机器学习之ROC曲线理解
ROC曲线
1、roc曲线
曲线的坐标分别为真正例率(TPR)和假正例率(FPR),定义如下:

真正例的个数是实际值为正例被预测成为正例的值得个数,TPR是预测结果中真正例占实际值中正例的比例;
反正例的个数是实际值为反例被预测成为正例的值得个数,FPR是预测结果中反正例占实际值中的反例的比例;
很多学习器是为测试样本是产生一个实值或概率预测,然后将这个预测值与一个分类阈值进行比较,若大于阈值分为正类,否则为反类,因此分类过程可以看作选取一个截断点。(通常截取点为0.5,大于0.5为正例,小于0.5为负例)
选择不同的截断点对结果的影响很大,截断点的取值区间是【0,1】,如果截断点靠近1,则被判断为正例的数量会变少;如果截断点靠近0,则被判断为正例的数量会变多。x轴的取值范围为【0,1】,x点代表FPR的概率;y轴的取值范围为【0,1】,y点代表TPR的概率
不同任务中,可以选择不同截断点,若更注重”查准率”,应选择排序中靠前位置进行截断,反之若注重”查全率”,则选择靠后位置截断。因此排序本身质量的好坏,可以直接导致学习器不同泛化性能好坏,ROC曲线则是从这个角度出发来研究学习器的工具。
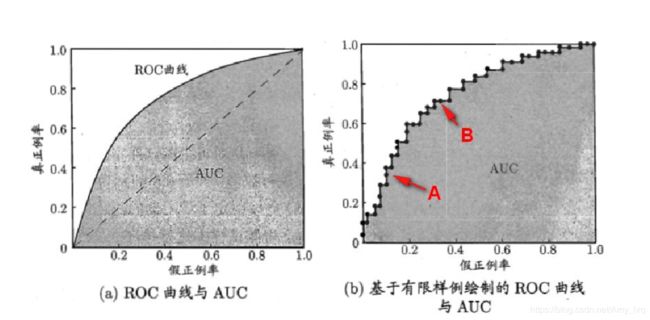
下图为ROC曲线示意图,因现实任务中通常利用有限个测试样例来绘制ROC图,因此应为无法产生光滑曲线,如右图所示。
 绘图举例:给定m个正例子,n个反例子,根据学习器预测结果进行排序,先把分类阈值设为最大,使得所有例子均预测为反例,此时TPR和FPR均为0,在(0,0)处标记一个点,再将分类阈值依次设为每个样例的预测值,即依次将每个例子划分为正例。
绘图举例:给定m个正例子,n个反例子,根据学习器预测结果进行排序,先把分类阈值设为最大,使得所有例子均预测为反例,此时TPR和FPR均为0,在(0,0)处标记一个点,再将分类阈值依次设为每个样例的预测值,即依次将每个例子划分为正例。
设前一个坐标为(x,y),若当前为真正例,对应标记点为(x,y+1/m),若当前为假正例,则标记点为(x+1/n,y),然后依次连接各点。
下面举个绘图例子: 有10个样例子,5个正例子,5个反例子。有两个学习器A,B,分别对10个例子进行预测:
A:[反正正正反反正正反反]
B : [反正反反反正正正正反]
计算A学习的点:
初始点位(0,0)
条件将所有的例子划分为正例
第一个“反”预测为正,即假正例,标记点(x+1/n,y)=>(1/5,0) => (0.2,0)
第二个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.2,1/5) => (0.2,0.2)
第三个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.2,1+1/5) => (0.2,0.4)
第四个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.2,2+1/5) => (0.2,0.6)
第五个“反”预测为正,即假正例,标记点(x+1/n,y)=>(1+1/5,0.6) => (0.4,0.6)
第六个“反”预测为正,即假正例,标记点(x+1/n,y)=>(2+1/5,0。6) => (0.6,0.6)
第七个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.6,3+1/5) => (0.6,0.8)
第八个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.6,4+1/5) => (0.6,1)
第九个“反”预测为正,即假正例,标记点(x+1/n,y)=>(3+1/5,1) => (0.8,1)
第十个“反”预测为正,即假正例,标记点(x+1/n,y)=>(4+1/5,1) => (1,1)
计算B学习的点:
起始点为(0,0)
第一个“反”预测为正,即假正例,标记点(x+1/n,y)=>(1/5,0) => (0.2,0)
第二个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.2,1/5) => (0.2,0.2)
第三个“反”预测为正,即假正例,标记点(x+1/n,y)=>(1+1/5,0.2) => (0.4,0.2)
第四个“反”预测为正,即假正例,标记点(x+1/n,y)=>(2+1/5,0.2) => (0.6,0.2)
第五个“反”预测为正,即假正例,标记点(x+1/n,y)=>(3+1/5,0.2) => (0.8,0.2)
第六个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.8,1+1/5) => (0.8,0.4)
第七个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.8,2+1/5) => (0.8,0.6)
第八个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.8,3+1/5) => (0.8,0.8)
第九个"正“预测为正,即真正例,标记点(x,y+1/m) =>(0.8,4+1/5) => (0.8,1)
第十个“反”预测为正,即假正例,标记点(x+1/n,y)=>(4+1/5,1) => (1,1)
A:y:[0,0,0.2,0.4,0.6,0.6,0.6,0.8,1,1,1]
x:[0,0.2,0.2,0.2,0.2,0.4,0.6,0.6,0.6,0.8,1]
B:y:[0,0,0.2,0.2,0.2,0.2,0.4,0.6,0.8,1,1]
x:[0,0.2,0.2,0.4,0.6,0.8,0.8,0.8,0.8,0.8,1]
绘制曲线结果如下:
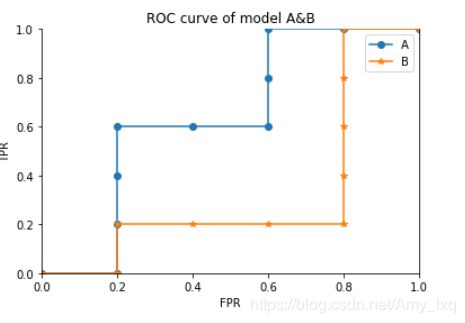
x轴代表假正例率,y轴代表真正例率,从上图可以看出A的y值上升的比较快,排序高的值要多于B,所以A的学习机更优。
AUC为ROC曲线下的面积,当A和B有交叉时,就要考虑A与B的面积。
参考
机器学习之ROC曲线
二战周志华《机器学习》-PR曲线和ROC曲线