dpdk内存池rte_mempool实现
dpdk可以通过两种方式来管理内存, 一种是调用rte_malloc, 在大页内存上申请空间; 另一种是使用内存池,也是通过在大页内存上申请空间方式。 两种有什么区别呢?虽然两者最终都是在大页内存上获取空间,但内存池这种方式直接在大页内存上获取,绕开了rte_malloc调用。rte_malloc一般用于申请小的内存空间。通常在需要非常大的缓冲区时,在大页内存上一次性申请一个大的缓冲区, 当做内存池,从而提高性能。
一、内存池的使用
内存池的使用非常简单,直接调用三个接口就好了。应用程序可以调用rte_mempool_create创建一个内存池; 调用rte_mempool_get从内存池中获取内存空间; 调用rte_mempool_put将不再使用的内存空间放回到内存池中。
以一个例子来说明: l2fwd二层转发时,通过rte_mempool_create创建了一个内存池,内存池中有NB_MBUF个元素。内存池创建好后,都会调用rte_pktmbuf_init初始化每一个元素。
l2fwd_pktmbuf_pool = rte_mempool_create("mbuf_pool", NB_MBUF, MBUF_SIZE, 32,
sizeof(struct rte_pktmbuf_pool_private),
rte_pktmbuf_pool_init, NULL,
rte_pktmbuf_init, NULL,rte_socket_id(), 0);在eth_igb_rx_init接口初始化网卡接收队列时,会调用igb_alloc_rx_queue_mbufs接口从内存池中获取多个对象元素,用于存放从网卡直接发来的报文。这个接口内部最终会调用rte_mempool_get从内存池中获取内存空间
static int igb_alloc_rx_queue_mbufs(struct igb_rx_queue *rxq)
{
for (i = 0; i < rxq->nb_rx_desc; i++)
{
volatile union e1000_adv_rx_desc *rxd;
//rte_rxmbuf_alloc就是从内存池中获取一个mbuf元素,里面会调用rte_mempool_get
struct rte_mbuf *mbuf = rte_rxmbuf_alloc(rxq->mb_pool);
dma_addr = rte_cpu_to_le_64(RTE_MBUF_DATA_DMA_ADDR_DEFAULT(mbuf));
//dma地址之间指向这个mbuf, 相当于告诉网卡,收到报文后之间放到这个mbuf中。
rxd = &rxq->rx_ring[i];
rxd->read.hdr_addr = dma_addr;
rxd->read.pkt_addr = dma_addr;
rxe[i].mbuf = mbuf;
}
}
当mbuf不在使用了,那就需要释放他所占用的内存空间,rte_pktmbuf_free接口用于释放一个mbuf空间,内部最终调用rte_mempool_put将已经申请的空间放回到内存池中,相当于回收以便这个空间后续可以被使用。
void rte_pktmbuf_free(struct rte_mbuf *m)
{
//内存回收,将不再使用的对象重新放回到内存池
rte_mempool_put(m->pool, m);
}二、内存池的实现
1、内存池的创建
内存池的创建,在rte_mempool_create接口中完成。这个接口主要是创建下面这样一种结构。在大页内存中开辟一个连续的大缓冲区当做内存池。将这个内存池进行分割,头部为struct rte_mempool内存池结构; 紧接着是内存池的私有结构大小,这个由应用层自己设置,每个创建内存池的应用进程都可以指定不同的私有结构; 最后是多个连续的对象元素,这些对象元素都是处于同一个内存池中。每个对象元素又有对象的头部,对象的真实数据区域,对象的尾部组成。这里所说的对象元素,其实就是应用层要开辟的真实数据空间,例如应用层自己定义的结构体变量等
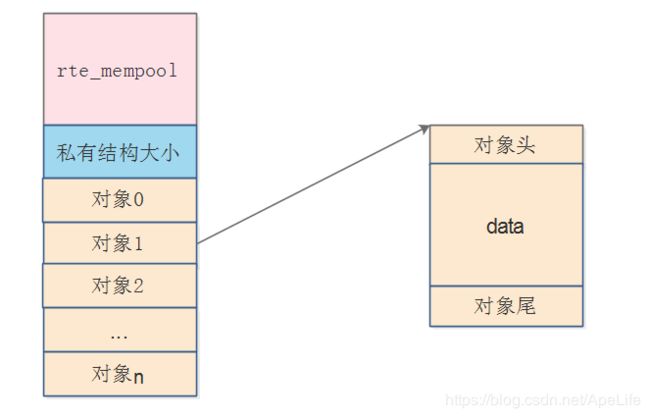
知道了创建共享内存主要维护的数据结构,接下里分析代码的实现就简单了。
首先统计每一个对象元素的的大小,包括对象的头部,对象的真实数据区域,对象的尾部所占的空间;仅接着统计这个内存池的总大小,由内存池头部、私有结构以及所有对象空间组成。
//计算每一个对象元素的大小
rte_mempool_calc_obj_size(elt_size, flags, &objsz);
//统计内存池头部的大小
mempool_size = MEMPOOL_HEADER_SIZE(mp, pg_num) + private_data_size;
//计算整个内存池的总大小,包括内存池头部与所有的对象元素
mempool_size += (size_t)objsz.total_size * n;r = rte_ring_create(rg_name, rte_align32pow2(n+1), socket_id, rg_flags);接着从大页内存中直接获取一个足够大的缓冲区,当做内存池使用,并给内存池头部结构struct rte_mempool赋值。此时内存池头部,私有结构,以及每个对象元素都在同一个缓冲区中,属于同一个内存池。内存池创建好后,会通过遍历的方式对内存池中的每一个对象元素进行初始化。初始化的逻辑等会在分析,先看整体流程。
//从内存区中直接获取一个足够大的内存区,存放内存池
mz = rte_memzone_reserve(mz_name, mempool_size, socket_id, mz_flags);
//给内存池结构赋值
mp = startaddr;
memset(mp, 0, sizeof(*mp));
snprintf(mp->name, sizeof(mp->name), "%s", name);
mp->phys_addr = mz->phys_addr;
//例如rte_pktmbuf_init
//遍历每个内存池中的元素,进行初始化
mempool_populate(mp, n, 1, obj_init, obj_init_arg);将内存池插入到内存池链表中。每创建一个内存池,都会创建一个链表节点,然后插入到链表中。因此这个链表记录着当前系统创建了多少内存池。
//创建内存池链表节点
te = rte_zmalloc("MEMPOOL_TAILQ_ENTRY", sizeof(*te), 0);
//内存池链表节点插入到内存池链表中
te->data = (void *) mp;
RTE_EAL_TAILQ_INSERT_TAIL(RTE_TAILQ_MEMPOOL, rte_mempool_list, te);现在来看每一个元素的初始化,在rte_mempool_create创建共享内存池,还会创建一个ring。这个ring队列有什么用呢?这是用来管理内存池中的每个对象元素的,记录内存池中哪些对象使用了,哪些对象没有被使用。当初始化好一个对象元素后,会将这个对象元素放到这个ring队列中,在所有元素都初始化完成后,此时ring队列存放了内存池上所有的对象元素。需要注意的是ring队列存放的是对象元素的指针而已,而不是对象元素本身的拷贝。应用程序要申请内存时,调用rte_mempool_get,最终是从这个ring队列中获取元素的; 应用程序调用rte_mempool_put将内存回收时,也是将要回收的内存空间放到这个ring队列中。因此内存池与ring队列相互关联起来。
r = rte_ring_create(rg_name, rte_align32pow2(n+1), socket_id, rg_flags);static void mempool_add_elem(...)
{
//例如rte_pktmbuf_init
//内存池上的某个对象元素初始化
if (obj_init)
{
obj_init(mp, obj_init_arg, obj, obj_idx);
}
//将初始化完成的对象元素入队
rte_ring_sp_enqueue(mp->ring, obj);
}此时内存池结构,ring队列就关联起来了。来看下这两者之间的关联结构。

2、内存的申请
在创建好内存池后,当应用程序需要从内存池中获取一个对象元素的空间时,可以调用rte_mempool_get从内存池中获取一个元素空间。优先从每个cpu本身的缓存中查找是否有空闲的对象元素,如果有就从cpu本地缓存中获取;如果cpu本地缓存没有空闲的对象元素,则从ring队列中取出一个对象元素。这里所说的cpu本地缓存并不是cpu硬件上的cache, 而是应用层为每个cpu准备的缓存。之所以要维护一个cpu本地缓存是为了尽量减少多个cpu同时访问内存池上的元素,减少竞争的发生。
int rte_mempool_get(struct rte_mempool *mp, void **obj_table, unsigned n)
{
#if RTE_MEMPOOL_CACHE_MAX_SIZE > 0
//从当前cpu应用层缓冲区中获取
cache = &mp->local_cache[lcore_id];
cache_objs = cache->objs;
for (index = 0, len = cache->len - 1; index < n; ++index, len--, obj_table++)
{
*obj_table = cache_objs[len];
}
return 0;
#endif
/* get remaining objects from ring */
//直接从ring队列中获取
ret = rte_ring_sc_dequeue_bulk(mp->ring, obj_table, n);
}3、内存的释放
当应用层已经不在需要使用某个内存时,需要将他进行回收,以免造成内存泄漏,进而导致内存池没有空间了,其他应用程序无法在获取内存空间。可以调用rte_mempool_put将不再使用的内存放回到内存池中。 首先也是查看cpu本地缓存是否还有空间,如果有则优先把元素放到cpu本地缓存;如果没有则将要释放的对象元素放回到ring队列中。来看下这个接口的实现。
int rte_mempool_put(struct rte_mempool *mp, void **obj_table, unsigned n)
{
#if RTE_MEMPOOL_CACHE_MAX_SIZE > 0
//在当前cpu本地缓存有空间的场景下, 先放回到本地缓存。
cache = &mp->local_cache[lcore_id];
cache_objs = &cache->objs[cache->len];
for (index = 0; index < n; ++index, obj_table++)
{
cache_objs[index] = *obj_table;
}
//缓冲达到阈值,刷到队列中
if (cache->len >= flushthresh)
{
rte_ring_mp_enqueue_bulk(mp->ring, &cache->objs[cache_size], cache->len - cache_size);
cache->len = cache_size;
}
return 0
#endif
//直接放回到ring队列
rte_ring_sp_enqueue_bulk(mp->ring, obj_table, n);
}到此为止内存池的实现就已经分析完成了, 内存池也是dpdk报文能够高速转发,零拷贝的基础。