技术分享 | MyCat的坑如何在分布式中间件DBLE上改善(内含视频链接)
作者简介
蓝寅,开源分布式中间件DBLE项目负责人;持续专注于数据库方面的技术, 始终在一线从事开发;对数据复制,读写分离,分库分表的有深入的理解与实践。
3月14日,爱可生开源社区联合IT168发布了一期《MyCat的坑如何在分布式中间件DBLE上改善》的直播,根据反馈,现将直播内容节选成文,以供大家回顾重温。
Tips:考虑到大家的不同口味,开源社区官网上线了完整版录播视频,无论是喜欢文字,爱好图文,青睐于完整版视频的同学都能找到自己喜欢的打开方式!
直播视频回顾请点击“ 录屏”,一键直达。
“ 以下为分享内容的正文部分 ”
背景
近年来,随着移动互联网、物联网、人工智能等技术的兴起,需要处理的数据越来越多,作为存储架构核心的关系型数据库不可避免的引发了需要扩容的问题,在这个过程中分库分表被发明出来。
分库分表最初不需要中间件,由各自应用的开发人员自己来负责,应用除了要了解业务逻辑以外,还需要明确完整的拆分规则,成本较高,对开发人员要求也很高,并且不利于任务和逻辑的解耦。因此,中间件应运而生。

分布式系统架构基本分成三层,最上面是一层是APP层,中间是中间件层,下面是数据存储层。
今天分享的内容主要为中间件,那么一个理想的中间件应该是什么样的?
第一,透明性,理想的中间件会向应用开发人员屏蔽后面具体拆分的细节。数据存储的工作被独立出来,应用开发人员可以更关注业务逻辑而不是存储方式。
第二,兼容性,理想的中间件最好是不要自定义一套规则,而是去兼容当前大家熟悉的规则,对我们来说,这个熟悉的规则就是MySQL。所以中间件的语法也好,协议也好,对于使用者来说,最好的是用户使用时就像使用原生MySQL一样,而不是需要花很长时间学习一套新的规则,否则无论是学习成本或者迁移成本都很高。
兼容性还有一个好处,现有的JDBC或者是其他的一些驱动都可以用,不需要再去定制开发一个驱动。
第三,性能,一般对性能的考量是延迟和吞吐量。因为中间件多了一层,单个查询的response会多一个RTT延迟,所以延迟方面不一定有优势。主要看吞吐量是不是变得比原来更强。
第四,安全,不能因为有了中间件而将原来完好的密码管理规则变成名存实亡的存在,这种做法也是不妥的。
最后,运维性,比如与中间件配套的备份扩容工具等,这方面组件也是很重要的。
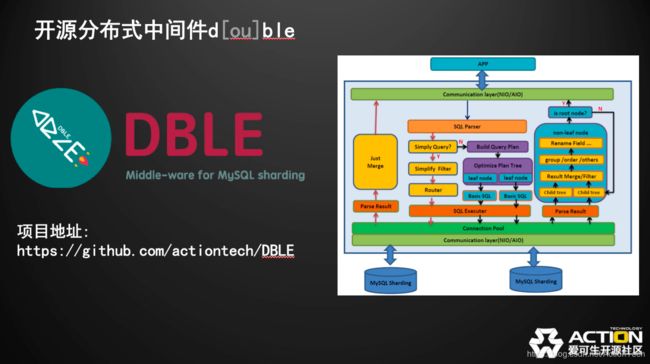
开源社区里MyCat的是比较著名的。我们深度研究了MyCat,加上我们在分布式中间件上既有的一些经验,结合起来,就是形成了我们新的一个开源分布式中间件DBLE。DBLE的结构大致如图,内部主要有协议,解析,路由和运算模块。
那么DBLE跟MyCat相比解决了哪些问题?以下将从DBA与研发两个方面介绍:
1.DBA的角度,站在DBA的角度,如何实现他们并不是太关心,对能用,好用十分关注,即:正确性,安全性,稳定性,可运维性等。本次分享主要关注于正确性,因为这是最大的坑,其他方面鉴于时长有限,不在这次分享中详细讲述了。
2.开发测试的角度,从开发测试的角度来看最关注的是代码质量,是否可维护,代码管理是否科学,能否持续报纸质量,保证项目健康发展。
首先我们从DBA角度分享一下在MyCat上踩的坑,当然,这些坑DBLE都填了,具体的实现方式欢迎大家关注我们正在陆续释放的公开课,会有更多的内容揭秘。
一.DBA角度看中间件
我们主要从两方面来讨论,一部分是SQL语言实现:包括select,insert,set等语句来说明正确性的问题,另一部分将举个运维管理的例子来说明安全性的问题。
1. SQL语言实现
以下案例都采用最新版的MyCat 1.6.7举例,在此之前分享过的一些MyCat的bug和坑,此次查看已经修了一部分,不过坑还是太多。
1.1数据查询
简单查询对比案例
从拆分规则来看,最常用的hash拆分,用ID值对1024求模,求出的结果0~1023按照每256个数拆分,拆成4份,0~255在结点1;256~511在结点2,以此类推。我们准备用10条数据,覆盖到各个分片上,都通过中间件写入。

准备完成之后,用查询语句案例select * from employee where id between 511 and 1791 order by id,加order by主要是为了更容易看出问题。
如图所示,在查询结果中MyCat丢了三条数据,原因是因为计算路由错误。像这样大范围查询的SQL应该下发给所有后端结点,而实际上MyCat下发的少了。
聚合函数查询案例
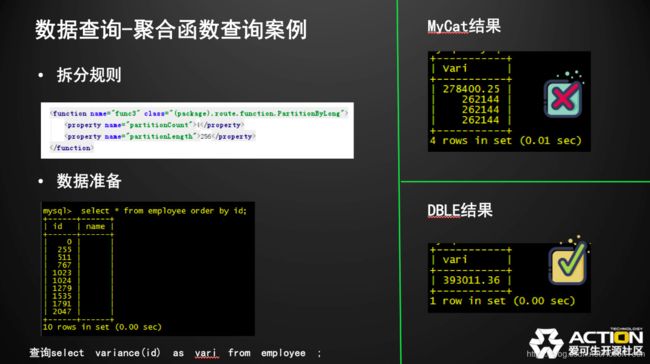
聚合函数查询案例的准备数据与简单查询类似,在此不赘述了,我们计算出ID的方差,可以看到MyCat返回的是四个数,并且这4个数无论如何也不可能捏回标准差,而DBLE的结果是正确的。当然,有同学验证的话会发现有细微的精度误差,这是因为二进制存储会损失一些精度,分布式的算法又会损失一些精度,因此会有精度上的误差。
数据查询-函数嵌套查询案例
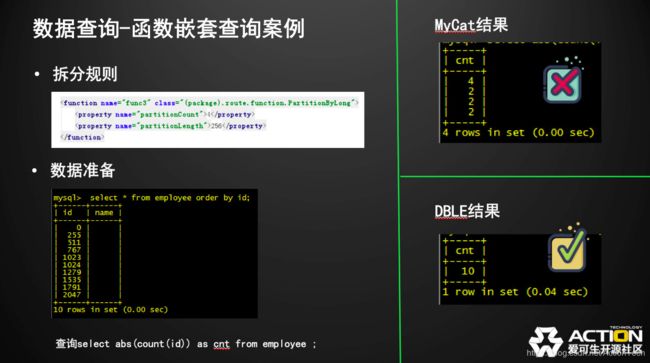
继续举例,准备数据不变,SQL变成了复杂一点的表达式,对count的结果取绝对值。可以看到MyCat是支持count的,但是前面去嵌套了一个其他的函数,MyCat就不认识了,它把整个语句下发给各个节点,然后对各个节点做了简单合并,这个合并没有加起来,只是简单的堆积在一起,然后回到了应用;而DBLE结果正确无误。
数据查询 - union 查询案例
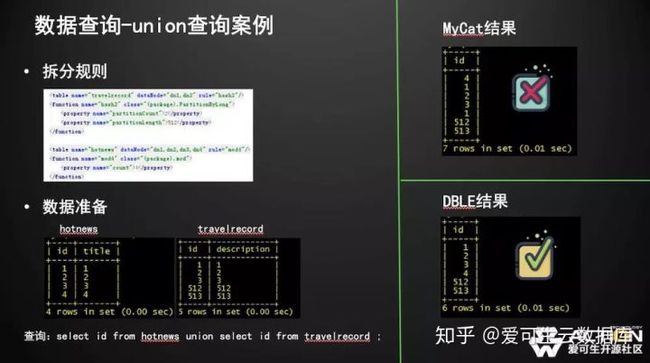
union查询案例的结果,数据准备如图是简单的两张表,一张表hotnews分为四个节点,规则也很简单,就是对四求模,按照求模的结果拆分到了四个节点上。另一张表travelrecord稍微复杂一点,是两个节点,它的规则是按1024次求模,然后0到511分到第一个节点,512到1023分到第二个节点。第一张表是四行数据,第二张表是五行数据。这个例子已经能说明问题了,现实生活中情况可能更复杂一些。
查询:select id from hotnews union select id from travelrecord 语句,即用ID做一个union,如图所示,MyCat的结果并没有去重,把所有的结果都拿到了。对比之下DBLE的结果则是正确的。
数据查询 - union all 查询案例

在union all的查询案例中,MyCat的查询结果还是和union一样。因为MyCat在union查询时是将union语句整体下发到各个节点上,而在计算时则是按照hotnews这张表来计算节点,由于MyCat只把查询下发给两个节点,拿到的结果其实是不全的。
数据查询 - 子查询

子查询对比结果有三个,MyCat会直接hang住。看代码hang住的原因是MyCat内部死锁。中间件在做子查询任务时,其实是拿到子查询结果以后再拼出新的SQL来,然后再下发第二句SQL。
在这个过程中,MyCat 固定大小的线程池被占满了,造成了死锁,而DBLE结果还是正确的。
数据查询 - Join案例

重点讨论一下Join,MyCat解决跨表Join的方式有3种:配置global表,配置ER表,使用hint,下面一一剖析,看看是否是真的能解决所有问题。
数据查询 - Join案例 剖析global表

对于数据量不大的字典表可以采用global表。举例,超市的几十万商品表,销售详单非常多,拆表时往往选择拆数据最多的销售详单表,假设按照日期,将销售详单拆分,按天将详单表拆成N片,在每一片的schema中有一个全量的商品表,即全局表。
当进行销售详单和商品表的Join查询的时,之所以用Join,是因为详单里面只有ID没有商品名称,进行Join查询时才能拿到名称,Join查询时Join语句下发到各个节点,而各个节点上的全局表都是全量数据,因此Join可以拿到正确的数据,这就是全局表的作用。

举一个具体例子,将商品表和销售详单表通过商品ID来关联,在一定时间范围内,根据group by日期和商品名,查看订单量。
这样一句Join,因为group by中包含了拆分列,所以这条语句可以下推给所有节点,这些节点得到的结果,直接简单的进行合并,返回到客户端就是正确的数据,这是global表的正确用法。
global表能不能解决所有的问题呢?答案是不行。

举例说明,在这个case中,在query里,首先group by并不是按照拆分列去分组,其次select row里面有count distinct的过程,这句SQL,如果下发到各个节点,会发生什么样的情况?

如图,第一个分片上得到的日用品和文具是一和二,第二个节点上得到的也是。
但如果把左边的图不看成拆分表,大家应该对distinct都非常熟悉,可以自己试着用group by做一下,结论应该会是日用品一文具三,通过两个节点得到的结果分别是一和二,无论怎么合并,也无法合出第三个这样的结果。
所以这就是global表解决不了的问题,当碰到这样的查询时global表就无法解决,因此它不能解决所有问题。
数据查询 - Join案例 剖析ER表

ER表可以简单地理解为两张表有逻辑外键关系,按照这列来拆分,几张表都可以按照同样一个规则拆分。涉及到了关联列的Join,也可以同样下发到各个节点上。
注意,外键列需要依赖于拆分列,不能有拆分列和外键列是1比N的关系。

再举例,按照销售单的日期拆分,流水号和日期有一一对应关系,不会出现一个流水号有两个日期。根据流水号去拆分另一张表,拆分完之后,如果这两张表通过流水号关联做Join,可以直接到下发到各个节点。
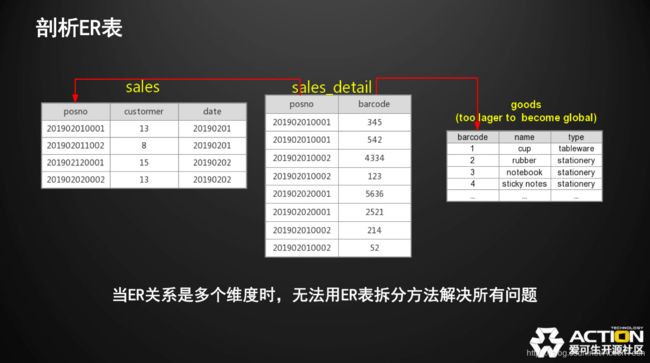
ER表是万能的吗?
假如不是所有表的关联关系都是同一列,当关联关系比较复杂,A表和B表是通过关联列COLUMN1来关联,B表和C表是通过COLUMN2来关联,会发现无论用哪种方式去做拆分,都无法得到一个完美的拆分方案,一定会有一张表被打散。
打散之后再做Join,就又回到了跨节点Join的问题。
跨节点Join的问题,把语句直接分发到各个节点是不正确的。
因此,ER表也不能解决所有问题。
数据查询 - Join案例 剖析Hint

MyCat解决跨表Join的第三个方法:注解。
举例说明,A表和B表在做Join的时候,前面加了一部分hint,在里面写好用哪个类来处理。
这其实就是next loopJoin的方式。如果通过MySQL的general log,或是根据debug去调试,就会发现这句Join在MyCat解析以后是分成两句下发的。
先从第一张表中select出结果集,再按照关联关系把结果集放在第二个表中拼接成新语句,然后再下发第二句SQL,MyCat实际是这样一个过程。
MyCat这种操作方式存在什么问题?
第一,解决不了多于两个表Join的问题。
第二,无法解决复杂Join语句的问题,只能解决A.id等于B.id这两个表格列关系直接相等的情况,稍微改变形式就不行。
第三,侵入性。应用的开发需要在每个Join下的每个查询前拼接这样一个hint,并且需要改应用,侵入性比较强。
所以hint表也解决不了所有的问题。
有趣的是MyCat 1.6.5之后,将hint方式直接固化到代码里,这样的处理方式实在不像是工程级别的代码,反而会引入更多的问题。

举例说明: 这个Join内部其实偷偷在代码中加了hint,如果是MyCat 1.6.1版本,直接结果不争取,加了hint以后有部分改善。根据测试, MyCat的反馈结果并不稳定,有时会返回NP异常并且这个NP异常会影响当前session的正确性。
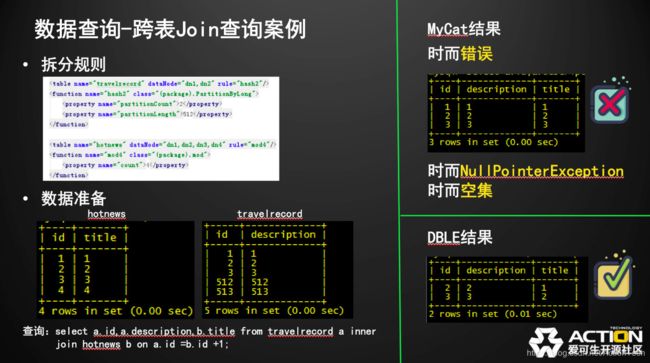
将SQL语句调整为查询:select a.id,a.description,b.title from travelrecord a inner join hotnews b on a.id =b.id;,B.id变成B.id+1,这句SQL,就无法返回正确结果了。受到前一个例子的影响,MyCat的查询结果非常不稳定,即使使用新的连接,也会只返回空集,因为MyCat本身只是把hint固化到代码里,并没有良好的跨表Join的实现。
Tips:
MyCat的内部实现十分粗糙,它判断是否要自己加hint采用的依据是拆分关的规则不一样。但是是否能做成ER关系有2个条件,是拆分规则以及分片结点的完全一致。
如果拆分规则相同,结点或结点顺序不同,返回来也是空集,此处就不举例说明了,感兴趣的同学可自行尝试验证。
1.2 数据操作
DBLE与MyCat的Insert对比
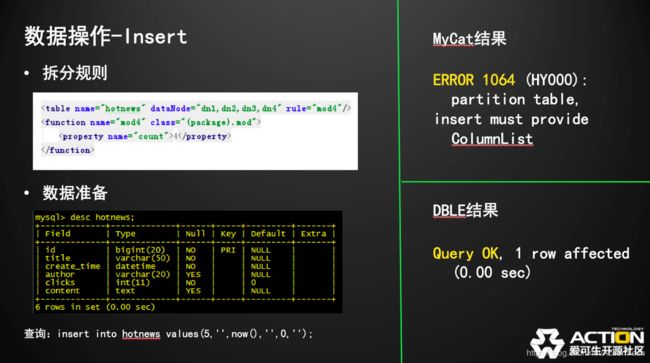
在Insert的处理上MyCat的insert必须将列名完全写清楚,否则会报列名没有提供。而DBLE则更良好的兼容了MySQL的语法。

MyCat某些时候会报告不正确的返回,比如insert拼写错误,它报错不会是语法错误,而是默默通过SQL语句,如果不仔细看行的影响数甚至都无法发现拼写错误。

MyCat的全局序列自定义了一个语法,必须是nextvalue for sth才可以插入。
这个语法,对应用的业务开发者而言侵入性是非常强的,需要对应用做很多无法兼容的改造。

同样是全局序列,DBLE的实现则比较优雅,支持不带自增列的插入,由中间件来生成自增列数据。
1.3 DBLE与MyCat的上下文变量

除了select和insert,以下将再列举部分系统变量的例子。
如图,表格中原来包含4条数据,现插入一行数据,然后将session的状态设置为只读,显示再继续增加一条数据也可以通过。
虽然能够通过select筛选出来,但实际上MyCat对于set read only并不支持并且没有任何报错。如果事先并没有了解MyCat这个功能缺陷或进行测试,这个问题是很难被发现的。

同样的案例,在DBLE中设置为只读后,再插入数据DBLE将会报错,如此才真正符合设置session级别变量的含义。
MyCat为什么会出现这种情况?

再举一个有趣的例子,如图MyCat对于 set you =me,set 1=2 也返回OK,似乎无所不能。 而DBLE则会诚实的告诉你,这个变量不支持。
在使用过程中,如果存在不小心写错的情况DBLE会提供明确的报错,而MyCat什么set都返回ok的问题根因后面将详述。
2.运维管理-用户权限


以管理端用户权限为例,任何数据库用户都可登录MyCat管理端进行高级操作,如:服务下线,修改配置等。因为缺乏对用户的分级,导致应用开发者本应只能进行查询或DML等基本权限,但却也可以进行服务下线类似的不安全操作,究其根源是项目开发者没有从权限管理的角度思考问题,也埋下了安全隐患。

在DBLE中,我们将此问题进行改进,对不同用户进行划分,普通用户不能直接登录管理端口进行操作,如图所示,普通用户尝试管理端口会遭到拒绝,更有利于安全。
以上的诸多案例都是站在DBA的角度来验证MyCat的正确性及其存在的问题,作为MyCat的增强版,DBLE更多的以使用者的视角对一款中间件应当具备的正确性,安全性,稳定性,可运维性等方面进行了深度系统性的考量并持续完善相应功能特性,同时,我们也吸取经验对MyCat既存的问题也进行了增强与改进。
二.开发者角度
下面将从开发者的角度来分析MyCat的代码质量,让大家对于这个开源项目有更充分的认识。
概括而言,MyCat存在以下四个问题:
- 代码修复质量差
- 代码半成品残留
- 部分提交者有灌水嫌疑
- 伪造实现
1.bug修复质量

首先,bug修复质量。MyCat bug #1194:在旧内存管理模式下,查询两个avg,会报超索引超出界限异常。

上图为MyCat bug #1194在GitHub上的截图,bug提供者发现bug和重现bug,包括描述bug的逻辑都非常正确,实际上在for循环里删除了数据元素,然后导致下一个去处理的时候报错越界。
在修复上,如图,红色部分为删除的代码,绿色部分为对应增加的代码,仔细观察可发现中间部分被注释起来,没有实际作用,最关键的部分在最下方,仍然是在for循环中remove某一个索引的值。
为什么这个修复结果却是修复成功?
细敲其逻辑,实际上是不正确的。原因在于for循环里采用的是int类型的包装类,此时从数组中remove的不是某个索引的值,而是remove这个包装类对象,数组中根本不存在这个对象,因此实际上没有remove任何内容,而真正生效的是标记黄色的部分,将它的size减了一。
这种操作歪打正着,比如原有四个数组,正常情况下是将第三和第四数组remove掉,但现在没有remove成功,然后通过size 4-1-1结果变成了2。这时再去遍历此数组是通过field count来遍历的,序号为第三和第四的数组尽管没有删掉,但效果却和已经删掉的相同了。
bug #1194的修复如果只进行测试会发现这个问题已经完美的解决了,但是作为开发者,我们对代码质量进行管理时会发现这样代码的存在十分奇怪,不但难以读懂难以理解并且很可能存在:为了性能放弃包装类改成Java的基本类型、int类型,bug就会被reopen。
2.代码半成品残留

上图为MyCat启动类的部分代码截图,从图中可了解这是一个switch case语句,case=0和case等于1。其中case 0初始化了一个buffer pool,然后初始化了total buffer size,做了这两件事情;而case 1除了大段注释外,只初始化了total buffer size,并没有初始化buffer pool。这会发生什么情况呢?

当pufferpooltype设置为1时,会发现MyCat启动以后,客户端根本连不上,然后日志里面也全是NP异常。作为著名开源软件,在它的启动类上就存在这样的残留代码,我们能够相信它的质量吗?
我们相信MyCat当初设计时应该也设计了不同的实现,但没完成,这至少说明了没有一个固定的开发团队就没有人去处理类似很容易被发现的问题。
3.代码灌水
我们在对MyCat做测试的时候,发现有部分代码覆盖率很低,于是去查看这部分代码实现了哪些功能。结果发现:代码质量非常高,但整个package都是从其他著名开源项目的某个版本copy过来的,当然也不算完全copy,还是有加部分注释的。
这部分代码除了被贡献者自己的单元测试使用外,没有被任何其他人使用。即使把整个package连带测试完全删掉,也不影响软件的任何功能。
可能这位贡献者把MyCat项目当作自己学习笔记的笔记本或是能够展示自己贡献了很多代码?具体原因不得而知,不过这样的代码贡献也能被合并到项目里来,实在匪夷所思。
4.伪造实现

前面我们列举了一个较为夸张的例子,写set you = me也显示成功执行。
set语句为什么会出现这种情况?从源码角度来看,MyCat枚举了几个特殊处理,比如 set names= utf8确实进行了处理。但除了枚举的几个特殊的例子,其他无论set什么,MyCat都直接返回OK,因此你会看到前面set you=me也会得到OK的结果,这对于应用端而言是相当不负责任的。
尤其是遇到真的有意义的set语句,但却没有实现其语义,很容易造成开发事故。
DBLE的自动化工具的引入

最后分享一下DBLE是如何进行代码管理和保证质量的,除了正常的review机制外,我们引入了很多自动化的工具,包括静态代码的分析工具,用于做代码规范的工具,可持续集成工具等。社区的travis CI会自动跑单元测试,如果代码变更发生错误,那么工具就会报错,这样也可以提高代码质量。
内外部使用的工具有稍许不同,我们内部用的可持续集成工具是go cd,自动化的测试方面我们用behave做了一些行为的比较测试,之后可能也会开源出来。还有测试代码覆盖率的工具,帮助我们发现测试的薄弱环节等等。
“正文完”
以上分享对一款中间件的正确性进行了详尽充分的解读,而“安全性、稳定性、可运维性”以及如何评估开源中间件的代码质量、代码管理等都将在"DBLE系列公开课"一一为大家拆分揭秘。
DBLE系列公开课
自3月15日起每周更新一节发布在「爱可生开源社区官网」,点击官网(http://opensource.actionsky.com)博客专栏,即可查看“DBLE系列公开课”。
直播视频回顾请点击“ 录屏”,一键直达。
开源分布式中间件DBLE
社区官网: https://opensource.actionsky.com/
GitHub主页: https://github.com/actiontech/dble
技术交流群:669663113
开源数据传输中间件DTLE
社区官网: https://opensource.actionsky.com/
GitHub主页: https://github.com/actiontech/dtle
技术交流群:852990221
