【论文研读】Category-level Adversaries for Semantics Consistent Domain Adaptation(cvpr2019)
原文链接:Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation
作者:Yawei Luo , Liang Zheng, Tao Guan , Junqing Yu , Yi Yang
一、背景知识介绍
1、语义分割:
1)定义:给定一张图片,对图片上的每一个像素点分类。
2)样本来源:昂贵的人工劳动所获得的大量密集像素级注释;另一种方法是使用模拟数据(如计算机生成的场景)
3)问题提出:使用模拟数据得到的图片与真实分割图像有不同的数据分布,通常称为域移位
2、无监督域适应(域迁移)
1)传统方法(TAN):对抗性学习,生成器被训练以产生混淆鉴别器的特征,判别器正确地分类两个域

即分类器将对于源域的样本判断为负类,目标域判断为正类。
总loss = Labv+Lseg
2)问题:当生成器完全骗过判别器时,它只是对齐了两个域的边际分布,而忽略了本地类别级别的分布转移

3、Co-training
1)定义:multi-view learning的一种,构造两个不同的分类器,利用小规模的标注语料,对大规模的未标注语料进行标注
2)思想:不用人工干涉,够从未标注的语料中自动学习到知识
3)算法:假设数据有两种特征表达,比如图像特征(X1, Y1)和文本特征(X2, Y2)。对于未标注数据同样有两种View。算法如下:
- 在标注集下,从(X1, Y1),(X2, Y2)分别训练得到两个个分类模型C1,C2
- 分别使用C1与C2对未标注数据进行预测
- 将C1所预测的前K个置信度最高的样本加入C2的训练数据集
- 将C2所预测的前K个置信度最高的样本加入C1的训练数据集
- 回到第1步
解释:
- 两种view的获得方式:dropout [33], consensus regularization [34] or parameter diverse
- 置信度:对于每次迭代的训练集可以得到一个已标注数据的概率分布(可以假设为正态分布),以此来评定未标注数据的分布是否贴近
作用:should capture the essential aspect of a pixel across the source and target domains,
二、类别级别的对抗性网络(CLAN)
1、网络框架:

1)generator G —— can be any FCN-based segmentation network
组成:feature extractor E 、two classifiers C1 and C2
ResNet-101、vgg16 based FCN8s
2)discriminator D —— CNN-based binary classifier with a fully-convolutional output
consists of 5 convolution layers with kernel 4 × 4 with channel numbers {64, 128, 256, 512, 1} and stride of 2.
Each convolution layer is followed by a Leaky-ReLU parameterized by 0.2 except the last layer.
add an up-sampling layer to the last layer to rescale the output to the size of the input map
2、loss
一共有三个loss:1)the segmentation loss, 2)the weight discrepancy loss ,3)the self-adaptive adversarial loss
1)segmentation loss(multi-class cross-entropy loss)
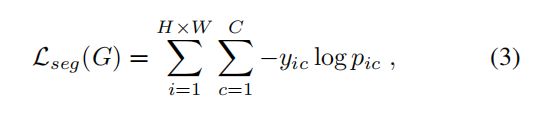
Pic denotes the predicted probability of class c on pixel i
Yic denotes the ground truth probability of class c on the pixel i.
If pixel i belongs to class c, yic = 1, otherwise yic = 0
2)the weight discrepancy loss —— minimizing cosine similarity of weights
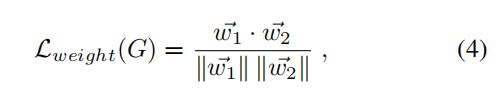
w1 and w2 are obtained by flattening and concatenating the weights of the convolution filters of C1 and C2
目的:保证C1 and C2的多样性,即两个不同的view
3)the self-adaptive adversarial loss

从标准无监督域适应的loss修改而来。
p(1) and p(2) are predictions made by C1 and C2
M(·, ·) denotes the cosine distance:保证从C1和C2中出来的预测map的一致性,计算时是pixel-pixel级
λlocal controls the adaptive weight for adversarial loss.
a small number ![]() :to stabilize the training process
:to stabilize the training process
猜测采用cosine的理由:

总的loss函数+训练:


三、实验
1、数据集
Cityscapes: a real-world dataset with 5,000 street scenes
GTA5: 24,966 high-resolution images compatible with the Cityscapes annotated classes.
SYNTHIA: 9400 synthetic images
迁移任务:SYNTHIA → Cityscapes、 GTA5 → Cityscapes
2、结果



source only:没有迁移,在源域训练后在目标域上预测
几个souce only:针对以下方法的backbone
效果图:

参考:http://www.sohu.com/a/256478531_100177858
https://www.cnblogs.com/lxy2017/p/4083352.html
https://www.cnblogs.com/lmsj918/p/4031651.html