YOLOv3 mxne源码解析及算法讲解
YOLOv3 mxne源码解析及算法讲解
- 前言
- 优势及创新点
- backbone darknet53网络介绍
- anchor聚类
- target 监督信息
前言
在RCNN系列算法以检测精度闻名于世时,YOLO系列检测算法另辟蹊径,以其超快的速度横空出世,YOLOv2和YOLOv3系列进一步刷新了该算法的速度和检测精度,接下来本文将结合mxnet的代码讲解YOLOv3的算法。作者是将YOLOv3作为Tech Report挂在了arxiv上,并没有发表在任何一个会议或者期刊上。YOLOv3以其超高的速度以及超强的开源代码成为工业界中目标检测的主流算法。
论文名称: YOLOv3: An Incremental Improvement
论文链接:arxiv
mxnet代码: Train YOLOv3 Predict with YOLOv3
优势及创新点
1、提出了更深的网络结构darknet53,该结构包含残差模块,性能有了大幅提升,速度仍然很快;
2、针对物体重叠,以及目标可能存在多标签的情况,使用多个Sigmoid代替softmax;
3、沿用YOLOv2用聚类计算anchor的方法,anchor数目设为9;
4、结合了SSD多尺度特征的思想
backbone darknet53网络介绍
相比YOLOv2,作者通过添加残差的结构使得darknet网络结构进一步加深,结合SSD多尺度的思想,YOLOv3在三个不同尺度上提取特征,通过将深层特征上采样与浅层特征大小一致,然后将两层特征进行级联生成新的特征,该特征融合了深层特征中的信息,包含更多的语义信息,网络结构如下图所示:
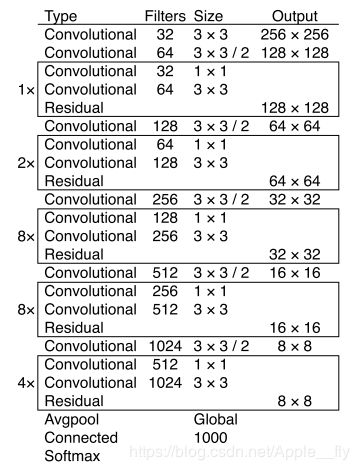
darknet53网络结构会使得最后一层特征尺寸是原图的1/32,作者在数据增强时考虑了不同的输入尺寸,每一次训练输入的图像大小是不固定的,再一次从输入层面上处理目标大小不一的问题。
anchor聚类
在YOLOv2中作者提出了anchor聚类的方法,在v2中综合考虑速度和精度,选择anchor聚类数为5,在YOLOv3中,anchor聚类数为9,COCO数据集聚类得到的anchor分别为(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326),如果使用不同的数据集,需要重新根据数据集的标注信息计算聚类的anchor长宽信息,YOLOv3在每个尺度上预测3个anchor,如果输入图像大小为416×416,则三个尺度的特征大小分别为:13×13、26×26、52×52,则最小的特征13×13分配的三个anchor尺寸为(116×90),(156×198),(373×326),26×26分配的三个anchor尺寸为(30×61),(62×45),(59×119),52×52分配的三个anchor尺寸为(10×13),(16×30),(33×23),深层的特征对应较小的特征图以及较大的感受野,所以较小的特征图分配较大的anchor尺寸,容易检出大目标。
target 监督信息
检测网络的annotation是bounding box标注,即在每个图像中标注目标的左上角和右下角的坐标及类别信息,在YOLOv3中对标注信息进行一定转换,使得预测得到的每个anchor都有对应的groundtruth(gt)。首先将左上角和右下角的标注信息(xmin,ymin,xmax,ymax)转换为中心点和长宽的标注信息(gtx,gty,gtw,gth),mxnet中转换函数为BBoxCornerToCenter,然后将所有gt和anchor转换为以原点对称的,即gt转为(-0.5×gtw,-0.5×gth,0.5×gtw,0.5×gth),计算gt和anchor的IOU,IOU值最大的anchor就要负责预测这个gt,然后计算gt在该尺度上的中心点值,直接按照尺度变换计算即可,可以得到gt在该特征图上的标注信息,作者采用相对坐标信息来作为gt,将中心点坐标转换为其相对最近左上角的坐标信息,比如原来坐标为(6.3,9.2),转换后的坐标为(0.3,0.2),高和宽转换为其对应的log信息即log(gtw/anchor_w),对于网络预测得到的中心点坐标及尺寸信息,进行相应的逆变换得到最终输出的bbox。如下图所示:
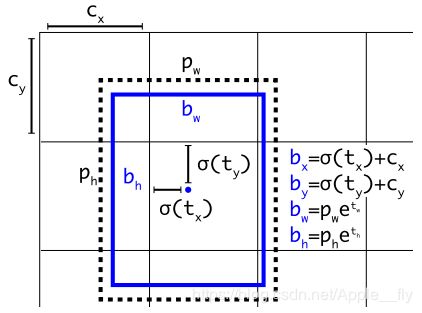
对于COCO数据集最后一个stage的网络输出为B×13×13×(3×(80+1+4)B为batchsize,13×13为特征图大小,特征图上每一个点都会预测3个候选框,每一个候选框需要预测类别信息(80)以及位置信息(4)以及是否是目标的confidence(1),针对每一幅图像,网络会预测(13×13+26×26+52×52)×3个bbox,选择与groundtruth IOU最大的一个作为正例,将IOU大于0.7但不是IOU最大的所有bbox忽略,不计算其loss,小于0.7所有anchor作为反例。如果预测的bbox不是正例,则不计算其坐标loss以及不进行类别预测,只进行objectness loss 计算(判断是否是目标)作者在类别预测中考虑multilabel情况采用binary cross-entropy loss