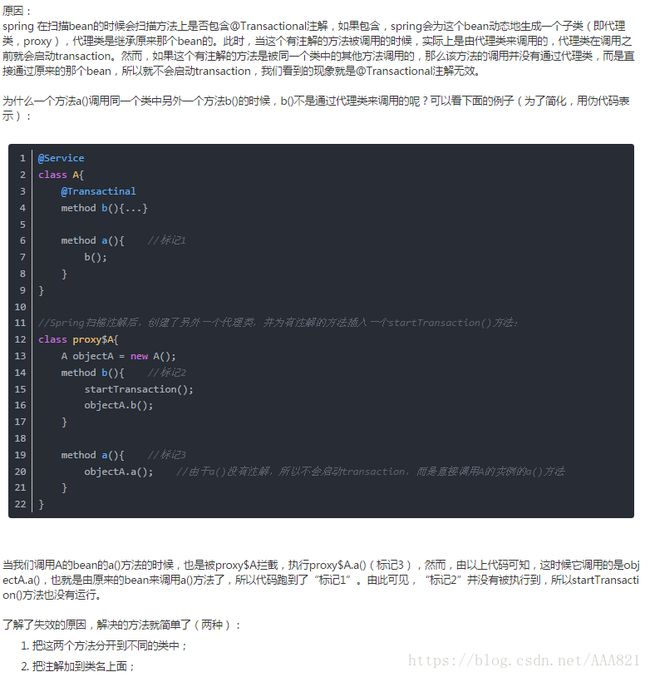
7 @Transational什么时候会失效,为什么
A方法没有注解,B方法有注解,A调用B,B的注解不会起作用.
8.Lock接口比synchronized块的优势是什么
最大的优势就是它把读写区分开来,有读锁和写锁,ReentrantReadWriteLock的readLock()和writeLock()用来获取读锁和写锁。
9.有没有遇到过内存溢出,内存溢出怎么解决
导致OutOfMemoryError异常的常见原因有以下几种:
1.程序中使用了大量的jar或class,使java虚拟机装载类的空间不够
相关提示语:tomcat:java.lang.OutOfMemoryError: PermGen space
解决方法:
1、增加java虚拟机中的XX:PermSize和XX:MaxPermSize参数的大小,其中XX:PermSize是初始永久保存区域大小,XX:MaxPermSize是最大永久保存区域大小。
2、清理应用程序中web-inf/lib下的jar,如果tomcat部署了多个应用,很多应用都使用了相同的jar,可以将共同的jar移到tomcat共同的lib下,减少类的重复加载
2.java虚拟机创建的对象太多,在进行垃圾回收之间,虚拟机分配的到堆内存空间已经用满了,与Heap space有关。
相关提示语:tomcat:java.lang.OutOfMemoryError: Java heap space
解决方法:
1、检查程序,看是否有死循环或不必要地重复创建大量对象。找到原因后,修改程序和算法。
2、增加Java虚拟机中Xms(初始堆大小)和Xmx(最大堆大小)参数的大小。
3 JVM已经被系统分配了大量的内存(比如1.5G),并且它至少要占用可用内存的一半。有人发现,在线程个数很多的情况下,你分配给JVM的内存越多,上述错误发生的可能性就越大
相关提示语:OutOfMemoryError:unable to create new native thread
那么是什么原因造成这种问题呢?
每一个32位的进程最多可以使用2G的可用内存,因为另外2G被操作系统保留。这里假设使用1.5G给JVM,那么还余下500M可用内存。这500M内存中的一部分必须用于系统dll的加载,那么真正剩下的也许只有400M,现在关键的地方出现了:当你使用Java创建一个线程,在JVM的内存里也会创建一个Thread对象,但是同时也会在操作系统里创建一个真正的物理线程(参考JVM规范),操作系统会在余下的400兆内存里创建这个物理线程,而不是在JVM的1500M的内存堆里创建。在jdk1.4里头,默认的栈大小是256KB,但是在jdk1.5里头,默认的栈大小为1M每线程,因此,在余下400M的可用内存里边我们最多也只能创建400个可用线程。
对于这个异常我们首先需要判断下,发生内存溢出时进程中到底都有什么样的线程,这些线程是否是应该存在的,是否可以通过优化来降低线程数; 另外一方面默认情况下java为每个线程分配的栈内存大小是1M,通常情况下,这1M的栈内存空间是足足够用了,因为在通常在栈上存放的只是基础类型的数据或者对象的引用,这些东西都不会占据太大的内存, 我们可以通过调整jvm参数,降低为每个线程分配的栈内存大小来解决问题,例如在jvm参数中添加-Xss128k将线程栈内存大小设置为128k。
10.http协议有哪些部分组成?
由三部分组分 1. Request/Response Line 2. Request/Response Header 3.Request/Response Body
请求行、请求头、请求体
11.MySQL的delete与truncate区别?
一、灵活性:delete可以条件删除数据,而truncate只能删除表的所有数据;
delete from table_test where ...
truncate table table_test
二、效率:delete效率低于truncate,delete是一行一行地删除,truncate会重建表结构,
三、事务:truncate是DDL(操作数据结构)语句,需要drop权限,因此会隐式提交,不能够rollback;delete是DML(操作数据)以使用rollback回滚。
四、触发器:truncate 不能触发任何Delete触发器;而delete可以触发delete触发器。
12.Redis常见的性能问题怎么解决
1. Redis的RDB快照,即将内存数据持久到磁盘时,如果数据量大,写操作很多的话,会引起大量的IO操作,影响性能
save命令调度rdbSave函数,会阻塞主线程的工作(bgSave命令就不会阻塞,它会在后台异步进行快照操作),当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
解决:可以在Slave进行快照操作
2.Redis重写AOF
AOF采用文件追加方式,这样会导致AOF文件越来越大,为此,redis提供了AOF文件重写(rewrite)机制,即当AOF文件的大小超过所设定的阈(yu)值时,redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。可以使用命令bgrewriteaof. AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
解决:同样在Slave进行bgRewriteAof操作
13.spring设置为单例 那么线程安全问题怎么解决?
要么将单例改成多例,即scope = prototype 要么在单例对象中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中
14.什么是有状态对象,什么是无状态对象?
有状态就是有数据存储功能。有状态对象(Stateful Bean),就是有实例变量的对象 ,可以保存数据,是非线程安全的。在不同方法调用间不保留任何状态。其实就是有数据成员的对象。
无状态就是一次操作,不能保存数据。无状态对象(Stateless Bean),就是没有实例变量的对象。不能保存数据,是不变类,是线程安全的。具体来说就是只有方法没有数据成员的对象,或者有数据成员但是数据成员是可读的
//有状态对象,单例模式下,线程不安全的
public Class User{
public String name;
public int age;
}
//无状态对象,就是只有方法没有属性,线程安全的。
public Class UserService{
publilc boolean addUser(String name,int age){
}
}15.JVM的栈中引用如何和堆中的对象产生关联
栈指向了堆中对象存放的地址,从而实现了关联。
16.哪5种情况会对类立刻进行初始化
class文件加载到JVM中:
- 创建类的实例(new 的方式)。访问某个类或接口的静态变量,或者对该静态变量赋值,调用类的静态方法
- 反射的方式
- 初始化某个类的子类,则其父类也会被初始化
- Java虚拟机启动时被标明为启动类的类,直接使用java.exe命令来运行某个主类(包含main方法的那个类)
- 当使用JDK1.7的动态语言支持时(....)
所以说:
- Java类的加载是动态的,它并不会一次性将所有类全部加载后再运行,而是保证程序运行的基础类(像是基类)完全加载到jvm中,至于其他类,则在需要的时候才加载。这当然就是为了节省内存开销。
17.一个网页从开始请求到最终显示的完整过程
1. 在浏览器中输入网址;
2. 发送至DNS服务器并获得域名对应的WEB服务器的IP地址;
3. 与WEB服务器建立TCP连接;
4. 浏览器向WEB服务器的IP地址发送相应的HTTP请求;
5. WEB服务器响应请求并返回指定URL的数据,或错误信息,如果设定重定向,则重定向到新的URL地址。
6. 浏览器下载数据后解析HTML源文件,对数据进行渲染
18.NIO的实现方式
通过NIO核心组件:Channel,Buffer,Selector
三者的关系
Buffer 使用数组的方式不够灵活且性能差,Java NIO的缓冲区功能更加强大;容量(capacity)表示缓冲区的额定大小,需要在创建时指定(allocate静态方法);读写限制(limit)表示缓冲区在进行读写操作时的最大允许位置;读写位置(position)表示当前进行读写操作时的位置;缓冲区的很多操作(clear、flip、rewind)都是操作limit和position的值来实现重复读写;用于和NIO Channel交互,我们从Channel中读取数据到buffer里,从buffer把数据写入到channel,buffer本质上就是一块内存区
channel 表示为一个已经建立好的支持I/O操作的实体(如文件和网络)的连接,在此连接上进行数据的读写操作,使用的是缓冲区来实现读写。
Selector(多路复用器)通过一个专门的选择器(Selector)来同时对多个套接字通道进行监听;当其中的某些套接字通道上有它感兴趣的事件发生时,这些通道就会变为可用状态,可以在选择器的选择操作中被选中;
Channel读取数据存放到Buffer上,从Buffer将数据写入到channel上,Channel将自己注册到Selector上,指定监听的事件。当对应事件发生时,channel就可以进行相应的操作
19.redis的String跟hash的数据结构
set 就是普通的已key-value 方式存储数据,可以设置过期时间。时间复杂度为 O(1),每执行一个 set 在redis 中就会多一个 key
hset 则是以hash 散列表的形式存储。超时时间只能设置在 大 key 上,单个 filed 则不可以设置超时,它内部存储的Value为一个HashMap
应该使用 set 存储单个大文本非结构化数据 hset 则存储结构化数据
一个 hash 存储一条数据,一个 filed 则存储 一条数据中的一个属性,value 则是属性对应的值。
例如 数据库中有一张表 user 包含 id,name,age,sex 4个属性,并且有400w条数据,
id,name,age,sex
1、1,张三,16,1
2、2,李四,22,1
如果要整表缓存到 redis 中则使用 hash ,一条数据一个hash 一个hash 里则包含4个filed。
hset user_1 id 1 name 张三 age 16 sex 1
hset user_2 id 2 name 李四 age 16 sex 1
这样存储,如果用户的某个属性值改变,还可以单个修改。
例如 把张三的年龄改为30 则可以使用命令: hset user_1 age 30
我们简单举个实例来描述下Hash的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,会非常浪费内存
20.什么情况消息会进入MQ的死信队列
1.有消息被拒绝(basic.reject/ basic.nack)并且requeue=false
2.队列达到最大长度
3.消息TTL过期