【数据挖掘】关联规则之Relim算法
Relim算法
一种新的不需要候选项集的频繁项集挖掘算法——Relim算法
背景
FP-growth算法是当前挖掘频繁项集算法中速度最快,应用最广,并且不需要候选项集的一种频繁项集挖掘算法,但是FP-growth也存在着算法结构复杂和空间利用率低等缺点。Relim算法是在FP-growth算法的基础上提出的一种新的不需要候选项集的频繁项集挖掘算法。它具有算法结构简单,空间利用率高,易于实现等显著优点。
主要思想
Relim算法的主要思想和FP-growth相似,也是基于递归搜索(Recursive Exploration),但是和FP-growth不同的是:Relim算法在运行时不必创建频繁模式树,而是通过建立一个事务链表组(transaction lists)来找出所有频繁项集。
方法描述
为了更好地描述该算法,通过一个实例来说明Relim算法的挖掘过程。该例基于表一所示的事务数据集。数据集中有l0个事务。设最小支持度为3(即min sup=3/10=30% )。

Relim算法的挖掘过程如下:
(1)与Apriori算法相同,首先对数据集(表一), 进行第一次扫描,找出候选1 项集的集合,并得到它们的支持度计数(频繁性)。然后,按照支持度计数递增排列各项集,如表二所示。
(2)扫描表一,将支持度小于最小支持度3的元素(表二中的元素g和f)从各事务中消除,然后根据元素的支持度计数递增地将表一中的事务重新进行排列,如表三所示。注意:事务元素的排列顺序不会影响挖掘结果,但对运行速度有影响。递增排列,运行速度最快;反之则最慢。
(3)为表三所示的事务数据集中的所有元素都创建一项单向数据链表,并且使每个元素的数据链表都包含一个计数器和一个指针。计数器的值表示在表三中以此元素为头元素的事务总数,称之为头元素数值。指针则用于保存表三中相关事务的关联信息,因此元素的数据链表也被称为事务链表(transaction list)。把所有事务链表按照表二中元素支持度的计数递增排列,由此就创建了一组事务链表,称之为事务链表组(transaction lists),如图1所示。

(4)按照元素支持度计数由小到大的顺序,首先扫描以e元素为头元素的事务链表(简称为e事务链表),如发现该链表中有项集的支持度大于或等于最小支持度3,就将此项集输出。在e事务链表中,只有项集{e}的支持度等于3,所以,将{e}输出。扫描完后,将e事务链表的头元素数值设为零,并将e事务链表从链表组中删除。
(5)创建一个和第3)步描述的结构相似的单向数据链表组,链表组保存着将e事务链表的头元素除掉后,其后继元素作为头元素的事务关联信息。这个数据链表组在本文中称之为前缀e事务链表组。如图2所示。

(6)将前缀‘e事务链表组和e事务链表为空的事务链表组进行合并,得到一个新的事务链表组。如图3所示。

(7)根据(4),(5),(6)步所述,递归地对新事务链表组中的第二个事务链表(即a事务链表),进行挖掘。其挖掘结果是:{a},{a,b},{a,b,d},{a,d}的支持度都大于最小支持度3,将其结果输出。
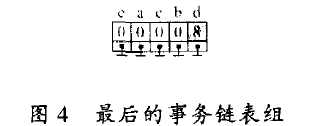
(8)当挖到最后一个事务链表的时候,事务链表组如图4所示。该事务链表的计数器的值为8而链表指针指向空。输出频繁项集{d}后,结束频繁项集的挖掘。
Relim算法的挖掘过程
算法:Relim通过建立一个事务链表组,用递归消除的方式来挖掘频繁项集。
输入:事物数据集D;最小支持度阙值min_sup。
输出:D 中的频繁项集。
方法:
1)扫描事务数据集D,找出频繁1项集和它们的支持度,并按支持度大小递增排列。然后,对于D 中每个事务,执行如下操作后得到新的事物数据集D’ :
删除频繁1项集以外的元素.并按支持度大小递增排列元素。
2)将D’ 转换成一个事务链表组TLs。该事务链表组中的各项事务链表TL保存着头元素相同的各事务的相关信息,并且接头元素支持度大小递增排列。
3)按头元素支持度大小递增排列顺序,依次对TLs中的每个TL进行如下操作:
a)递归地扫描该事务链表,找出频繁项集并输出。
b)将该事务链表从TLs中删除,并创建以该事务链表头元素为前缀的事务链表组TLs’
c)合并TLs和TLs’,得到新的事务链表组TLs。(TLs+TLs’ —>TLs)
4)挖掘完最后一个事务链表后,结束频繁项集的挖掘。
扩展:Relim算法和FP-growth算法的性能比较
1)算法结构:由以上所述,显而易见Relim算法的结构比FP-growth算法简单。该算法没有复杂的数据结构,因而易于实现。
2)空间利用率:FP-growth算法主要是通过建立频繁模式树来实现关联规则挖掘。频繁模式树从挖掘开始时建立,一直到挖掘结束时都完整地保存在内存里。而Relim算法主要是通过建立事务链表组来实现挖掘的,事务链表组中的事务链表依次地被挖掘。当一个事务链表中的关联项集被挖掘完后,此事务链表就被删除,所占的内存空间也就被释放。由此可见,Relim算法的空间利用率比FP-growth算法的要高很多。
3)运行速度:Relim算法的运行速度与FP-growth算法相比并不慢,而且当对最小支持度高或者频繁规则比较少的数据集进行挖掘时,Relim算法的运行速度往往比FP-growth算法要快。由此,对最小支持度高或者频繁规则比较少的数据集进行数据挖掘时,用Relim 算法可以节约大量的运算时间。
4)计算复杂度:Relim算法在挖掘长模式的数据库时计算复杂,因此,只适合于挖掘短模式的数据库。如果,要将其用于长模式的数据库挖掘,则通过数据库分解方法将长模式变成短模式可能是一个可行的方法。