系统学习深度学习(三十一)--Nature DQN(NIPS 2015)
转自:https://www.cnblogs.com/pinard/p/9756075.html
1. DQN(NIPS 2013)的问题
在上一篇我们已经讨论了DQN(NIPS 2013)的算法原理和代码实现,虽然它可以训练像CartPole这样的简单游戏,但是有很多问题。这里我们先讨论第一个问题。
注意到DQN(NIPS 2013)里面,我们使用的目标Q值的计算方式:
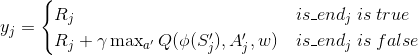
这里目标Q值的计算使用到了当前要训练的Q网络参数来计算Q(ϕ(S′j),A′j,w),而实际上,我们又希望通过yj来后续更新Q网络参数。这样两者循环依赖,迭代起来两者的相关性就太强了。不利于算法的收敛。
因此,一个改进版的DQN: Nature DQN尝试用两个Q网络来减少目标Q值计算和要更新Q网络参数之间的依赖关系。下面我们来看看Nature DQN是怎么做的。
2. Nature DQN的建模
Nature DQN使用了两个Q网络,一个当前Q网络Q用来选择动作,更新模型参数,另一个目标Q网络Q′用于计算目标Q值。目标Q网络的网络参数不需要迭代更新,而是每隔一段时间从当前Q网络QQ复制过来,即延时更新,这样可以减少目标Q值和当前的Q值相关性。
要注意的是,两个Q网络的结构是一模一样的。这样才可以复制网络参数。
Nature DQN和上一篇的DQN相比,除了用一个新的相同结构的目标Q网络来计算目标Q值以外,其余部分基本是完全相同的。
3. Nature DQN的算法流程
下面我们来总结下Nature DQN的算法流程, 基于DQN NIPS 2015:
算法输入:迭代轮数T,状态特征维度n, 动作集A, 步长α,衰减因子γ, 探索率ϵ, 当前Q网络Q,目标Q网络Q′, 批量梯度下降的样本数m,目标Q网络参数更新频率C。
输出:Q网络参数
1. 随机初始化所有的状态和动作对应的价值Q. 随机初始化当前Q网络的所有参数w,初始化目标Q网络Q′的参数w′=w。清空经验回放的集合D。
2. for i from 1 to T,进行迭代。
a) 初始化S为当前状态序列的第一个状态, 拿到其特征向量ϕ(S)
b) 在Q网络中使用ϕ(S)作为输入,得到Q网络的所有动作对应的Q值输出。用ϵ−贪婪法在当前Q值输出中选择对应的动作A
c) 在状态S执行当前动作A,得到新状态S′对应的特征向量ϕ(S′)和奖励R$,是否终止状态is_end
d) 将{ϕ(S),A,R,ϕ(S′),is_end}这个五元组存入经验回放集合D
e) S=S′
f) 从经验回放集合D中采样m个样本{ϕ(Sj),Aj,Rj,ϕ(S′j),is_endj},j=1,2.,,,m,计算当前目标Q值yj:

g) 使用均方差损失函数 ,通过神经网络的梯度反向传播来更新Q网络的所有参数ww
,通过神经网络的梯度反向传播来更新Q网络的所有参数ww
h) 如果T%C=1,则更新目标Q网络参数w′=w
i) 如果S′是终止状态,当前轮迭代完毕,否则转到步骤b)
注意,上述第二步的f步和g步的Q值计算也都需要通过Q网络计算得到。另外,实际应用中,为了算法较好的收敛,探索率ϵ需要随着迭代的进行而变小。
4. Nature DQN算法实例
下面我们用一个具体的例子来演示DQN的应用。仍然使用了OpenAI Gym中的CartPole-v0游戏来作为我们算法应用。CartPole-v0游戏的介绍参见这里。它比较简单,基本要求就是控制下面的cart移动使连接在上面的pole保持垂直不倒。这个任务只有两个离散动作,要么向左用力,要么向右用力。而state状态就是这个cart的位置和速度, pole的角度和角速度,4维的特征。坚持到200分的奖励则为过关。
完整的代码参见我的github: https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/nature_dqn.py
这里我们重点关注Nature DQN和上一节的NIPS 2013 DQN的代码的不同之处。
首先是Q网络,上一篇的DQN是一个三层的神经网络,而这里我们有两个一样的三层神经网络,一个是当前Q网络,一个是目标Q网络,网络的定义部分如下:
def create_Q_network(self):
# input layer
self.state_input = tf.placeholder("float", [None, self.state_dim])
# network weights
with tf.variable_scope('current_net'):
W1 = self.weight_variable([self.state_dim,20])
b1 = self.bias_variable([20])
W2 = self.weight_variable([20,self.action_dim])
b2 = self.bias_variable([self.action_dim])
# hidden layers
h_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1)
# Q Value layer
self.Q_value = tf.matmul(h_layer,W2) + b2
with tf.variable_scope('target_net'):
W1t = self.weight_variable([self.state_dim,20])
b1t = self.bias_variable([20])
W2t = self.weight_variable([20,self.action_dim])
b2t = self.bias_variable([self.action_dim])
# hidden layers
h_layer_t = tf.nn.relu(tf.matmul(self.state_input,W1t) + b1t)
# Q Value layer
self.target_Q_value = tf.matmul(h_layer,W2t) + b2t对于定期将目标Q网络的参数更新的代码如下面两部分:
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='current_net')
with tf.variable_scope('soft_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)] def update_target_q_network(self, episode):
# update target Q netowrk
if episode % REPLACE_TARGET_FREQ == 0:
self.session.run(self.target_replace_op)
#print('episode '+str(episode) +', target Q network params replaced!')此外,注意下我们计算目标Q值的部分,这里使用的目标Q网络的参数,而不是当前Q网络的参数:
# Step 2: calculate y
y_batch = []
Q_value_batch = self.target_Q_value.eval(feed_dict={self.state_input:next_state_batch})
for i in range(0,BATCH_SIZE):
done = minibatch[i][4]
if done:
y_batch.append(reward_batch[i])
else :
y_batch.append(reward_batch[i] + GAMMA * np.max(Q_value_batch[i]))其余部分基本和上一篇DQN的代码相同。这里给出我跑的某一次的结果:
episode: 0 Evaluation Average Reward: 9.8
episode: 100 Evaluation Average Reward: 9.8
episode: 200 Evaluation Average Reward: 9.6
episode: 300 Evaluation Average Reward: 10.0
episode: 400 Evaluation Average Reward: 34.8
episode: 500 Evaluation Average Reward: 177.4
episode: 600 Evaluation Average Reward: 200.0
episode: 700 Evaluation Average Reward: 200.0
episode: 800 Evaluation Average Reward: 200.0
episode: 900 Evaluation Average Reward: 198.4
episode: 1000 Evaluation Average Reward: 200.0
episode: 1100 Evaluation Average Reward: 193.2
episode: 1200 Evaluation Average Reward: 200.0
episode: 1300 Evaluation Average Reward: 200.0
episode: 1400 Evaluation Average Reward: 200.0
episode: 1500 Evaluation Average Reward: 200.0
episode: 1600 Evaluation Average Reward: 200.0
episode: 1700 Evaluation Average Reward: 200.0
episode: 1800 Evaluation Average Reward: 200.0
episode: 1900 Evaluation Average Reward: 200.0
episode: 2000 Evaluation Average Reward: 200.0
episode: 2100 Evaluation Average Reward: 200.0
episode: 2200 Evaluation Average Reward: 200.0
episode: 2300 Evaluation Average Reward: 200.0
episode: 2400 Evaluation Average Reward: 200.0
episode: 2500 Evaluation Average Reward: 200.0
episode: 2600 Evaluation Average Reward: 200.0
episode: 2700 Evaluation Average Reward: 200.0
episode: 2800 Evaluation Average Reward: 200.0
episode: 2900 Evaluation Average Reward: 200.0
注意,由于DQN不保证稳定的收敛,所以每次跑的结果会不同,如果你跑的结果后面仍然收敛的不好,可以把代码多跑几次,选择一个最好的训练结果。
5. Nature DQN总结
Nature DQN对DQN NIPS 2013做了相关性方面的改进,这个改进虽然不错,但是仍然没有解决DQN的 很多问题,比如:
1) 目标Q值的计算是否准确?全部通过max Q来计算有没有问题?
2) 随机采样的方法好吗?按道理不同样本的重要性是不一样的。
3) Q值代表状态,动作的价值,那么单独动作价值的评估会不会更准确?
第一个问题对应的改进是Double DQN, 第二个问题的改进是Prioritised Replay DQN,第三个问题的改进是Dueling DQN,这三个DQN的改进版我们在下一篇来讨论。