CRF实现词性标注(2)——python代码说明
CRF原理说明请查看上篇博文
参考链接同上篇博文
- 定义CRF中的初始变量,包括特征函数, 特征函数的权重, 词性标注的label也就是状态序列,以及label_id字典。
def __init__(self, feature_functions, labels):
"""
:param feature_functions: 输入的特征函数
:param labels: 输入的训练数据标注
"""
# 特征函数
self.ft_func = feature_functions
# 特征函数的权值
self.w = np.random.rand(len(self.ft_func))
# labels
self.labels = labels
# label_id 的字典
self.label_id = {value: idx for idx, value in enumerate(self.labels)}
- 定义由输入序列得到所有特征的函数。
也就是对于输入的序列X= {x1, x2,…x3},得到每一个元素 x i x_{i} xi中 ( y j − 1 , y j ) (y_{j-1},y_{j}) (yj−1,yj)组合的所有特征 f k f_{k} fk
(1)先遍历所有的特征函数,得到组合 ( y j − 1 , y j ) (y_{j-1},y_{j}) (yj−1,yj)的所有特征函数;
(2)遍历y也就是labels,得到 j-1时刻 y j − 1 y_{j-1} yj−1的下一时刻的所有可能 y
(3)遍历labels得到所有可能的 y j − 1 y_{j-1} yj−1
(4)输入序列的长度为T, 得到每一个时刻 t ∈ ( 0 , T ) t \in(0,T) t∈(0,T)的所有特征。
def get_all_features(self, x_vec):
"""
:param x_vec:输入的观测序列
:return: x_vec序列中所有(y',y)组成的特征值
result size:[len(x_vec)+1, Y, Y, K]
Axes:
0: 观测序列长度T or
1:y' or 前一个位置的label
2:y or 当前位置的label
3:f(y',y,x,i)
"""
result = np.zeros(len(x_vec) + 1, len(self.labels), self.labels, self.ft_func)
for i in range(len(x_vec) + 1):
for j, yp in enumerate(self.labels):
for k, y in enumerate(self.labels):
for l, f in enumerate(self.ft_func):
result[i, j, k, l] = f(yp, y, x_vec, i)
return result
两个辅助函数计算特征矩阵和前向/后向向量的乘计算
def log_dot_mv(logM, logb):
"""
矩阵乘向量
:param logM: 矩阵,本项目中特征矩阵的取对数
:param logb: 向量,本项目中后向向量取对数
:return:
说明 利用scipy中的logsumexp()函数计算,等价于log(M点乘b)
"""
# np.expand_dims(x, axis=0) 转换为行向量
# np.sum(x, axis=1) 对矩阵的每一行相加
# logsumexp(x, axis=0/1) = np.log(np.sum(np.exp(x), axis=0/1))
return special.logsumexp(logM + np.expand_dims(logb, axis=0), axis=1)
def log_dot_vm(loga, logM):
"""
向量乘矩阵
:param loga:
:param logM:
:return:
"""
return special.logsumexp(np.expand_dims(loga, axis=1) + logM, axis=0)
- 计算前向向量

将前向向量和特征函数矩阵都进行了对数化,这样累乘计算也就转化为了累加计算,减小了计算量~~
借助scipy包中的logsumexp函数计算,具体的累乘怎么转换成对数累加的请参考后向向量中的推导
def forward(self, log_M_s, start):
"""
:param log_M_s: 特征函数矩阵取对数
:param start: 在状态序列添加的start
:return: 前向向量矩阵
初始化 alpha_0 = 1, if y = start ;else 0
取对数之后为:alpha_0 = log 1 = 0 if y=start else log 0 = -inf
alpha size: 因为添加了一维start,假设特征矩阵维度(m,m),那么alpha维度(m+1,m)
"""
T = log_M_s.shape[0]
Y = log_M_s.shape[1]
alphas = np.NINF * np.ones((T + 1, Y))
alpha = alphas[0]
# log 1 = 0
alpha[start] = 0
for t in range(1, T + 1):
alphas[t] = log_dot_vm(alpha, log_M_s[t - 1])
alpha = alphas[t]
return alphas
- 计算后向向量


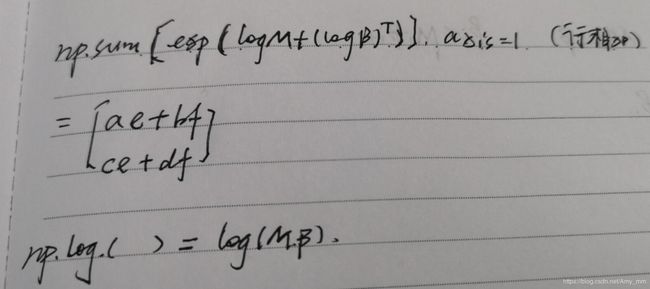
def backfarward(self, log_M_s, end):
"""
:param log_M_s:
:param logb:
:return:
"""
T = len(log_M_s.shape[0])
Y = len(log_M_s.shape[1])
betas = np.NINF * np.ones(T + 1, Y)
beta = betas[-1]
beta[end] = 0
for t in range(T - 1, -1, -1):
betas = log_dot_mv(log_M_s[t + 1], beta)
beta = betas[t]
return betas
- 对于输入的X序列和Y序列转换为CRF需要的观测序列observations和状态序列labels
def creat_vector_list(self, x_vecs, y_vecs):
"""
:param x_vecs:输入的x(词语)
:param y_vecs:输入的y(词性labels)
:return: 观测序列和labels
"""
print('create observation and label list')
print('total training data :', len(x_vecs))
observations = [self.get_all_features(x_vec) for x_vec in x_vecs]
labels = [None] * len(y_vecs)
for i in range(len(y_vecs)):
assert (len(y_vecs[i]) == len(x_vecs[i]))
# 加入start和end,借助CRF的矩阵形式建模
y_vecs[i].insert(0, START)
y_vecs[i].append(END)
labels[i] = np.array([self.label_id[y] for y in y_vecs[i]], copy=False, dtype=np.int)
return observations, labels
- 对数似然函数以及对权重求偏导数
def neg_likelihood_and_deriv(self, x_vec_list, y_vec_list, w, debug=False):
"""
求负的对数似然函数,以及似然函数对权重w的导数
:param x_vecs:
:param y_vecs:
:param w:
:param debug:
:return:
"""
# 初始化
likelihood = 0
derivative = np.zeros(len(self.w))
# 对观测序列X中的每一个位置
for x_vec, y_vec in zip(x_vec_list, y_vec_list):
all_features = x_vec
length = x_vec.shape[0]
# 下边代码中的y_vec = START + y_vec + END
yp_vec_ids = y_vec[:-1]
y_vec_ids = y_vec[1:]
# log_M_s: len(x_vec)+1, Y, Y
log_M_s = np.dot(all_features, w)
# alphas: len(x_vec)+2, Y
log_alphas = self.forward(log_M_s, self.label_id[START])
last = log_alphas[-1]
# betas: len(x_vec)+2, Y
log_betas = self.backfarward(log_M_s, self.label_id[END])
# Z = alpha[-1](x)*1 = 1*beta[0]
log_Z = special.logsumexp(last)
# reshape alphas的个子序列变为列向量,beta的,每一个子序列变为行向量
log_alphas1 = np.expand_dims(log_alphas[1:], axis=2)
log_betas1 = np.expand_dims(log_betas[:-1], axis=1)
# log_probs : len(x_vec)+1, Y, Y
log_probs = log_alphas1 + log_M_s + log_betas1 - log_Z
log_probs = np.expand_dims(log_probs, axis=3)
# 计算特征函数关于模型的期望,也就是关于条件概率P(Y|X)的期望
# ,axis=(0,1,2)表示在所有维度上都相加,最后得到一个数
exp_features = np.sum(np.exp(log_probs) * all_features, axis=(0, 1, 2))
# 计算特征函数关于训练数据的期望,也就是关于联合分布P(X,Y)的期望
emp_features = np.sum(all_features[range(length), yp_vec_ids, y_vec_ids], axis=0)
# 计算似然函数
likelihood += np.sum(log_M_s[range(length), yp_vec_ids, y_vec_ids]) - log_Z
# 计算偏导数 ???
derivative += emp_features - exp_features
return -likelihood, -derivative
- CRF模型训练
借助scipy的opitimize函数进行模型训练
def train(self, x_vecs, y_vecs, debug=False):
"""
:param x_vecs:
:param y_vecs:
:param debug:
:return:
"""
vectorized_x_vecs, vectorized_y_vecs = self.creat_vector_list(x_vecs, y_vecs)
print('start training')
l = lambda w: self.neg_likelihood_and_deriv(vectorized_x_vecs, vectorized_y_vecs, w)
#
val = optimize.fmin_l_bfgs_b(l, self.w)
if debug:
print(val)
self.w, _, _ = val
return self.w
- viterbi算法预测
def predict(self, x_vec, debug=False):
"""
Viterbi算法预测
:param x_vec:
:param debug:
:return:
"""
# all_features: en(x_vec) + 1, Y, Y, K
all_features = self.get_all_features(x_vec)
# 非规范化概率 = w*feature
log_potential = np.dot(all_features, self.w)
T = len(x_vec)
Y = len(self.labels)
# Psi 保存每个时刻最优路径的下标
Psi = np.ones((T, Y), dtype=np.int32) * -1
# viterbi算法的初始化
delta = log_potential[0, 0]
# 递推
for t in range(1, T):
next_delta = np.zeros(Y)
for y in range(Y):
# t:第t时刻的子序列;y:第yi个label
# log_potential[t, :, y]表示第t时刻第y个label的权重w
w = delta + log_potential[t, :, y]
Psi[t, y] = psi = w.argmax()
next_delta[y] = w[psi]
delta = next_delta
# 回溯最优路径
y = delta.argmax()
trace = []
for t in range(T-1, -1, -1):
trace.append(y)
y = Psi[t, y]
trace.reverse()
return [self.labels[i] for i in trace]
- 进行词性标注
from crf import *
from collections import defaultdict
import re
import sys
def get_feature_functions(word_sets, labels, observes):
"""生成各种特征函数"""
print("get feature functions ...")
transition_functions = [
lambda yp, y, x_v, i, _yp=_yp, _y=_y: 1 if yp == _yp and y == _y else 0
for _yp in labels[:-1] for _y in labels[1:]
]
def set_membership(tag, word_sets):
def fun(yp, y, x_v, i):
if i < len(x_v) and x_v[i].lower() in word_sets[tag]:
return 1
else:
return 0
return fun
observation_functions = [set_membership(t, word_sets) for t in word_sets]
misc_functions = [
lambda yp, y, x_v, i: 1 if i < len(x_v) and re.match('^[^0-9a-zA-Z]+$', x_v[i]) else 0,
lambda yp, y, x_v, i: 1 if i < len(x_v) and re.match('^[A-Z\.]+$', x_v[i]) else 0,
lambda yp, y, x_v, i: 1 if i < len(x_v) and re.match('^[0-9\.]+$', x_v[i]) else 0
]
tagval_functions = [
lambda yp, y, x_v, i, _y=_y, _x=_x: 1 if i < len(x_v) and y == _y and x_v[i].lower() == _x else 0
for _y in labels
for _x in observes]
return transition_functions + tagval_functions + observation_functions + misc_functions
if __name__ == '__main__':
word_data = []
label_data = []
all_labels = set()
word_sets = defaultdict(set)
observes = set()
for line in open("sample.txt",encoding='utf-8'):
# print(line)
words, labels = [], []
for token in line.strip().split():
word, label = token.split('/')
all_labels.add(label)
word_sets[label].add(word.lower())
observes.add(word.lower())
words.append(word)
labels.append(label)
word_data.append(words)
label_data.append(labels)
labels = [START, END] + list(all_labels)
feature_functions = get_feature_functions(word_sets, labels, observes)
crf = CRF(labels=labels, feature_functions=feature_functions)
crf.train(word_data, label_data)
for x_vec, y_vec in zip(word_data[-5:], label_data[-5:]):
# print("raw data: ", x_vec)
print("prediction: ", crf.predict(x_vec))
print("ground truth: ", y_vec)
pre_res = crf.predict(x_vec)
y_vec_ = y_vec[1:-1]
length = len(y_vec_)
print(len(pre_res), len(y_vec_))
s = 0
for i in range(length):
s += (pre_res[i] == y_vec_[i])
print(s/length)
后边代码的详细讲解有时间在写上,代码参考链接同上篇博文~~
感谢大佬分享。