OpenCV4Android开发实录(3):数字图像基础与OpenCV开发入门
转载请声明出处:https://blog.csdn.net/AndrExpert/article/details/79889136
俗话说:“工欲善其事,必先利其器”。数字图像处理作为专业性比较强的一门学科,也是计算机视觉的基础课程,在开始学习
OpenCV处理数字图像之前,我觉得对数字图像有一定的了解还是非常有必要的,尤其是对于没有任何数字图像基础的人。拥有扎实的数字图像基础,将是深入研究OpenCV框架的一把利器!
1. 数字图像基础
数字图像,又称数位图像(位图),由模拟图像数字化得到,它以像素为基本元素,是二维图像用有限像素的表示。通俗的说,数字图像在计算机中是以数值矩阵的形式存在和处理,矩阵的每一个元素即为像素。下图表示一副黑白图像所对应的矩阵,每一个小方块代表黑白图像的一个像素,在矩阵中值为0或1。

1.1 像素与灰度级
像素是组成数字图像最基本元素,是数字图像显示的基本单位,它是一个逻辑尺度单位,比如一张640x480大小图片,它由横向640个像素和纵向480个像素组成。每个像素都拥有数字值,不同的图像种类像素值的范围有所区别,比如二值图像(黑白图像)像素数值只能为0或1、灰度图像像素数值为0~255。下图表示图片中每一个正方形为一个像素:

除了像素,在实际开发中,我们可能还会碰到诸如图像的灰度、灰度值、灰度级和灰度级数等概念,它们也算是数字图像处理的重要基础。所谓图像的灰度、灰度值或灰度级实质是同一个概念,为表示一个像素明暗程度的整数,范围为0~255,其中,纯白为255,纯黑为0,中间值为介于纯黑和纯白之间的灰色。由于一副数字图像由若干个像素组成,而每个像素拥有自己的灰度值(注:RGB彩色图像只有R=G=B,像素的值才能称为灰度值,否则为颜色值),因此一副图像拥有若干不同的灰度级(灰度值),这些灰度级集中起来便成为该图像的灰度级数。灰度级数代表一副数字图像的层次,图像数据的层次越多,视觉效果就越好。下图为一副灰度图像及其灰度值(像素值)表示:

1.2 分辨率
通常,分辨率可分为屏幕分辨率、图像分辨率、视频分辨率,它们有一个共同特征,即包含的像素数量越多,图像画面的显示就越清晰、细腻,主要区别如下:
- 屏幕分辨率
屏幕分辨率就是计算机显示器或移动设备的屏幕上能显示像素的个数,通常以水平和垂直像素数量来衡量。这里以华为P20 Pro为例,它的主屏分辨率为2240x1080像素,表示该机型屏幕水平方向上能够显示2240个像素,垂直方向能够显示1080个像素,总共2419200个像素(>200万),可以说华为P20 Pro屏幕分辨率是相当高的,当然屏幕的显示也就非常清晰。
- 图像分辨率
图像分辨率就是图像的尺寸,也成为图像的宽和高,即图像水平方向上的像素个数和垂直方向上的像素个数。比如一张分辨率为640×480像素的图片,有480行像素信息,每行有640个像素,该图片包含的像素个数是307 200,也就是我们常说的30万像素。而一个分辨率为1600×1200像素的图片,就达到了约200万的像素。
- 视频分辨率
现实生活中,对于视频分辨率我们习惯性用标清、高清、超清或者480P、720P、1080P来形容,这里所谓的P指的是逐行扫描,480P是表示的是视频中画面的分辨率为640x480像素,也就是说,视频中每一副画面由水平方向上的640个像素和垂直方向上的480个像素组成,每扫描一行就会遍历480个像素。
1.3 颜色空间
根据数字图像色彩表示方式的不同,数字图像有几种不同的颜色空间(颜色模型),如RGB颜色空间、HSV颜色空间、YUV颜色空间等。下面就具体介绍一下这几种颜色空间:
- RGB
RGB色彩模式是工业界的一种颜色标准,是通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色,这个标准几乎包括了人类视力所能感知的所有颜色,是目前运用最广的颜色系统之一。RGB色彩模式使用RGB模型为图像中每一个像素的RGB分量各占8bits,且分配一个0~255范围内的强度值。例如:纯红色R值为255,G值为0,B值为0;灰色的R、G、B三个值相等(除了0和255);白色的R、G、B都为255;黑色的R、G、B都为0。RGB图像只使用三种颜色,就可以使它们按照不同的比例混合,在屏幕上重现16777216(2^24)种颜色。
- YUV
YUV颜色空间是欧洲电视系统使用的一种色彩编码空间,在现代的彩色电视系统中,通过三管彩色摄影机和彩色CCD摄影机得到的彩色图像信号,经过分色、分别放大校正得到RGB,再进一步经矩阵变换电路得到亮度信号Y和两个色差信号U、V,最后发送端对这三个信号分别编码,再使用同一信道发出去,这就是YUV颜色空间。


彩色电视采用YUV空间正是为了用亮度信号Y解决彩色电视机与黑白电视机的相容问题,使黑白电视机也能接收彩色电视信号。YUV主要用于优化彩色视频信号的传输,使其向后兼容老式黑白电视。与RGB视频信号传输相比,它最大的优点在于只需占用极少的频宽(RGB要求三个独立的视频信号同时传输)。其中“Y”表示明亮度(Luminance或Luma),也就是灰阶值;而“U”和“V”表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。“亮度”是透过RGB输入信号来建立的,方法是将RGB信号的特定部分叠加到一起。“色度”则定义了颜色的两个方面─色调与饱和度,分别用Cr和Cb来表示。其中,Cr反映了RGB输入信号红色部分与RGB信号亮度值之间的差异;而Cb反映的是RGB输入信号蓝色部分与RGB信号亮度值之同的差异。采用YUV色彩空间的重要性是它的亮度信号Y和色度信号U、V是分离的。如果只有Y信号分量而没有U、V分量,那么这样表示的图像就是黑白灰度图像。彩色电视采用YUV空间正是为了用亮度信号Y解决彩色电视机与黑白电视机的兼容问题,使黑白电视机也能接收彩色电视信号。YUV相关色彩模型与RGB的转换方程如下:
YUV和YCbCr区别:YCbCr是DVD、摄像机、数字电视等产品中常用的色彩编码方案,它是YUV经过缩放和偏移的进化种类,由亮度分量Y、蓝色色度分量Cb和红色色度分量Cr组成,其中Y与YUV中的Y含义相同,Cb、Cr与YUV中的U、V均指色彩,只是表示方法上不同。在计算机系统中应用广泛,JPEG、MPEG均采用此格式,并且我们所说的YUV颜色格式大多指YCbCr。RGB到YCbCr的转换公式如下:

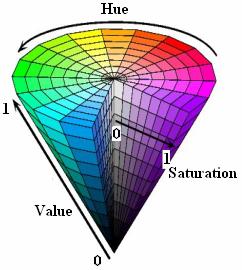
- HSV
HSV颜色空间由Hue(色调)、Saturation(饱和度)和Value(亮度)组成,与RGB类似,HSV颜色空间中也有三个分量:H、S、V。HSV颜色空间是1978年提出的,它是一种主观的颜色空间。色调通常指代颜色名称。饱和度表示掺入白光的分量,掺入白光的分量越多,则饱和度越低,即S值越小;掺入白光的分量越少,则饱和度越高,即S值越大。亮度表示掺入黑光的分量,掺入黑光的分量越多,则亮度越低,即V越小;掺入黑光的分量越少,则亮度越高,即V越大。HSV颜色空间模型:
1.4 图像种类
根据图像能呈现的色彩和灰度等级,我们可以将任何图像(物理的和数字的)图像分为彩色图像、灰度图像和二值图像。它们的区别如下:
- 二值图像
二值图像是指图像中的像素在只占1bit(位),每个像素值只能是0或1,即纯黑色和纯白色,中间没有过渡色。因此,二值图像又称为黑白图像,灰度级数为2。
- 灰度图像
灰度图像是指灰度级数大于2的图像,但它不包含彩色信息。图像中的像素通常占8bits(1字节),每个像素值范围为0~255,除纯黑色和纯白色外,中间还存在不同程度的灰色。

- 彩色图像
彩色图像是指图像中含有色彩信息的图像,在数字图像中,每一个像素都有相应的数值来表示该像素的信息,彩色图像的信息就是颜色信息。根据三基色原理,任何颜色都可以表示为三个基本颜色红、绿、蓝(RGB)按不同比例合成产生。此外,根据数字图像色彩的表示方式不同,彩色图像可由RGB、YUV、HSV等颜色空间来描述。
三基色原理:自然界所有颜色(色彩)均可通过红、绿、蓝三色按照不同的比例合成产生,同样绝大多数单色光也可以分解成红绿蓝三种色光,因此,红、绿、蓝三色被称为三基色。

1.5 数字图像基本属性
在了解图像相关属性之前,个人觉得很有必要先搞清楚什么是单色光、复合光、色彩和颜色。在三原色中,可见光的波长为380~780nm(纳米),不同波长呈现出不同的颜色,可见波长从长到短依次为红、橙、黄、绿、青、蓝、紫。红色的波长为700nm、绿色的波长为546.1nm、蓝色的波长为435.8nm。只有单一波长成分的光称为单色光,含有两种以上波长成分的光称为复合光。色彩通常都是由一种单色光和白光按照一定比例混色的,色彩的三要素:色相、明度、纯度。其中,色相又称颜色,由亮度和色度共同表示,是色彩的首要特征和区别各种不同色彩最准确的标准;明度指色彩的亮度;纯度指色彩的鲜艳程度,即饱和度。
- 色彩深度
色彩深度/颜色深度计算机图形学领域表示在位图或者视频帧缓冲区中储存1像素的颜色所用的位数,它也称为位/像素(bpp)。色彩深度越高,可用的颜色就越多,通常存储每个像素所用的位数n与可选择的颜色数量关系可表示为:颜色数量=2^n。比如二值图像中存储每个像素占1位,即颜色深度为1,可选颜色为2^1=2种(黑色、白色);灰度图像中存储每个像素占8位,即颜色深度为8,可选颜色为2^8=256种;真彩色图像(RGB颜色格式)中存储每个占24位,即颜色深度为24,可选颜色为2^24=16777216种。通常,图像的色彩深度越深,每个像素存储占用空间越大,图片就越大。
- 图像亮度
亮度指照射在景物或图像上光线的明暗程度。图像亮度增加时,就会显得耀眼或刺眼,亮度越小时,图像就会显得灰暗。如果是灰度图像,则亮度跟灰度值有关,灰度值越高则图像越亮;如果是彩色图像(RGB格式),则亮度跟R、G、B分量值有关,假设亮度为Y:Y=0.299R+0.587G+0.114B,人的主观感受是绿光最亮,红光其次,蓝光最弱。 下图展示的是不同亮度显示效果:

- 图像对比度
图像对比度所指的就是一幅图像当中明暗区域最亮的白和最暗的黑之间不同亮度层级的测量,差异范围越大代表对比度越高,差异范围越小代表对比度数值越小,好的对比率120:1就可容易地显示生动、丰富的色彩,当对比率高达300:1时,便可支持各阶的颜色。从视觉角度上来看,对比度越大图像就越清晰醒目,从而色彩也会更加鲜明艳丽。反之,对比度越小,则会让人感到画面灰蒙蒙一片,色彩丢失也会很严重。下图展示的是低、高对比度显示的效果:

- 图像色调
色调是指色调是指色彩外观的基本倾向。在明度、纯度、色相这三个要素中,某种因素起主导作有用,可以称之为某种色调。色调各种图像色彩模式下原色的明暗程度,级别范围从0到255,共256级色调。例如对灰度图像,当色调级别为255时,就是白色,当级别为0时,就是黑色,中间是各种程度不同的灰色。在RGB模式中,色调代表红、绿、蓝三种原色的明暗程度,对绿色就有淡绿、浅绿、深绿等不同的色调。

- 图像饱和度
饱和度指彩色图像颜色的浓度,或色彩的纯度。饱和度越高,颜色越饱满,表现颜色种类越多,颜色就越鲜明;饱和度越低,表现则较黯淡,当饱和度为0时,图像表现为灰度图像。

色调和饱和度合称为色度,色度表示的是色彩的纯度,用来反映颜色的色调和饱和度。
- 图像清晰度
图像清晰度,是指影像上各细部影纹及其边界的清晰程度。

2. OpenCV数据结构
2.1 基础图像容器Mat
在OpenCV2.0之前,OpenCV主要使用IpImage*在内存中存储图像,但由于IplImage基于C语言接口实现,这就需要我们在release之前手动释放开辟的内存,否则非常容易造成内存泄漏。为了尽可能避免这种内存泄漏情况,基于C++实现的Mat类便”闪亮登场”。Mat,即矩阵Matrix的缩写,它被引入于OpenCV2.0,是OpenCV在图像处理中存储图像最基本的数据结构,也可以称作是存储图像的容器。Mat类存储图像最大的优势就是内存的自动管理,即我们无需再去手动为其开辟和释放空间,并且当传递一个已经存在的Mat对象时开辟好的矩阵空间会被重用。
(1) Mat结构
Mat数据结构由两部分组成:矩阵头(Header)和一个指针(Pointer)。一个指向内存中存储所有像素值的矩形的指针,其中,Header包含矩阵的大小、存储方法和存储地址等信息;Pointer指向存储在内存中所有像素值的矩阵。Mat类部分源码如下:
class CV_EXPORTS Mat
{
public:
// 构造方法
Mat();
Mat(int rows, int cols, int type);
Mat(int rows, int cols, int type, const Scalar& s);
....
// 成员方法
Mat row(int y) const;
Mat col(int x) const;
Mat clone() const;
void copyTo( OutputArray m ) const;
static MatExpr zeros(int rows, int cols, int type);
static MatExpr eye(int rows, int cols, int type);
static MatExpr ones(int rows, int cols, int type);
void create(int rows, int cols, int type);
int depth() const;
int channels() const;
....
// 成员变量
/*! includes several bit-fields:
- the magic signature
- continuity flag
- depth
- number of channels
*/
int flags;
//! the matrix dimensionality, >= 2
int dims;
//! the number of rows and columns
//or (-1, -1) when the matrix has more than 2 dimensions
int rows, cols;
//! pointer to the data
uchar* data;
....
};关于图像副本在函数中的传递,大的开销通常是由直接拷贝(复制)图像矩阵数据所致,这对于程序的运行性能是非常不利的。为了解决该问题,OpenCV使用引用计数机制让每个Mat对象有自己的信息头,同时共享一个矩阵。也就是说,图像在函数传递中,只是传递原有Mat对象的信息头和矩阵指针而不是复制矩阵,让所有Mat对象的指针指向同一地址的矩阵。常见的实现方法:
// 仅创建信息头部分
Mat A,C;
// 加载图片到内存,系统为该矩阵开辟一段内存空间
A = imread("helloOpecv.png",CV_LOAD_IMAGE_COLOR);
// 使用构造方法拷贝A的Header和Pointer
Mat B(A);
// 使用赋值方式拷贝A的Header和Pointer
C = A;
// 以下两种方式会创建只引用部分数据的信息头
// 使用矩形界定拷贝A的ROI(感兴趣区域)
Mat D (A,Rect(10,10,100,100));
// 使用行和列来界定
Mat E = A(Range:all() , Range(1,3));从上面的代码来看,A、B、C对象均指向同一个数据矩阵,D、E对象会创建引用部分数据的信息头。当然,如果你想直接复制图像矩阵本身(不只是信息头和矩形指针),Mat类也提供相关的方法,即clone()或者copyTo,此时修改图像副本将不影响原始Mat信息头所指向的矩阵。
Mat A;
A = imread("helloOpecv.png",CV_LOAD_IMAGE_COLOR);
Mat F = A.clone();
Mat G;
A.copyTo(G);(2) Mat对象创建方法
Mat类既是一个图像容器,也是一个通用的矩阵类,通过Mat类可以用来创建和操作多维矩阵。除了上文中使用imread方法将图像数据存储到Mat矩阵中,Mat对象的创建方法有多种,这里我们只介绍下开发过程中常见的几种:
- 使用Mat()构造函数
/** Mat(int rows, int cols, int type, const Scalar& s);
* 说明:
rows、type为二维矩阵的行数和列数
type为存储元素的数据类型及每个矩阵点通道数,如CV_8UC1、CV_8UC3...
scalar为像素颜色值,也可理解为初始化矩阵的初始值
*/
Mat M(3,3,CV_8UC3,Scalar(255,0,255));
cout << "M=" << endl << " " << M << endl << endl 运行结果:

存储元素的数据类型和每个矩阵点的通道数的通用表达式为CV_[位数][带符号与否][类型前缀]C[通道数],比如CV_8UC3表示矩阵元素数据使用8位的unsigned char型,每个像素由三个元素组成的三通道。
- 使用Mat的Create()函数
/** void create(int rows, int cols, int type);
* 说明:
create方法用于创建一个新的矩阵,并为该矩阵开辟一段内存空间。
需要注意的是,create方法无法为矩阵设置初值,它默认值为205.
*/
Mat M(3, 3, CV_8UC3, Scalar(255, 0, 255));
M.create(2, 2, CV_8UC2);
cout << "M=" << endl << " " << M << endl << endl; 运行结果:

- 使用Mat的zeros()、ones()、eyes()函数
/** Mat::eye(int rows, int cols, int type)
* 说明:
创建矩阵并将矩阵初始值预设,即将row=col处元素预设为1,其他为0
Mat::ones(int rows, int cols, int type)
说明:
创建矩阵并将矩阵初始值预设,即将所有元素预设为1
Mat::zeros(int rows, int cols, int type)
说明:
创建矩阵并将矩阵初始值预设,即将所有元素预设为0
*/
Mat eyeM = Mat::eye(4,4,CV_64F);
Mat eyeO = Mat::ones(2, 2, CV_32F);
Mat eyeZ = Mat::zeros(4, 4, CV_8UC1);
cout << "eyeM=" << endl << " " << eyeM << endl << endl;
cout << "eyeO=" << endl << " " << eyeO << endl << endl;
cout << "eyeZ=" << endl << " " << eyeZ << endl << endl; 运行结果

- 对小矩阵使用逗号分隔式赋值
Mat C = (Mat_(3, 3) << 0, -1, 0, -1, 5, -1, 0, -1, 0);
cout << "C=" << endl << " " << C << endl << endl; Mat_继承于Mat,Mat_(int _rows, int _cols)等价于Mat(_rows, _cols, DataType<_Tp>::type)
- 为已存在的对象创建新信息头
// 使用clone(0)或者copyTo()为一个已存在的Mat对象创建一个新的信息头
Mat M = (Mat_<double>(3, 3) << 0, -1, 0, -1, 5, -1, 0, -1, 0);
Mat rowClone = M.row(1).clone();
cout << "M=" << endl << " " << M << endl << endl;
cout << "rowClone=" << endl << " " << rowClone << endl << endl; 运行结果:

2.2 OpenCV中常用数据结构
(1) 点的表示:Point类
Point类数据结构表示二维坐标系下的点,即由其图像坐标x和y指定的2维坐标点。用法如下:
Point point = Point(xo,yo);
// 或者
// Point point;
// point.x = xo;
// point.y = yo;除此之外,常见的还有Point2f、Point3f等,分别表示浮点型2D点和3维坐标点。通过查看OpenCV源码,实质上Point_、Point2i、Point为相互等价的整型坐标点,Point_、Point2f为互相等价的浮点型坐标点。
(2) 颜色的表示:Scalar类
Scalar类表示的是图像像素的颜色值,在OpenCV中被大量用于传递像素值。它是一个具有4个元素的数组,但一般第四个参数无需写出来。对于RGB颜色格式来说,c表示红色分量、b表示绿色分量、c表示蓝色分量,它们共同决定像素值或称像素颜色值。 Scalar类源码如下:
template<typename _Tp> class Scalar_ : public Vec<_Tp, 4>
{
public:
//! various constructors
Scalar_();
Scalar_(_Tp v0, _Tp v1, _Tp v2=0, _Tp v3=0);
Scalar_(_Tp v0);
template<typename _Tp2, int cn>
Scalar_(const Vec<_Tp2, cn>& v);
//! returns a scalar with all elements set to v0
static Scalar_<_Tp> all(_Tp v0);
//! conversion to another data type
template<typename T2> operator Scalar_() const;
//! per-element product
Scalar_<_Tp> mul(const Scalar_<_Tp>& a, double scale=1 ) const;
// returns (v0, -v1, -v2, -v3)
Scalar_<_Tp> conj() const;
// returns true iff v1 == v2 == v3 == 0
bool isReal() const;
};
typedef Scalar_<double> Scalar; 从Scalar源码可知,Scalar继承于Vec<_Tp,4>,Scalar、Scalar_是等价的。Scalar提供了Scalar_(_Tp v0, _Tp v1, _Tp v2=0, _Tp v3=0)构造方法,参数v0、v1、v2、v3数据类型为double。Scalar提供了all(_Tp v0)函数用于将所有参数赋值为v0;conj()函数用于参数取反。
(3) 尺寸的表示:Size类
Size类表示图像的尺寸或者矩阵的大小,它的使用非常简单,即Size(int w,int h),其中,w表示图像或矩阵的宽度,h表示图像或矩阵的高度。wSize类源码如下:
template<typename _Tp> class Size_
{
public:
typedef _Tp value_type;
//! various constructors
Size_();
Size_(_Tp _width, _Tp _height);
Size_(const Size_& sz);
Size_(const Point_<_Tp>& pt);
Size_& operator = (const Size_& sz);
//! the area (width*height)
_Tp area() const;
//! true if empty
bool empty() const;
//! conversion of another data type.
template<typename _Tp2> operator Size_<_Tp2>() const;
_Tp width, height; // the width and the height
};
typedef Size_<int> Size2i;
typedef Size_ Size2l;
typedef Size_<float> Size2f;
typedef Size_<double> Size2d;
typedef Size2i Size; 从Size类源码可知,Size、Size2i、Size_是等价的,构造方法中的_width、_height变量数据类型为int型,除此之外,根据_width、_height数据类型的不同,Szie类还有几个变种,即Size_和Size2l为长整型、Size_和Size2f为浮点型、Size_和Size2d为double型。Size类还提供了area()函数用来计算尺寸的面积;empty()函数判断该Size区域是否为空,即是否包含图像数据;width和height成员变量用来返回图像或矩阵的宽高。
(4) 矩形的表示:Rect类
Rect类表示一个矩形,它有x, y, width, height几个成员变量,其中,x,y表示矩形左上角的坐标,width,height表示矩形的宽和高。除此之外,Rect类还提供了area()返回矩形面积;contains(Point)判断点是否在矩形内;tl()返回左上角点坐标等函数。同Point、Size类似,Rect也使用模板方法提供了多种类型的Rect对象,比如Rect_和Rect2f表示数据类型为浮点型。Rect源码如下:
template<typename _Tp> class Rect_
{
public:
typedef _Tp value_type;
//! various constructors
Rect_();
Rect_(_Tp _x, _Tp _y, _Tp _width, _Tp _height);
Rect_(const Rect_& r);
Rect_(const Point_<_Tp>& org, const Size_<_Tp>& sz);
Rect_(const Point_<_Tp>& pt1, const Point_<_Tp>& pt2);
Rect_& operator = ( const Rect_& r );
//! the top-left corner
Point_<_Tp> tl() const;
//! the bottom-right corner
Point_<_Tp> br() const;
//! size (width, height) of the rectangle
Size_<_Tp> size() const;
//! area (width*height) of the rectangle
_Tp area() const;
//! true if empty
bool empty() const;
//! conversion to another data type
template<typename _Tp2> operator Rect_<_Tp2>() const;
//! checks whether the rectangle contains the point
bool contains(const Point_<_Tp>& pt) const;
//< the top-left corner, as well as width and
//height of the rectangle
_Tp x, y, width, height;
};
typedef Rect_<int> Rect2i;
typedef Rect_<float> Rect2f;
typedef Rect_<double> Rect2d;
typedef Rect2i Rect;2.3 图像中的像素存储与访问
(1)像素值的存储
- 灰度图像存储格式

从上图可知,灰度图像的存储格式是一个二维矩阵,由n行*m列像素组成,每个像素占1字节(8bits),取值为0(纯黑)~255(纯白)。因此,灰度图像的一个像素占1个字节,共有2^8=265种灰度色。
- 彩色图像存储格式

从上图可知,彩色图像的存储格式也是一个二维矩阵,由n行*m列像素组成,每个像素由B(蓝色)、G(绿色)、R(红色)三个通道(分量)共同决定(OpenCV默认颜色空间为BGR)。对于OpenCV来说,它会将B、G、R三个分量看成一列,其中B、G、R分量各占1字节(8bits),取值为0~255之间。因此,彩色图像的一个图像占3个字节,共有2^8x2^8x2^8=16777216种。
图像矩阵的大小取决于所用的颜色模型,因为不同的颜色模型每个像素占的通道数不一样,对于多通道图像而言,矩阵中的列会包含多个子列,其子列个数与通道数相等。
(2) 图像中的像素访问
在OpenCV中,提供了三种访问图像中(每个)像素的方法:
- 指针访问
Mat srcImage = imread("jinmao.jpg");
int rowNumber = srcImage.rows; // 行数
int colNumber = srcImage.cols; //列数
// 遍历图像所有像素
for(int i=0; i// 获取第i行的首地址,Mat类提供了ptr函数可以得到图像任意行的首地址
uchar* data = srcImage.ptr<uchar>(i);
// 遍历第i行的所有像素
for(int j=0 ; j// 开始处理每一个像素
data[j] = ...;
}
} - 迭代器iterator
使用迭代器操作像素的原理:先获得图像矩阵的begin和end,然后增加迭代至从begin到end,将*操作符添加在迭代指针前,即可访问当前指向的内容。相比用指针直接访问可能出现越界问题,迭代器是一种非常安全的方法。
Mat srcImage = imread("jinmao.jpg");
// 获取初始位置的迭代器
Mat_::iterator it = srcImage.begin();
// 获取终止位置的迭代器
Mat_::iterator itEnd = srcImage.end();
// 存取彩色图像像素
for(;it != itEnd;++it) {
// 开始处理每个像素,包含三个通道
(*it)[0] = ..; // 通道1
(*it)[1] = ..; // 通道2
(*it)[2] = ..; // 通道3
//.....
} - 动态地址计算
动态地址计算,实质上是通过Mat类的at方法直接取出像素的单通道进行计算。
Mat srcImage = imread("jinmao.jpg");
int rowNumber = srcImage.rows; // 行数
int colNumber = srcImage.cols; //列数
// 遍历图像所有像素
for(int i=0; ifor(int j=0 ; j(i,j)[0] = ...;//通道1
srcImage.at(i,j)[1] = ...;//通道2
srcImage.at(i,j)[2] = ...;//通道3
//...
}
} 2.4 颜色空间及其通道分离、合并
在数字图像基础部分中,我们较为详细地讲解了数字图像诸如RGB、YUV、HSL等常见的颜色空间,本节在此基础上介绍OpenCV中如何使用ctvColor函数进行颜色格式之间的转换,以及颜色通道的分离、合并。
(1) 颜色空间转换
对于OpenCV来说,图像默认的颜色格式为BRG,但由于开发需要,我们往往需要将其转换成灰度图像、RGB格式彩色图像或YUV格式彩色图像等,这就需要用到cvtColor函数了。cvtColor函数原型如下:
/* cvtColor函数原型:
src:输入图像;
dst:输出图像(转换后的图像);
code:图像转换的类型,比如COLOR_BGR2GRAY、COLOR_BGR2RGB等等(OpenCV3版);
dstCn:目标图像的通道数,dstCn=0表示目标图像的通道数与源图像一致
*/
void cvtColor(InputArray src, OutputArray dst, int code, int dstCn=0 ) 说明:
InputArray和OutputArray两个类都是代理数据类型,用来接收Mat和Vector<>作为输入参数,OutputArray继承自InputArray,从某些程度来说,InputArray和OutputArray可看成是Mat对象或Vector<>对象。InputArray作为输入参数的时候,传入的参数加了const限定符,即它只接收参数作为纯输入参数,无法更改输入参数的内容。而OutputArray则没有加入限定符,可以对参数的内容进行更改。
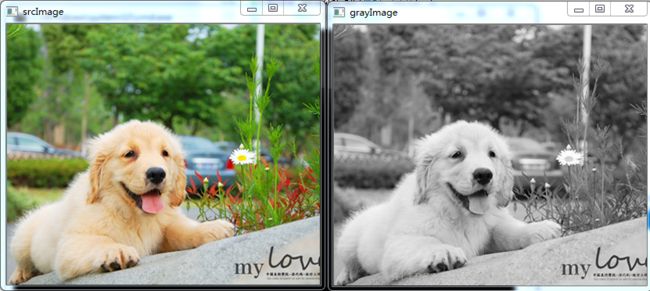
- 示例:图像灰度化(BGR->GRAY)
Mat grayImage;
Mat srcImage = imread("jinmao.jpg");
if (! srcImage.data) {
printf("open src image failed");
}
cvtColor(srcImage, grayImage, COLOR_BGR2GRAY);
namedWindow("srcImage", CV_WINDOW_AUTOSIZE);
imshow("srcImage", srcImage);
imshow("grayImage", grayImage);效果演示:
(2) 颜色通道分离与合并
在图像处理过程中,为了更好地观察图像的特征,需要对R、G、B三个颜色通道的分量进行分离或合并。为此,OpenCV为我们提供了split和merge方法,前者用于讲一个多通道数组分离成几个单通道数组/阵列;后者将多个单通道数组合并成一个多通道的数组/阵列。
- 颜色通道分离
a) 函数原型
/* split函数原型(指针模式):
src:输入被分离的多通道数组/阵列,这里传入的是多通道数组地址;
mvBegin:输出分离后的数组,mvBegin指向数组的起始地址;
*/
void split(const Mat& src,Mat *mvBegin);
/* split函数原型(vector模式):
m:输入被分离的多通道数组/阵列;
mv:输出分离后的vector容器;
*/
void split(InputArray m, OutputArrayOfArrays mv); b) 示例代码:
Mat srcImage = imread("jinmao.jpg");
Mat imageBlue, imageGreen, imageRed;
Mat mergeImage;
//定义一个Mat向量容器保存拆分后的数据
vector 效果演示:

也许你会问为什么三个单通道分量的图像都为灰度图像,而不是红色分量的图像偏红色、绿色分量偏绿色以及蓝色分量偏蓝色?这是因为指定分量被分离出来后,其他两个分量会默认取同被分离分量一样的值,根据前部分提到,当R=G=B,像素值为灰度值比如当像素的红色分量为255时BRG = (0,0,255),红色分量被分离后,像素值变为(255,255,255),变为纯白色;当像素的红色分量为125时(假设其他两个分量任意值)BRG=(b,r,125),像素值变为(125,125,125),变为灰色。也就是说,单通道分量的值越大,分离后单通道颜色像素的灰度值越大,越接近白色,反之,越接近黑色。
- 颜色通道合并
a) 函数原型
/* merge:
src:输入要被合并的vector容器数组/阵列,所有矩阵的尺寸和深度要一样;
count:输入单通道矩阵的个数;
dst:输出合并的多通道数组/阵列,矩阵的尺寸和深同输入的一样);
*/
void merge(const Mat& src,size_t count,OutputArray dst);
/* merge:
mv:输入要被合并的vector容器数组/阵列,所有矩阵的尺寸和深度要一样;
dst:输出合并的多通道数组/阵列,矩阵的尺寸和深同输入的一样;
*/
void merge(InputArrayOfArrays mv, OutputArray dst); b) 示例代码:
void mergeImage() {
Mat catImage;
vector 效果演示:

需要注意的是,示例中”blueChannelImage = channels.at(0)”是将原图的蓝色通道的引用返回给blueChannelImage,所谓“引用”,即为等价,无论修改blueChannelImage还是channels.at(0),它们共同指向的内容(矩阵)是跟着变的,这是图像处理中较为重要的技术基础。另外,例子中还提到了两个重要的概念,即ROI(感兴趣)区域和图像混合叠加。
- 感兴趣区域(ROI,region of interest)
在图像处理中,为了提供分析的精度和减少处理时间,我们往往会选择从图像中圈定一个利于目标处理的图像区域进行处理,这个区域被称之为感兴趣区域ROI。定义图像的ROI区域有两种方法,即一种为使用表示矩形区域的Rect;另一种为指定感兴趣行或列的范围。
// 方法一:使用Rect
Mat imageROI = srcImage(Rect(10, 15, catImage.cols, catImage.rows));
// 方法二:使用Range
Mat imageROI = srcImage(Range(15,15+catImage.rows),Range(10,10+catImage.cols));
//注:Range是指从起始索引到终止索引(不包括终止索引)的一连段连续序列。- 线性混合操作(图像叠加)
/**addWeighted函数原型:
InputArray类型的src1,表示需要加权的第一个数组,常常填一个Mat。
alpha,表示第一个数组的权重
src2,表示第二个数组,它需要和第一个数组拥有相同的尺寸和通道数(注意)
beta,表示第二个数组的权重值。
dst,输出的数组,它和输入的两个数组拥有相同的尺寸和通道数(注意)。
gamma,一个加到权重总和上的标量值。看下面的式子自然会理解。
dtype,输出阵列的可选深度,有默认值-1。;当两个输入数组具有相同的深度时
这个参数设置为-1(默认值),即等同于src1.depth()
*/
void addWeighted(InputArray src1, double alpha, InputArray src2,
double beta, double gamma, OutputArray dst, int dtype = -1);Github地址:visual studio2015环境,Android Studio环境